 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning based on Transformed Image Reconstruction for Equivariance-Coherent Feature Representation
Mar 24, 2025The equivariant behaviour of features is essential in many computer vision tasks, yet popular self-supervised learning (SSL) methods tend to constrain equivariance by design. We propose a self-supervised learning approach where the system learns transformations independently by reconstructing images that have undergone previously unseen transformations. Specifically, the model is tasked to reconstruct intermediate transformed images, e.g. translated or rotated images, without prior knowledge of these transformations. This auxiliary task encourages the model to develop equivariance-coherent features without relying on predefined transformation rules. To this end, we apply transformations to the input image, generating an image pair, and then split the extracted features into two sets per image. One set is used with a usual SSL loss encouraging invariance, the other with our loss based on the auxiliary task to reconstruct the intermediate transformed images. Our loss and the SSL loss are linearly combined with weighted terms. Evaluating on synthetic tasks with natural images, our proposed method strongly outperforms all competitors, regardless of whether they are designed to learn equivariance. Furthermore, when trained alongside augmentation-based methods as the invariance tasks, such as iBOT or DINOv2, we successfully learn a balanced combination of invariant and equivariant features. Our approach performs strong on a rich set of realistic computer vision downstream tasks, almost always improving over all baselines.
Equivariant Representation Learning for Augmentation-based Self-Supervised Learning via Image Reconstruction
Dec 04, 2024



Augmentation-based self-supervised learning methods have shown remarkable success in self-supervised visual representation learning, excelling in learning invariant features but often neglecting equivariant ones. This limitation reduces the generalizability of foundation models, particularly for downstream tasks requiring equivariance. We propose integrating an image reconstruction task as an auxiliary component in augmentation-based self-supervised learning algorithms to facilitate equivariant feature learning without additional parameters. Our method implements a cross-attention mechanism to blend features learned from two augmented views, subsequently reconstructing one of them. This approach is adaptable to various datasets and augmented-pair based learning methods. We evaluate its effectiveness on learning equivariant features through multiple linear regression tasks and downstream applications on both artificial (3DIEBench) and natural (ImageNet) datasets. Results consistently demonstrate significant improvements over standard augmentation-based self-supervised learning methods and state-of-the-art approaches, particularly excelling in scenarios involving combined augmentations. Our method enhances the learning of both invariant and equivariant features, leading to more robust and generalizable visual representations for computer vision tasks.
HeAT -- a Distributed and GPU-accelerated Tensor Framework for Data Analytics
Jul 27, 2020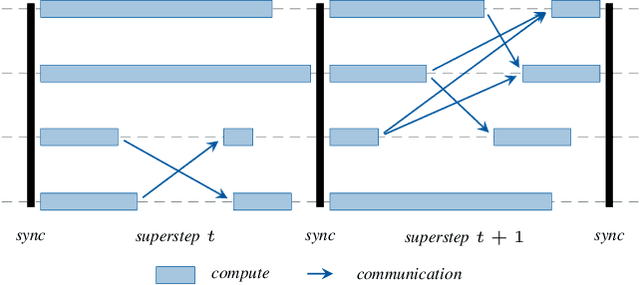
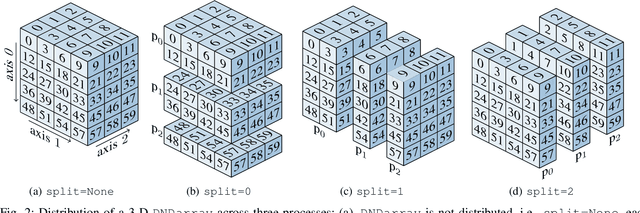
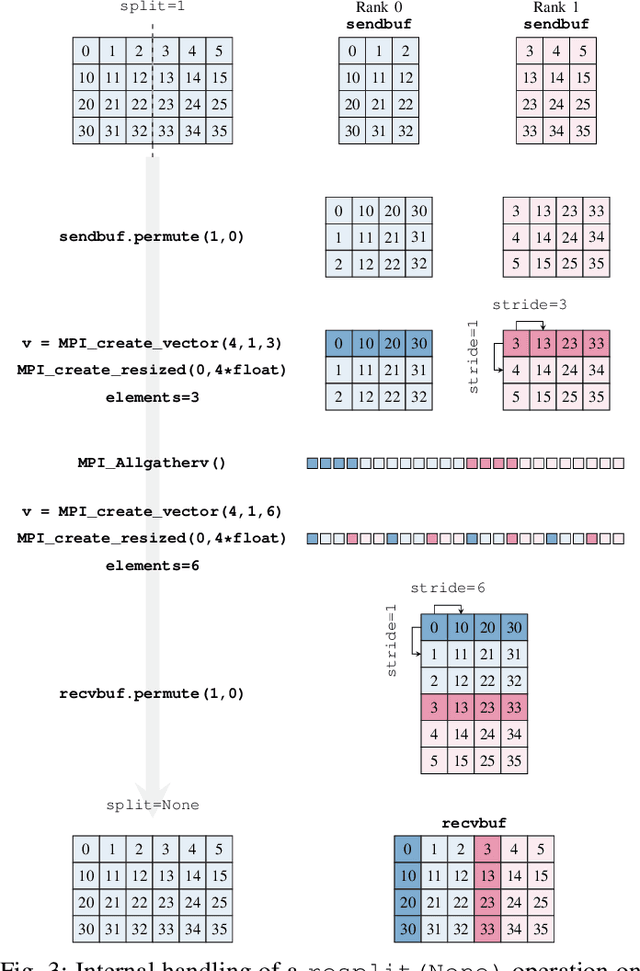

In order to cope with the exponential growth in available data, the efficiency of data analysis and machine learning libraries have recently received increased attention. Although corresponding array-based numerical kernels have been significantly improved, most are limited by the resources available on a single computational node. Consequently, kernels must exploit distributed resources, e.g., distributed memory architectures. To this end, we introduce HeAT, an array-based numerical programming framework for large-scale parallel processing with an easy-to-use NumPy-like API. HeAT utilizes PyTorch as a node-local eager execution engine and distributes the workload via MPI on arbitrarily large high-performance computing systems. It provides both low-level array-based computations, as well as assorted higher-level algorithms. With HeAT, it is possible for a NumPy user to take advantage of their available resources, significantly lowering the barrier to distributed data analysis. Compared with applications written in similar frameworks, HeAT achieves speedups of up to two orders of magnitude.