 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Transport Flows for Offline Conservative Trajectory Refinement
Jun 08, 2026Offline reinforcement learning (RL) offers a path to policy improvement from logged data alone, using historical returns or other measurable outcomes as world feedback. A key difficulty is improving observed behavior without extrapolating beyond what the offline data supports. We propose \emph{counterfactual transport flows}, a source-conditioned trajectory refinement framework for offline decision-making guided by world feedback. Given a low-feedback candidate trajectory, we construct local preference pairs from offline data by retrieving nearby trajectories in latent trajectory space with higher task-specific feedback, and use them as weak supervision for conservative refinement. The framework learns instance-specific refinement directions: at inference time, a refinement strength parameter controls how far the candidate trajectory is transported, enabling a trade-off between preserving the original behavior and applying stronger improvement. Experiments on D4RL benchmarks, including AntMaze and MuJoCo tasks, show that our method improves behavior from historical returns as world feedback, while providing interpretable trajectory-level refinement paths.
Least but not Last: Fine-tuning Intermediate Principal Components for Better Performance-Forgetting Trade-Offs
Feb 03, 2026Low-Rank Adaptation (LoRA) methods have emerged as crucial techniques for adapting large pre-trained models to downstream tasks under computational and memory constraints. However, they face a fundamental challenge in balancing task-specific performance gains against catastrophic forgetting of pre-trained knowledge, where existing methods provide inconsistent recommendations. This paper presents a comprehensive analysis of the performance-forgetting trade-offs inherent in low-rank adaptation using principal components as initialization. Our investigation reveals that fine-tuning intermediate components leads to better balance and show more robustness to high learning rates than first (PiSSA) and last (MiLoRA) components in existing work. Building on these findings, we provide a practical approach for initialization of LoRA that offers superior trade-offs. We demonstrate in a thorough empirical study on a variety of computer vision and NLP tasks that our approach improves accuracy and reduces forgetting, also in continual learning scenarios.
Classifier Reconstruction Through Counterfactual-Aware Wasserstein Prototypes
Dec 11, 2025Counterfactual explanations provide actionable insights by identifying minimal input changes required to achieve a desired model prediction. Beyond their interpretability benefits, counterfactuals can also be leveraged for model reconstruction, where a surrogate model is trained to replicate the behavior of a target model. In this work, we demonstrate that model reconstruction can be significantly improved by recognizing that counterfactuals, which typically lie close to the decision boundary, can serve as informative though less representative samples for both classes. This is particularly beneficial in settings with limited access to labeled data. We propose a method that integrates original data samples with counterfactuals to approximate class prototypes using the Wasserstein barycenter, thereby preserving the underlying distributional structure of each class. This approach enhances the quality of the surrogate model and mitigates the issue of decision boundary shift, which commonly arises when counterfactuals are naively treated as ordinary training instances. Empirical results across multiple datasets show that our method improves fidelity between the surrogate and target models, validating its effectiveness.
FlowTIE: Flow-based Transport of Intensity Equation for Phase Gradient Estimation from 4D-STEM Data
Nov 10, 2025We introduce FlowTIE, a neural-network-based framework for phase reconstruction from 4D-Scanning Transmission Electron Microscopy (STEM) data, which integrates the Transport of Intensity Equation (TIE) with a flow-based representation of the phase gradient. This formulation allows the model to bridge data-driven learning with physics-based priors, improving robustness under dynamical scattering conditions for thick specimen. The validation on simulated datasets of crystalline materials, benchmarking to classical TIE and gradient-based optimization methods are presented. The results demonstrate that FlowTIE improves phase reconstruction accuracy, fast, and can be integrated with a thick specimen model, namely multislice method.
