 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaim Extraction for Fact-Checking: Data, Models, and Automated Metrics
Feb 07, 2025



In this paper, we explore the problem of Claim Extraction using one-to-many text generation methods, comparing LLMs, small summarization models finetuned for the task, and a previous NER-centric baseline QACG. As the current publications on Claim Extraction, Fact Extraction, Claim Generation and Check-worthy Claim Detection are quite scattered in their means and terminology, we compile their common objectives, releasing the FEVERFact dataset, with 17K atomic factual claims extracted from 4K contextualised Wikipedia sentences, adapted from the original FEVER. We compile the known objectives into an Evaluation framework of: Atomicity, Fluency, Decontextualization, Faithfulness checked for each generated claim separately, and Focus and Coverage measured against the full set of predicted claims for a single input. For each metric, we implement a scale using a reduction to an already-explored NLP task. We validate our metrics against human grading of generic claims, to see that the model ranking on $F_{fact}$, our hardest metric, did not change and the evaluation framework approximates human grading very closely in terms of $F_1$ and RMSE.
AIC CTU system at AVeriTeC: Re-framing automated fact-checking as a simple RAG task
Oct 15, 2024
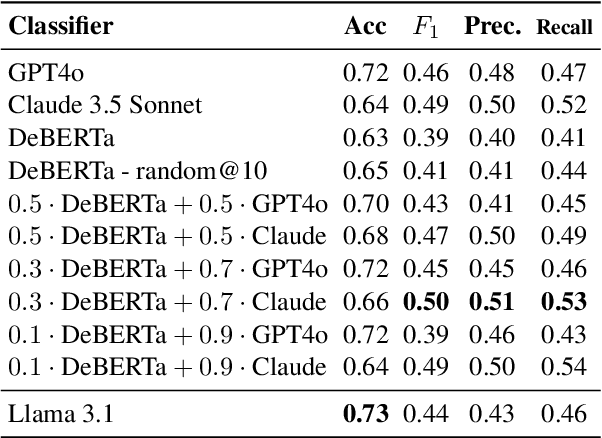

This paper describes our $3^{rd}$ place submission in the AVeriTeC shared task in which we attempted to address the challenge of fact-checking with evidence retrieved in the wild using a simple scheme of Retrieval-Augmented Generation (RAG) designed for the task, leveraging the predictive power of Large Language Models. We release our codebase and explain its two modules - the Retriever and the Evidence & Label generator - in detail, justifying their features such as MMR-reranking and Likert-scale confidence estimation. We evaluate our solution on AVeriTeC dev and test set and interpret the results, picking the GPT-4o as the most appropriate model for our pipeline at the time of our publication, with Llama 3.1 70B being a promising open-source alternative. We perform an empirical error analysis to see that faults in our predictions often coincide with noise in the data or ambiguous fact-checks, provoking further research and data augmentation.
Pipeline and Dataset Generation for Automated Fact-checking in Almost Any Language
Dec 15, 2023This article presents a pipeline for automated fact-checking leveraging publicly available Language Models and data. The objective is to assess the accuracy of textual claims using evidence from a ground-truth evidence corpus. The pipeline consists of two main modules -- the evidence retrieval and the claim veracity evaluation. Our primary focus is on the ease of deployment in various languages that remain unexplored in the field of automated fact-checking. Unlike most similar pipelines, which work with evidence sentences, our pipeline processes data on a paragraph level, simplifying the overall architecture and data requirements. Given the high cost of annotating language-specific fact-checking training data, our solution builds on the Question Answering for Claim Generation (QACG) method, which we adapt and use to generate the data for all models of the pipeline. Our strategy enables the introduction of new languages through machine translation of only two fixed datasets of moderate size. Subsequently, any number of training samples can be generated based on an evidence corpus in the target language. We provide open access to all data and fine-tuned models for Czech, English, Polish, and Slovak pipelines, as well as to our codebase that may be used to reproduce the results.We comprehensively evaluate the pipelines for all four languages, including human annotations and per-sample difficulty assessment using Pointwise V-information. The presented experiments are based on full Wikipedia snapshots to promote reproducibility. To facilitate implementation and user interaction, we develop the FactSearch application featuring the proposed pipeline and the preliminary feedback on its performance.