 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSelect: Benchmark for Narrative Query-to-Agent Recommendation
Mar 04, 2026LLM agents are rapidly becoming the practical interface for task automation, yet the ecosystem lacks a principled way to choose among an exploding space of deployable configurations. Existing LLM leaderboards and tool/agent benchmarks evaluate components in isolation and remain fragmented across tasks, metrics, and candidate pools, leaving a critical research gap: there is little query-conditioned supervision for learning to recommend end-to-end agent configurations that couple a backbone model with a toolkit. We address this gap with AgentSelect, a benchmark that reframes agent selection as narrative query-to-agent recommendation over capability profiles and systematically converts heterogeneous evaluation artifacts into unified, positive-only interaction data. AgentSelectcomprises 111,179 queries, 107,721 deployable agents, and 251,103 interaction records aggregated from 40+ sources, spanning LLM-only, toolkit-only, and compositional agents. Our analyses reveal a regime shift from dense head reuse to long-tail, near one-off supervision, where popularity-based CF/GNN methods become fragile and content-aware capability matching is essential. We further show that Part~III synthesized compositional interactions are learnable, induce capability-sensitive behavior under controlled counterfactual edits, and improve coverage over realistic compositions; models trained on AgentSelect also transfer to a public agent marketplace (MuleRun), yielding consistent gains on an unseen catalog. Overall, AgentSelect provides the first unified data and evaluation infrastructure for agent recommendation, which establishes a reproducible foundation to study and accelerate the emerging agent ecosystem.
Classifier Reconstruction Through Counterfactual-Aware Wasserstein Prototypes
Dec 11, 2025Counterfactual explanations provide actionable insights by identifying minimal input changes required to achieve a desired model prediction. Beyond their interpretability benefits, counterfactuals can also be leveraged for model reconstruction, where a surrogate model is trained to replicate the behavior of a target model. In this work, we demonstrate that model reconstruction can be significantly improved by recognizing that counterfactuals, which typically lie close to the decision boundary, can serve as informative though less representative samples for both classes. This is particularly beneficial in settings with limited access to labeled data. We propose a method that integrates original data samples with counterfactuals to approximate class prototypes using the Wasserstein barycenter, thereby preserving the underlying distributional structure of each class. This approach enhances the quality of the surrogate model and mitigates the issue of decision boundary shift, which commonly arises when counterfactuals are naively treated as ordinary training instances. Empirical results across multiple datasets show that our method improves fidelity between the surrogate and target models, validating its effectiveness.
sam-llm: interpretable lane change trajectoryprediction via parametric finetuning
Sep 03, 2025This work introduces SAM-LLM, a novel hybrid architecture that bridges the gap between the contextual reasoning of Large Language Models (LLMs) and the physical precision of kinematic lane change models for autonomous driving. The system is designed for interpretable lane change trajectory prediction by finetuning an LLM to output the core physical parameters of a trajectory model instead of raw coordinates. For lane-keeping scenarios, the model predicts discrete coordinates, but for lane change maneuvers, it generates the parameters for an enhanced Sinusoidal Acceleration Model (SAM), including lateral displacement, maneuver duration, initial lateral velocity, and longitudinal velocity change. This parametric approach yields a complete, continuous, and physically plausible trajectory model that is inherently interpretable and computationally efficient, achieving an 80% reduction in output size compared to coordinate-based methods. The SAM-LLM achieves a state-of-the-art overall intention prediction accuracy of 98.73%, demonstrating performance equivalent to traditional LLM predictors while offering significant advantages in explainability and resource efficiency.
