 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCzech Dataset for Complex Aspect-Based Sentiment Analysis Tasks
Aug 11, 2025In this paper, we introduce a novel Czech dataset for aspect-based sentiment analysis (ABSA), which consists of 3.1K manually annotated reviews from the restaurant domain. The dataset is built upon the older Czech dataset, which contained only separate labels for the basic ABSA tasks such as aspect term extraction or aspect polarity detection. Unlike its predecessor, our new dataset is specifically designed for more complex tasks, e.g. target-aspect-category detection. These advanced tasks require a unified annotation format, seamlessly linking sentiment elements (labels) together. Our dataset follows the format of the well-known SemEval-2016 datasets. This design choice allows effortless application and evaluation in cross-lingual scenarios, ultimately fostering cross-language comparisons with equivalent counterpart datasets in other languages. The annotation process engaged two trained annotators, yielding an impressive inter-annotator agreement rate of approximately 90%. Additionally, we provide 24M reviews without annotations suitable for unsupervised learning. We present robust monolingual baseline results achieved with various Transformer-based models and insightful error analysis to supplement our contributions. Our code and dataset are freely available for non-commercial research purposes.
Findings of the Third Shared Task on Multilingual Coreference Resolution
Oct 21, 2024The paper presents an overview of the third edition of the shared task on multilingual coreference resolution, held as part of the CRAC 2024 workshop. Similarly to the previous two editions, the participants were challenged to develop systems capable of identifying mentions and clustering them based on identity coreference. This year's edition took another step towards real-world application by not providing participants with gold slots for zero anaphora, increasing the task's complexity and realism. In addition, the shared task was expanded to include a more diverse set of languages, with a particular focus on historical languages. The training and evaluation data were drawn from version 1.2 of the multilingual collection of harmonized coreference resources CorefUD, encompassing 21 datasets across 15 languages. 6 systems competed in this shared task.
Exploring Multiple Strategies to Improve Multilingual Coreference Resolution in CorefUD
Aug 29, 2024