EAP4EMSIG -- Enhancing Event-Driven Microscopy for Microfluidic Single-Cell Analysis
Mar 30, 2025

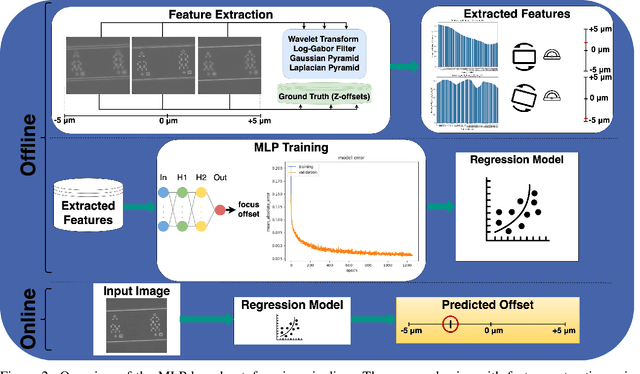

Microfluidic Live-Cell Imaging yields data on microbial cell factories. However, continuous acquisition is challenging as high-throughput experiments often lack realtime insights, delaying responses to stochastic events. We introduce three components in the Experiment Automation Pipeline for Event-Driven Microscopy to Smart Microfluidic Single-Cell Analysis: a fast, accurate Deep Learning autofocusing method predicting the focus offset, an evaluation of real-time segmentation methods and a realtime data analysis dashboard. Our autofocusing achieves a Mean Absolute Error of 0.0226\textmu m with inference times below 50~ms. Among eleven Deep Learning segmentation methods, Cellpose~3 reached a Panoptic Quality of 93.58\%, while a distance-based method is fastest (121~ms, Panoptic Quality 93.02\%). All six Deep Learning Foundation Models were unsuitable for real-time segmentation.
Efficient Epistemic Uncertainty Estimation in Cerebrovascular Segmentation
Mar 28, 2025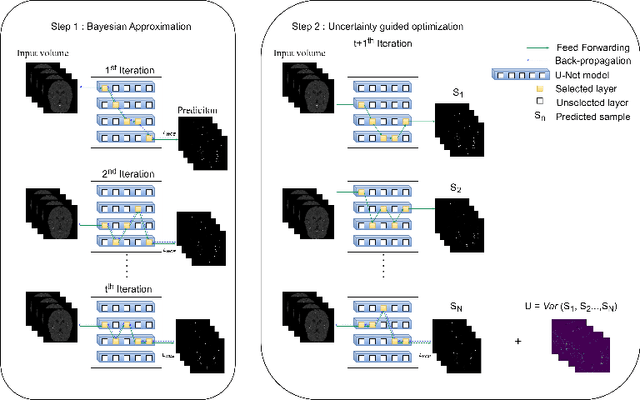

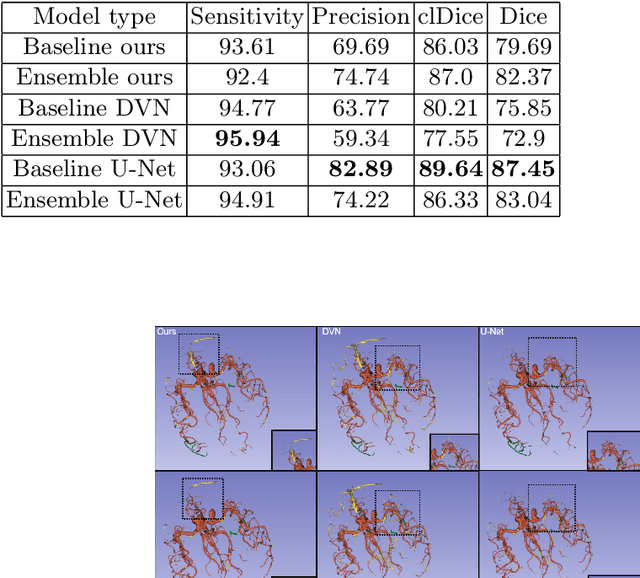

Brain vessel segmentation of MR scans is a critical step in the diagnosis of cerebrovascular diseases. Due to the fine vessel structure, manual vessel segmentation is time consuming. Therefore, automatic deep learning (DL) based segmentation techniques are intensively investigated. As conventional DL models yield a high complexity and lack an indication of decision reliability, they are often considered as not trustworthy. This work aims to increase trust in DL based models by incorporating epistemic uncertainty quantification into cerebrovascular segmentation models for the first time. By implementing an efficient ensemble model combining the advantages of Bayesian Approximation and Deep Ensembles, we aim to overcome the high computational costs of conventional probabilistic networks. Areas of high model uncertainty and erroneous predictions are aligned which demonstrates the effectiveness and reliability of the approach. We perform extensive experiments applying the ensemble model on out-of-distribution (OOD) data. We demonstrate that for OOD-images, the estimated uncertainty increases. Additionally, omitting highly uncertain areas improves the segmentation quality, both for in- and out-of-distribution data. The ensemble model explains its limitations in a reliable manner and can maintain trustworthiness also for OOD data and could be considered in clinical applications
Self-Supervised Learning based on Transformed Image Reconstruction for Equivariance-Coherent Feature Representation