1LoRA: Summation Compression for Very Low-Rank Adaptation
Mar 11, 2025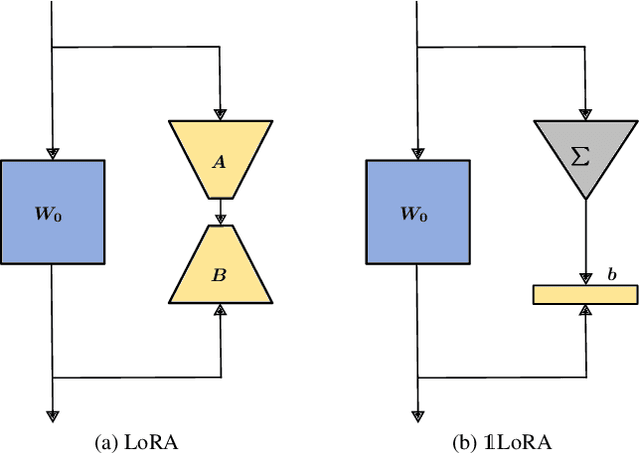
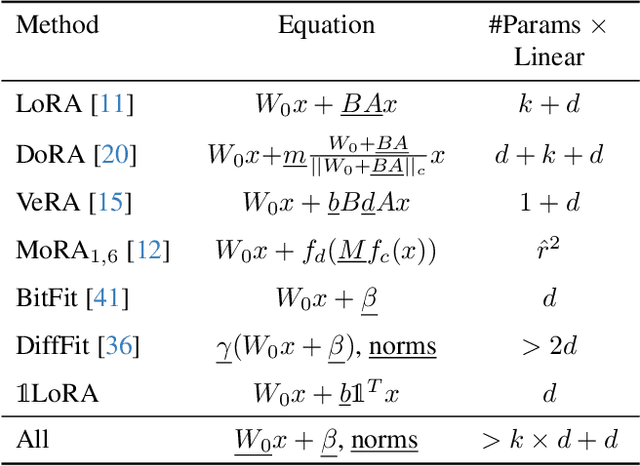
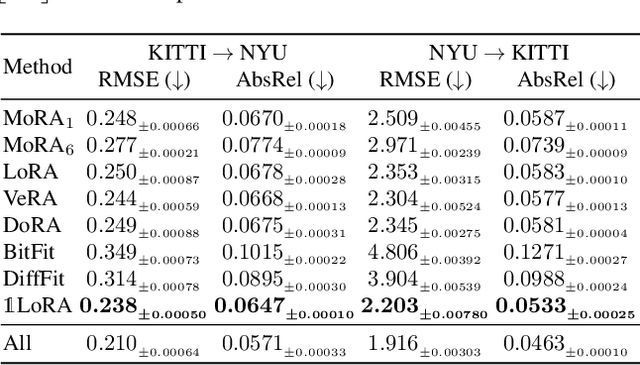
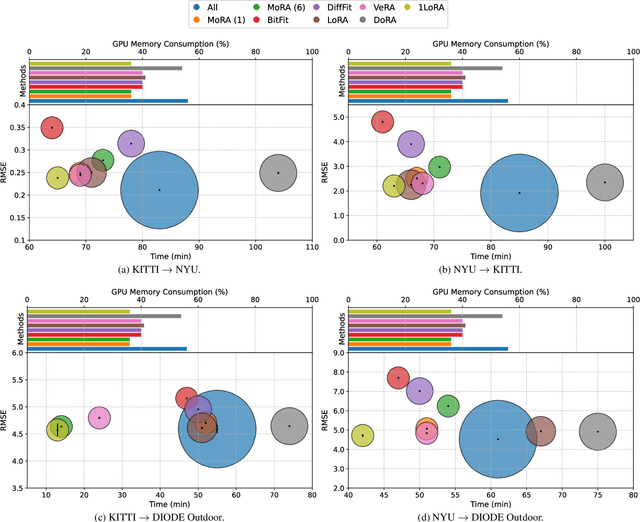
Parameter-Efficient Fine-Tuning (PEFT) methods have transformed the approach to fine-tuning large models for downstream tasks by enabling the adjustment of significantly fewer parameters than those in the original model matrices. In this work, we study the "very low rank regime", where we fine-tune the lowest amount of parameters per linear layer for each considered PEFT method. We propose 1LoRA (Summation Low-Rank Adaptation), a compute, parameter and memory efficient fine-tuning method which uses the feature sum as fixed compression and a single trainable vector as decompression. Differently from state-of-the-art PEFT methods like LoRA, VeRA, and the recent MoRA, 1LoRA uses fewer parameters per layer, reducing the memory footprint and the computational cost. We extensively evaluate our method against state-of-the-art PEFT methods on multiple fine-tuning tasks, and show that our method not only outperforms them, but is also more parameter, memory and computationally efficient. Moreover, thanks to its memory efficiency, 1LoRA allows to fine-tune more evenly across layers, instead of focusing on specific ones (e.g. attention layers), improving performance further.