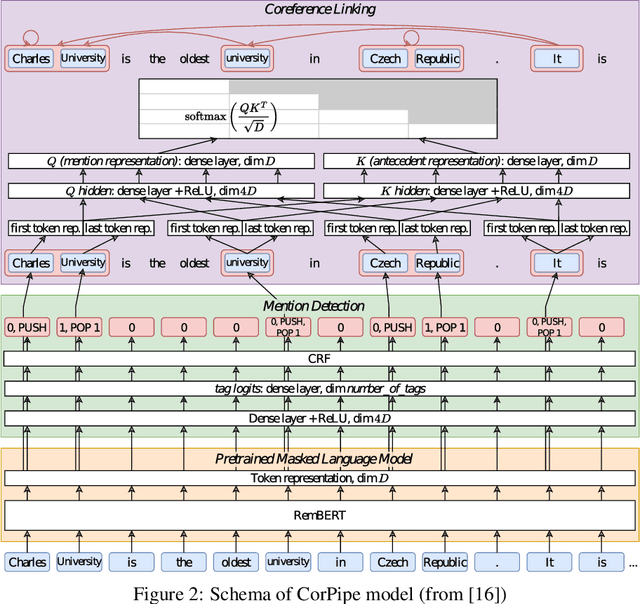

Coreference resolution, the task of identifying expressions in text that refer to the same entity, is a critical component in various natural language processing (NLP) applications. This paper presents our end-to-end neural coreference resolution system, utilizing the CorefUD 1.1 dataset, which spans 17 datasets across 12 languages. We first establish strong baseline models, including monolingual and cross-lingual variations, and then propose several extensions to enhance performance across diverse linguistic contexts. These extensions include cross-lingual training, incorporation of syntactic information, a Span2Head model for optimized headword prediction, and advanced singleton modeling. We also experiment with headword span representation and long-documents modeling through overlapping segments. The proposed extensions, particularly the heads-only approach, singleton modeling, and long document prediction significantly improve performance across most datasets. We also perform zero-shot cross-lingual experiments, highlighting the potential and limitations of cross-lingual transfer in coreference resolution. Our findings contribute to the development of robust and scalable coreference systems for multilingual coreference resolution. Finally, we evaluate our model on CorefUD 1.1 test set and surpass the best model from CRAC 2023 shared task of a comparable size by a large margin. Our nodel is available on GitHub: \url{https://github.com/ondfa/coref-multiling}
Improving Aspect-Based Sentiment with End-to-End Semantic Role Labeling Model
Jul 27, 2023This paper presents a series of approaches aimed at enhancing the performance of Aspect-Based Sentiment Analysis (ABSA) by utilizing extracted semantic information from a Semantic Role Labeling (SRL) model. We propose a novel end-to-end Semantic Role Labeling model that effectively captures most of the structured semantic information within the Transformer hidden state. We believe that this end-to-end model is well-suited for our newly proposed models that incorporate semantic information. We evaluate the proposed models in two languages, English and Czech, employing ELECTRA-small models. Our combined models improve ABSA performance in both languages. Moreover, we achieved new state-of-the-art results on the Czech ABSA.
End-to-end Multilingual Coreference Resolution with Mention Head Prediction
Sep 26, 2022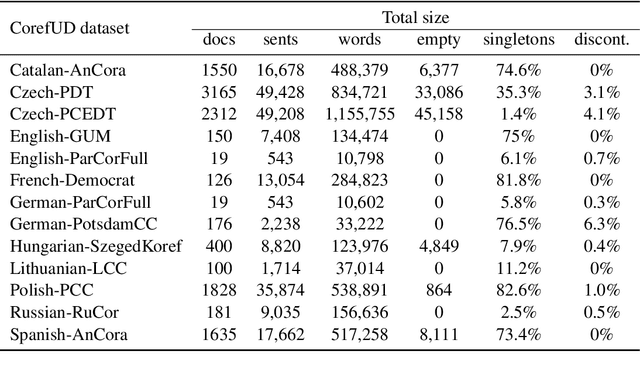


This paper describes our approach to the CRAC 2022 Shared Task on Multilingual Coreference Resolution. Our model is based on a state-of-the-art end-to-end coreference resolution system. Apart from joined multilingual training, we improved our results with mention head prediction. We also tried to integrate dependency information into our model. Our system ended up in $3^{rd}$ place. Moreover, we reached the best performance on two datasets out of 13.
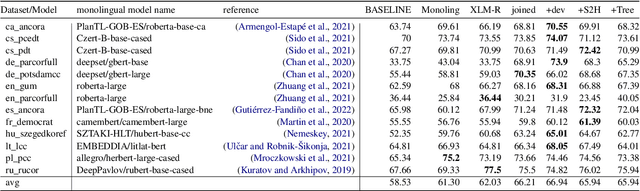
Findings of the Shared Task on Multilingual Coreference Resolution
Sep 16, 2022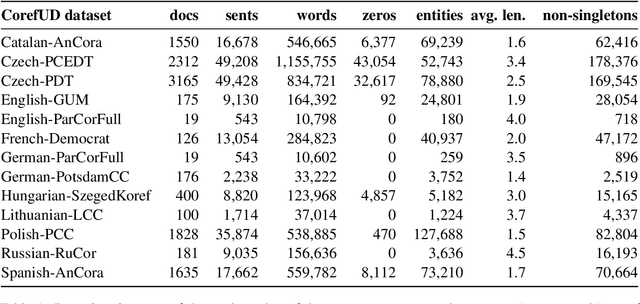
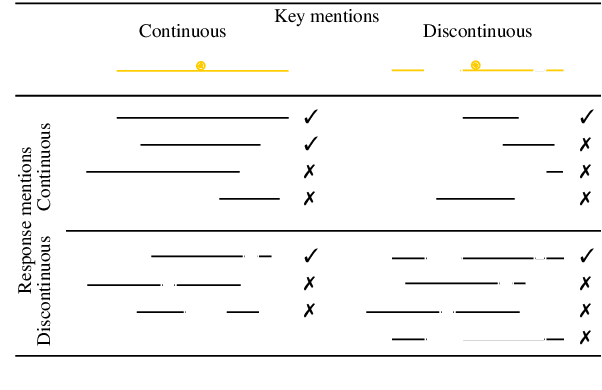