Mar 24, 2025The equivariant behaviour of features is essential in many computer vision tasks, yet popular self-supervised learning (SSL) methods tend to constrain equivariance by design. We propose a self-supervised learning approach where the system learns transformations independently by reconstructing images that have undergone previously unseen transformations. Specifically, the model is tasked to reconstruct intermediate transformed images, e.g. translated or rotated images, without prior knowledge of these transformations. This auxiliary task encourages the model to develop equivariance-coherent features without relying on predefined transformation rules. To this end, we apply transformations to the input image, generating an image pair, and then split the extracted features into two sets per image. One set is used with a usual SSL loss encouraging invariance, the other with our loss based on the auxiliary task to reconstruct the intermediate transformed images. Our loss and the SSL loss are linearly combined with weighted terms. Evaluating on synthetic tasks with natural images, our proposed method strongly outperforms all competitors, regardless of whether they are designed to learn equivariance. Furthermore, when trained alongside augmentation-based methods as the invariance tasks, such as iBOT or DINOv2, we successfully learn a balanced combination of invariant and equivariant features. Our approach performs strong on a rich set of realistic computer vision downstream tasks, almost always improving over all baselines.
How To Make Your Cell Tracker Say "I dunno!"
Mar 12, 2025Cell tracking is a key computational task in live-cell microscopy, but fully automated analysis of high-throughput imaging requires reliable and, thus, uncertainty-aware data analysis tools, as the amount of data recorded within a single experiment exceeds what humans are able to overlook. We here propose and benchmark various methods to reason about and quantify uncertainty in linear assignment-based cell tracking algorithms. Our methods take inspiration from statistics and machine learning, leveraging two perspectives on the cell tracking problem explored throughout this work: Considering it as a Bayesian inference problem and as a classification problem. Our methods admit a framework-like character in that they equip any frame-to-frame tracking method with uncertainty quantification. We demonstrate this by applying it to various existing tracking algorithms including the recently presented Transformer-based trackers. We demonstrate empirically that our methods yield useful and well-calibrated tracking uncertainties.