MRI Reconstruction with Regularized 3D Diffusion Model (R3DM)
Dec 25, 2024Magnetic Resonance Imaging (MRI) is a powerful imaging technique widely used for visualizing structures within the human body and in other fields such as plant sciences. However, there is a demand to develop fast 3D-MRI reconstruction algorithms to show the fine structure of objects from under-sampled acquisition data, i.e., k-space data. This emphasizes the need for efficient solutions that can handle limited input while maintaining high-quality imaging. In contrast to previous methods only using 2D, we propose a 3D MRI reconstruction method that leverages a regularized 3D diffusion model combined with optimization method. By incorporating diffusion based priors, our method improves image quality, reduces noise, and enhances the overall fidelity of 3D MRI reconstructions. We conduct comprehensive experiments analysis on clinical and plant science MRI datasets. To evaluate the algorithm effectiveness for under-sampled k-space data, we also demonstrate its reconstruction performance with several undersampling patterns, as well as with in- and out-of-distribution pre-trained data. In experiments, we show that our method improves upon tested competitors.
FlashVTG: Feature Layering and Adaptive Score Handling Network for Video Temporal Grounding
Dec 18, 2024
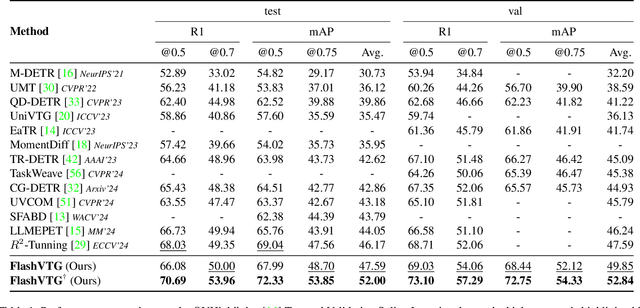

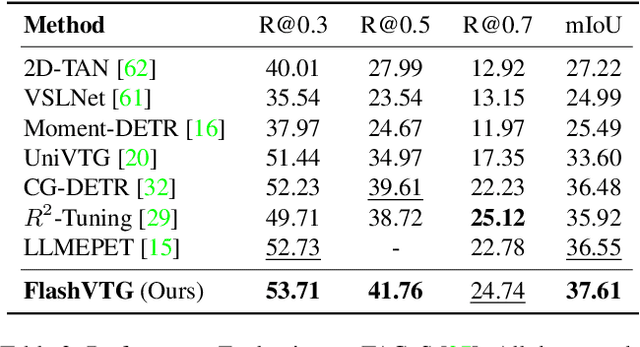
Text-guided Video Temporal Grounding (VTG) aims to localize relevant segments in untrimmed videos based on textual descriptions, encompassing two subtasks: Moment Retrieval (MR) and Highlight Detection (HD). Although previous typical methods have achieved commendable results, it is still challenging to retrieve short video moments. This is primarily due to the reliance on sparse and limited decoder queries, which significantly constrain the accuracy of predictions. Furthermore, suboptimal outcomes often arise because previous methods rank predictions based on isolated predictions, neglecting the broader video context. To tackle these issues, we introduce FlashVTG, a framework featuring a Temporal Feature Layering (TFL) module and an Adaptive Score Refinement (ASR) module. The TFL module replaces the traditional decoder structure to capture nuanced video content variations across multiple temporal scales, while the ASR module improves prediction ranking by integrating context from adjacent moments and multi-temporal-scale features. Extensive experiments demonstrate that FlashVTG achieves state-of-the-art performance on four widely adopted datasets in both MR and HD. Specifically, on the QVHighlights dataset, it boosts mAP by 5.8% for MR and 3.3% for HD. For short-moment retrieval, FlashVTG increases mAP to 125% of previous SOTA performance. All these improvements are made without adding training burdens, underscoring its effectiveness. Our code is available at https://github.com/Zhuo-Cao/FlashVTG.
