 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectroCardioGuard: Preventing Patient Misidentification in Electrocardiogram Databases through Neural Networks
Jun 09, 2023Electrocardiograms (ECGs) are commonly used by cardiologists to detect heart-related pathological conditions. Reliable collections of ECGs are crucial for precise diagnosis. However, in clinical practice, the assignment of captured ECG recordings to incorrect patients can occur inadvertently. In collaboration with a clinical and research facility which recognized this challenge and reached out to us, we present a study that addresses this issue. In this work, we propose a small and efficient neural-network based model for determining whether two ECGs originate from the same patient. Our model demonstrates great generalization capabilities and achieves state-of-the-art performance in gallery-probe patient identification on PTB-XL while utilizing 760x fewer parameters. Furthermore, we present a technique leveraging our model for detection of recording-assignment mistakes, showcasing its applicability in a realistic scenario. Finally, we evaluate our model on a newly collected ECG dataset specifically curated for this study, and make it public for the research community.
Czech News Dataset for Semantic Textual Similarity
Aug 23, 2021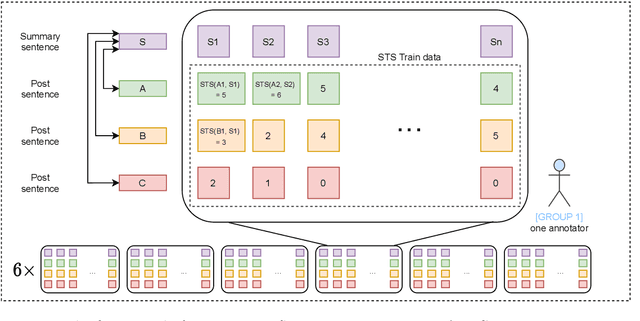
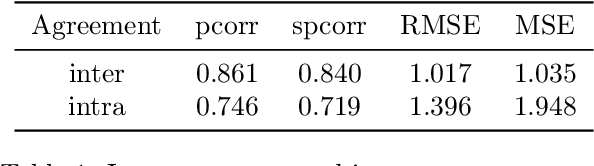

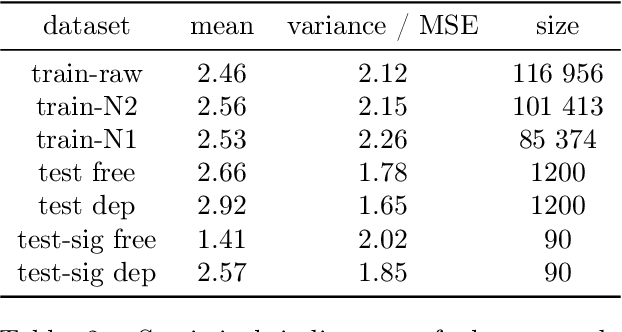
This paper describes a novel dataset consisting of sentences with semantic similarity annotations. The data originate from the journalistic domain in the Czech language. We describe the process of collecting and annotating the data in detail. The dataset contains 138,556 human annotations divided into train and test sets. In total, 485 journalism students participated in the creation process. To increase the reliability of the test set, we compute the annotation as an average of 9 individual annotations. We evaluate the quality of the dataset by measuring inter and intra annotation annotators' agreements. Beside agreement numbers, we provide detailed statistics of the collected dataset. We conclude our paper with a baseline experiment of building a system for predicting the semantic similarity of sentences. Due to the massive number of training annotations (116 956), the model can perform significantly better than an average annotator (0,92 versus 0,86 of Person's correlation coefficients).
Czert -- Czech BERT-like Model for Language Representation
Mar 24, 2021
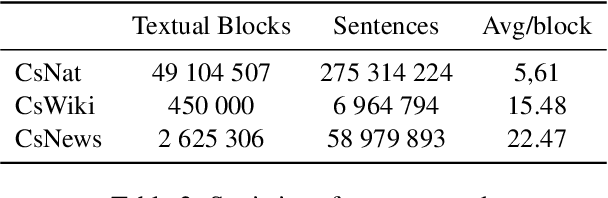


This paper describes the training process of the first Czech monolingual language representation models based on BERT and ALBERT architectures. We pre-train our models on more than 340K of sentences, which is 50 times more than multilingual models that include Czech data. We outperform the multilingual models on 7 out of 10 datasets. In addition, we establish the new state-of-the-art results on seven datasets. At the end, we discuss properties of monolingual and multilingual models based upon our results. We publish all the pre-trained and fine-tuned models freely for the research community.