 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from What is Already Out There: Few-shot Sign Language Recognition with Online Dictionaries
Jan 10, 2023Today's sign language recognition models require large training corpora of laboratory-like videos, whose collection involves an extensive workforce and financial resources. As a result, only a handful of such systems are publicly available, not to mention their limited localization capabilities for less-populated sign languages. Utilizing online text-to-video dictionaries, which inherently hold annotated data of various attributes and sign languages, and training models in a few-shot fashion hence poses a promising path for the democratization of this technology. In this work, we collect and open-source the UWB-SL-Wild few-shot dataset, the first of its kind training resource consisting of dictionary-scraped videos. This dataset represents the actual distribution and characteristics of available online sign language data. We select glosses that directly overlap with the already existing datasets WLASL100 and ASLLVD and share their class mappings to allow for transfer learning experiments. Apart from providing baseline results on a pose-based architecture, we introduce a novel approach to training sign language recognition models in a few-shot scenario, resulting in state-of-the-art results on ASLLVD-Skeleton and ASLLVD-Skeleton-20 datasets with top-1 accuracy of $30.97~\%$ and $95.45~\%$, respectively.
Fine-grained Czech News Article Dataset: An Interdisciplinary Approach to Trustworthiness Analysis
Dec 16, 2022



We present the Verifee Dataset: a novel dataset of news articles with fine-grained trustworthiness annotations. We develop a detailed methodology that assesses the texts based on their parameters encompassing editorial transparency, journalist conventions, and objective reporting while penalizing manipulative techniques. We bring aboard a diverse set of researchers from social, media, and computer sciences to overcome barriers and limited framing of this interdisciplinary problem. We collect over $10,000$ unique articles from almost $60$ Czech online news sources. These are categorized into one of the $4$ classes across the credibility spectrum we propose, raging from entirely trustworthy articles all the way to the manipulative ones. We produce detailed statistics and study trends emerging throughout the set. Lastly, we fine-tune multiple popular sequence-to-sequence language models using our dataset on the trustworthiness classification task and report the best testing F-1 score of $0.52$. We open-source the dataset, annotation methodology, and annotators' instructions in full length at https://verifee.ai/research to enable easy build-up work. We believe similar methods can help prevent disinformation and educate in the realm of media literacy.
Combining Efficient and Precise Sign Language Recognition: Good pose estimation library is all you need
Sep 30, 2022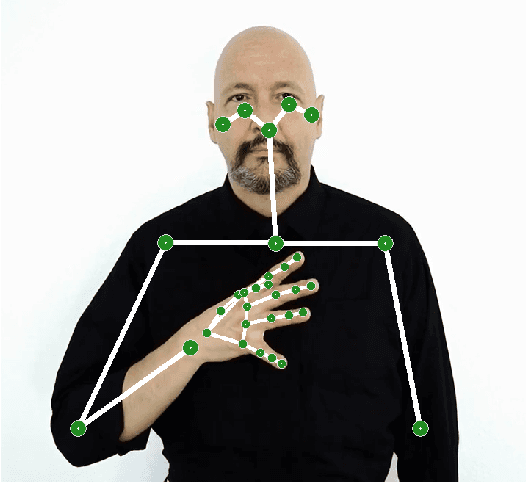

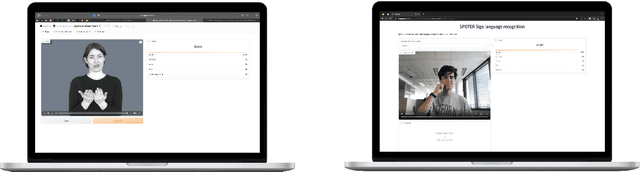
Sign language recognition could significantly improve the user experience for d/Deaf people with the general consumer technology, such as IoT devices or videoconferencing. However, current sign language recognition architectures are usually computationally heavy and require robust GPU-equipped hardware to run in real-time. Some models aim for lower-end devices (such as smartphones) by minimizing their size and complexity, which leads to worse accuracy. This highly scrutinizes accurate in-the-wild applications. We build upon the SPOTER architecture, which belongs to the latter group of light methods, as it came close to the performance of large models employed for this task. By substituting its original third-party pose estimation module with the MediaPipe library, we achieve an overall state-of-the-art result on the WLASL100 dataset. Significantly, our method beats previous larger architectures while still being twice as computationally efficient and almost $11$ times faster on inference when compared to a relevant benchmark. To demonstrate our method's combined efficiency and precision, we built an online demo that enables users to translate sign lemmas of American sign language in their browsers. This is the first publicly available online application demonstrating this task to the best of our knowledge.
Protecting President Zelenskyy against Deep Fakes
Jun 24, 2022
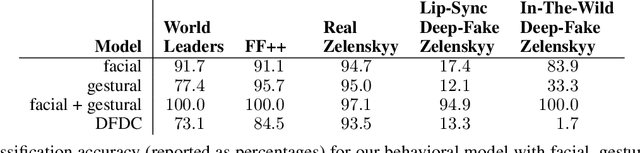

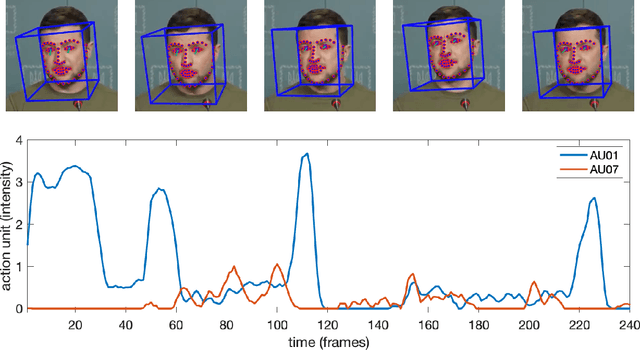
The 2022 Russian invasion of Ukraine is being fought on two fronts: a brutal ground war and a duplicitous disinformation campaign designed to conceal and justify Russia's actions. This campaign includes at least one example of a deep-fake video purportedly showing Ukrainian President Zelenskyy admitting defeat and surrendering. In anticipation of future attacks of this form, we describe a facial and gestural behavioral model that captures distinctive characteristics of Zelenskyy's speaking style. Trained on over eight hours of authentic video from four different settings, we show that this behavioral model can distinguish Zelenskyy from deep-fake imposters.This model can play an important role -- particularly during the fog of war -- in distinguishing the real from the fake.