TokenBinder: Text-Video Retrieval with One-to-Many Alignment Paradigm
Sep 30, 2024



Text-Video Retrieval (TVR) methods typically match query-candidate pairs by aligning text and video features in coarse-grained, fine-grained, or combined (coarse-to-fine) manners. However, these frameworks predominantly employ a one(query)-to-one(candidate) alignment paradigm, which struggles to discern nuanced differences among candidates, leading to frequent mismatches. Inspired by Comparative Judgement in human cognitive science, where decisions are made by directly comparing items rather than evaluating them independently, we propose TokenBinder. This innovative two-stage TVR framework introduces a novel one-to-many coarse-to-fine alignment paradigm, imitating the human cognitive process of identifying specific items within a large collection. Our method employs a Focused-view Fusion Network with a sophisticated cross-attention mechanism, dynamically aligning and comparing features across multiple videos to capture finer nuances and contextual variations. Extensive experiments on six benchmark datasets confirm that TokenBinder substantially outperforms existing state-of-the-art methods. These results demonstrate its robustness and the effectiveness of its fine-grained alignment in bridging intra- and inter-modality information gaps in TVR tasks.
Combining Efficient and Precise Sign Language Recognition: Good pose estimation library is all you need
Sep 30, 2022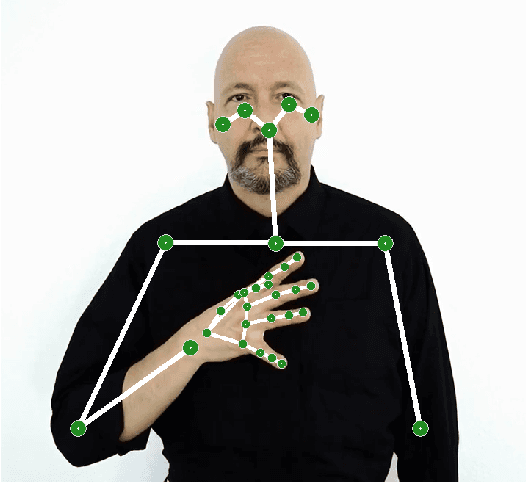

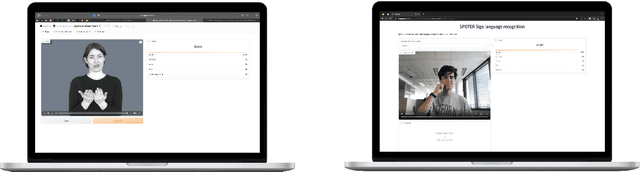
Sign language recognition could significantly improve the user experience for d/Deaf people with the general consumer technology, such as IoT devices or videoconferencing. However, current sign language recognition architectures are usually computationally heavy and require robust GPU-equipped hardware to run in real-time. Some models aim for lower-end devices (such as smartphones) by minimizing their size and complexity, which leads to worse accuracy. This highly scrutinizes accurate in-the-wild applications. We build upon the SPOTER architecture, which belongs to the latter group of light methods, as it came close to the performance of large models employed for this task. By substituting its original third-party pose estimation module with the MediaPipe library, we achieve an overall state-of-the-art result on the WLASL100 dataset. Significantly, our method beats previous larger architectures while still being twice as computationally efficient and almost $11$ times faster on inference when compared to a relevant benchmark. To demonstrate our method's combined efficiency and precision, we built an online demo that enables users to translate sign lemmas of American sign language in their browsers. This is the first publicly available online application demonstrating this task to the best of our knowledge.