 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeline and Dataset Generation for Automated Fact-checking in Almost Any Language
Dec 15, 2023This article presents a pipeline for automated fact-checking leveraging publicly available Language Models and data. The objective is to assess the accuracy of textual claims using evidence from a ground-truth evidence corpus. The pipeline consists of two main modules -- the evidence retrieval and the claim veracity evaluation. Our primary focus is on the ease of deployment in various languages that remain unexplored in the field of automated fact-checking. Unlike most similar pipelines, which work with evidence sentences, our pipeline processes data on a paragraph level, simplifying the overall architecture and data requirements. Given the high cost of annotating language-specific fact-checking training data, our solution builds on the Question Answering for Claim Generation (QACG) method, which we adapt and use to generate the data for all models of the pipeline. Our strategy enables the introduction of new languages through machine translation of only two fixed datasets of moderate size. Subsequently, any number of training samples can be generated based on an evidence corpus in the target language. We provide open access to all data and fine-tuned models for Czech, English, Polish, and Slovak pipelines, as well as to our codebase that may be used to reproduce the results.We comprehensively evaluate the pipelines for all four languages, including human annotations and per-sample difficulty assessment using Pointwise V-information. The presented experiments are based on full Wikipedia snapshots to promote reproducibility. To facilitate implementation and user interaction, we develop the FactSearch application featuring the proposed pipeline and the preliminary feedback on its performance.
Fine-grained Czech News Article Dataset: An Interdisciplinary Approach to Trustworthiness Analysis
Dec 16, 2022



We present the Verifee Dataset: a novel dataset of news articles with fine-grained trustworthiness annotations. We develop a detailed methodology that assesses the texts based on their parameters encompassing editorial transparency, journalist conventions, and objective reporting while penalizing manipulative techniques. We bring aboard a diverse set of researchers from social, media, and computer sciences to overcome barriers and limited framing of this interdisciplinary problem. We collect over $10,000$ unique articles from almost $60$ Czech online news sources. These are categorized into one of the $4$ classes across the credibility spectrum we propose, raging from entirely trustworthy articles all the way to the manipulative ones. We produce detailed statistics and study trends emerging throughout the set. Lastly, we fine-tune multiple popular sequence-to-sequence language models using our dataset on the trustworthiness classification task and report the best testing F-1 score of $0.52$. We open-source the dataset, annotation methodology, and annotators' instructions in full length at https://verifee.ai/research to enable easy build-up work. We believe similar methods can help prevent disinformation and educate in the realm of media literacy.
CsFEVER and CTKFacts: Czech Datasets for Fact Verification
Jan 31, 2022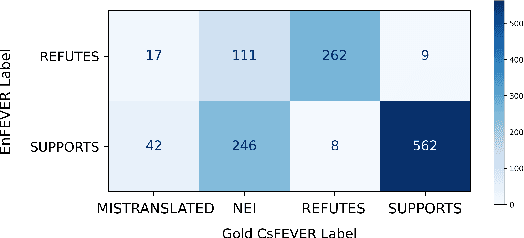
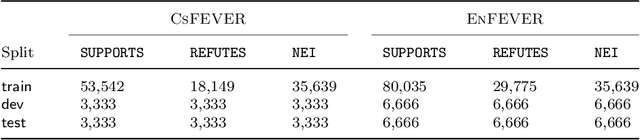

In this paper, we present two Czech datasets for automated fact-checking, which is a task commonly modeled as a classification of textual claim veracity w.r.t. a corpus of trusted ground truths. We consider 3 classes: SUPPORTS, REFUTES complemented with evidence documents or NEI (Not Enough Info) alone. Our first dataset, CsFEVER, has 127,328 claims. It is an automatically generated Czech version of the large-scale FEVER dataset built on top of Wikipedia corpus. We take a hybrid approach of machine translation and document alignment; the approach, and the tools we provide, can be easily applied to other languages. The second dataset, CTKFacts of 3,097 claims, is annotated using the corpus of 2.2M articles of Czech News Agency. We present its extended annotation methodology based on the FEVER approach. We analyze both datasets for spurious cues - annotation patterns leading to model overfitting. CTKFacts is further examined for inter-annotator agreement, thoroughly cleaned, and a typology of common annotator errors is extracted. Finally, we provide baseline models for all stages of the fact-checking pipeline.
Czech News Dataset for Semantic Textual Similarity
Aug 23, 2021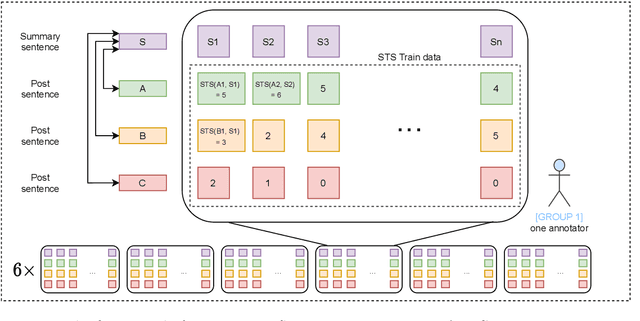
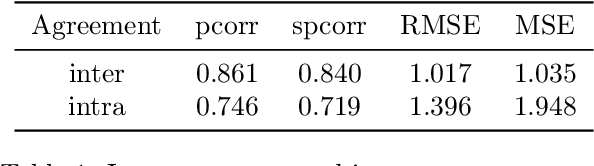

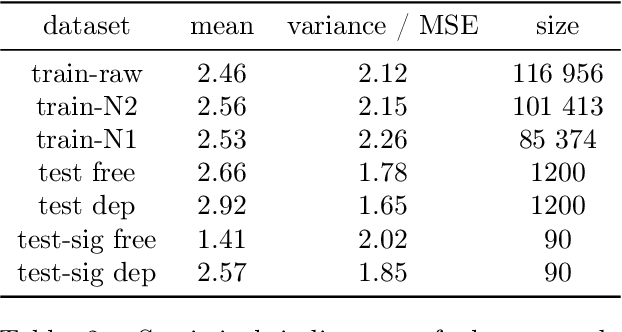
This paper describes a novel dataset consisting of sentences with semantic similarity annotations. The data originate from the journalistic domain in the Czech language. We describe the process of collecting and annotating the data in detail. The dataset contains 138,556 human annotations divided into train and test sets. In total, 485 journalism students participated in the creation process. To increase the reliability of the test set, we compute the annotation as an average of 9 individual annotations. We evaluate the quality of the dataset by measuring inter and intra annotation annotators' agreements. Beside agreement numbers, we provide detailed statistics of the collected dataset. We conclude our paper with a baseline experiment of building a system for predicting the semantic similarity of sentences. Due to the massive number of training annotations (116 956), the model can perform significantly better than an average annotator (0,92 versus 0,86 of Person's correlation coefficients).