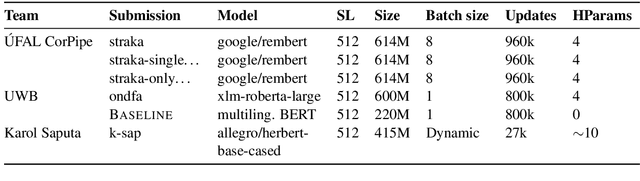
This paper presents an overview of the shared task on multilingual coreference resolution associated with the CRAC 2022 workshop. Shared task participants were supposed to develop trainable systems capable of identifying mentions and clustering them according to identity coreference. The public edition of CorefUD 1.0, which contains 13 datasets for 10 languages, was used as the source of training and evaluation data. The CoNLL score used in previous coreference-oriented shared tasks was used as the main evaluation metric. There were 8 coreference prediction systems submitted by 5 participating teams; in addition, there was a competitive Transformer-based baseline system provided by the organizers at the beginning of the shared task. The winner system outperformed the baseline by 12 percentage points (in terms of the CoNLL scores averaged across all datasets for individual languages).
MQDD: Pre-training of Multimodal Question Duplicity Detection for Software Engineering Domain
Mar 29, 2022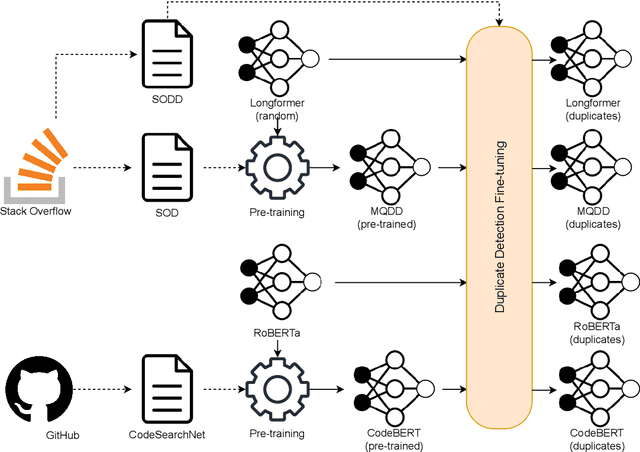

This work proposes a new pipeline for leveraging data collected on the Stack Overflow website for pre-training a multimodal model for searching duplicates on question answering websites. Our multimodal model is trained on question descriptions and source codes in multiple programming languages. We design two new learning objectives to improve duplicate detection capabilities. The result of this work is a mature, fine-tuned Multimodal Question Duplicity Detection (MQDD) model, ready to be integrated into a Stack Overflow search system, where it can help users find answers for already answered questions. Alongside the MQDD model, we release two datasets related to the software engineering domain. The first Stack Overflow Dataset (SOD) represents a massive corpus of paired questions and answers. The second Stack Overflow Duplicity Dataset (SODD) contains data for training duplicate detection models.
Czech News Dataset for Semantic Textual Similarity
Aug 23, 2021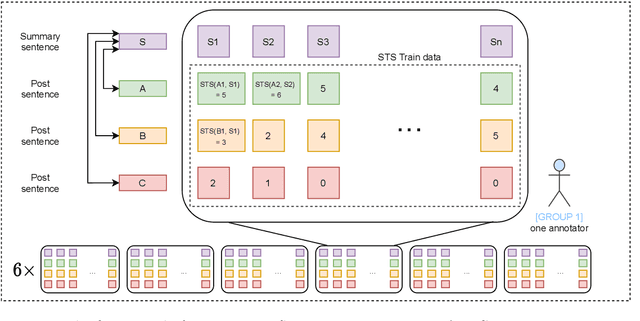
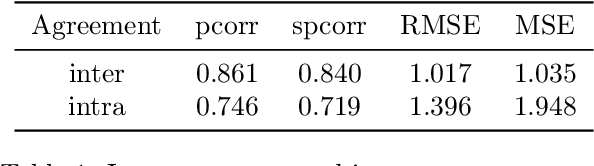