1LoRA: Summation Compression for Very Low-Rank Adaptation
Mar 11, 2025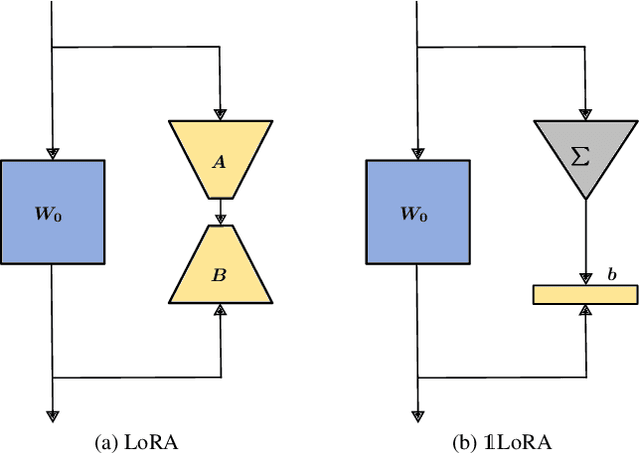
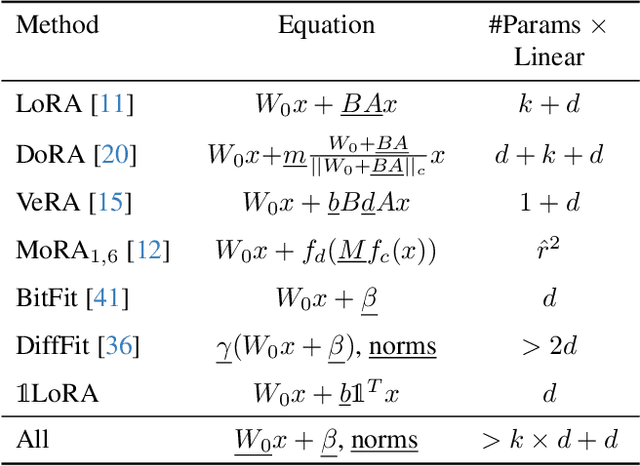
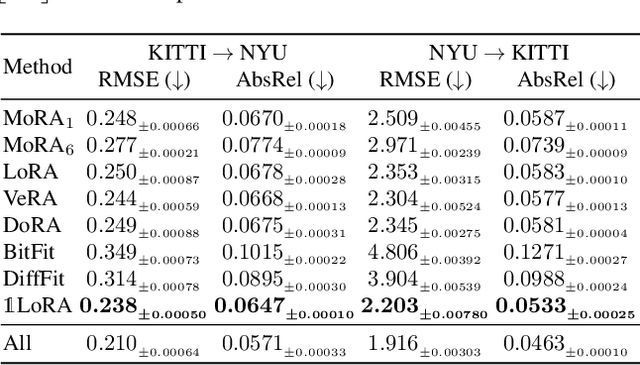
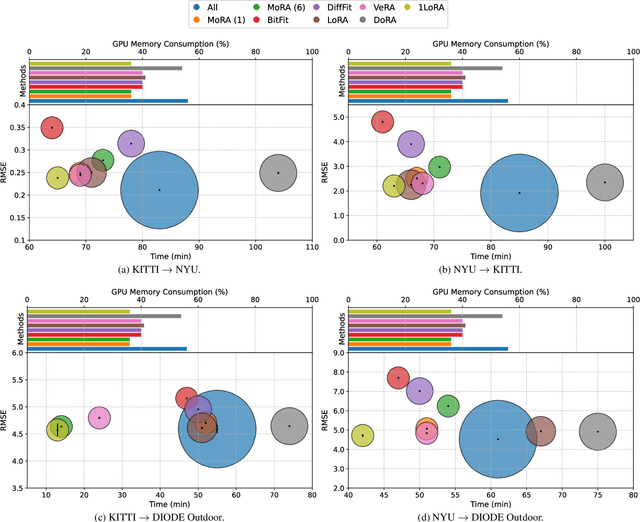
Parameter-Efficient Fine-Tuning (PEFT) methods have transformed the approach to fine-tuning large models for downstream tasks by enabling the adjustment of significantly fewer parameters than those in the original model matrices. In this work, we study the "very low rank regime", where we fine-tune the lowest amount of parameters per linear layer for each considered PEFT method. We propose 1LoRA (Summation Low-Rank Adaptation), a compute, parameter and memory efficient fine-tuning method which uses the feature sum as fixed compression and a single trainable vector as decompression. Differently from state-of-the-art PEFT methods like LoRA, VeRA, and the recent MoRA, 1LoRA uses fewer parameters per layer, reducing the memory footprint and the computational cost. We extensively evaluate our method against state-of-the-art PEFT methods on multiple fine-tuning tasks, and show that our method not only outperforms them, but is also more parameter, memory and computationally efficient. Moreover, thanks to its memory efficiency, 1LoRA allows to fine-tune more evenly across layers, instead of focusing on specific ones (e.g. attention layers), improving performance further.
MRI Reconstruction with Regularized 3D Diffusion Model (R3DM)
Dec 25, 2024Magnetic Resonance Imaging (MRI) is a powerful imaging technique widely used for visualizing structures within the human body and in other fields such as plant sciences. However, there is a demand to develop fast 3D-MRI reconstruction algorithms to show the fine structure of objects from under-sampled acquisition data, i.e., k-space data. This emphasizes the need for efficient solutions that can handle limited input while maintaining high-quality imaging. In contrast to previous methods only using 2D, we propose a 3D MRI reconstruction method that leverages a regularized 3D diffusion model combined with optimization method. By incorporating diffusion based priors, our method improves image quality, reduces noise, and enhances the overall fidelity of 3D MRI reconstructions. We conduct comprehensive experiments analysis on clinical and plant science MRI datasets. To evaluate the algorithm effectiveness for under-sampled k-space data, we also demonstrate its reconstruction performance with several undersampling patterns, as well as with in- and out-of-distribution pre-trained data. In experiments, we show that our method improves upon tested competitors.