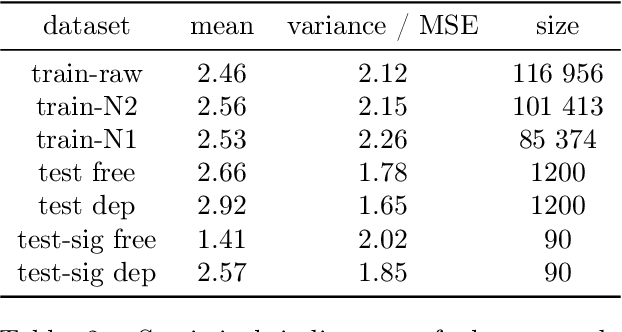
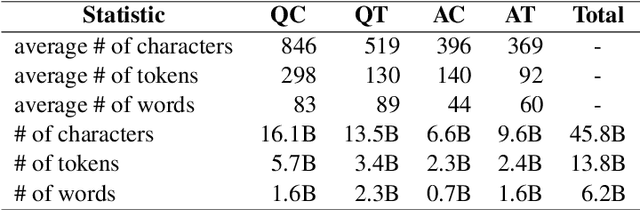
This paper describes a novel dataset consisting of sentences with semantic similarity annotations. The data originate from the journalistic domain in the Czech language. We describe the process of collecting and annotating the data in detail. The dataset contains 138,556 human annotations divided into train and test sets. In total, 485 journalism students participated in the creation process. To increase the reliability of the test set, we compute the annotation as an average of 9 individual annotations. We evaluate the quality of the dataset by measuring inter and intra annotation annotators' agreements. Beside agreement numbers, we provide detailed statistics of the collected dataset. We conclude our paper with a baseline experiment of building a system for predicting the semantic similarity of sentences. Due to the massive number of training annotations (116 956), the model can perform significantly better than an average annotator (0,92 versus 0,86 of Person's correlation coefficients).
Multilingual Coreference Resolution with Harmonized Annotations
Jul 26, 2021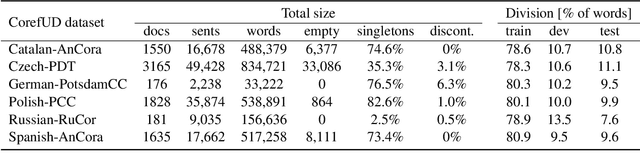

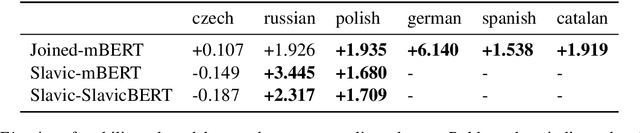
In this paper, we present coreference resolution experiments with a newly created multilingual corpus CorefUD. We focus on the following languages: Czech, Russian, Polish, German, Spanish, and Catalan. In addition to monolingual experiments, we combine the training data in multilingual experiments and train two joined models -- for Slavic languages and for all the languages together. We rely on an end-to-end deep learning model that we slightly adapted for the CorefUD corpus. Our results show that we can profit from harmonized annotations, and using joined models helps significantly for the languages with smaller training data.
Czert -- Czech BERT-like Model for Language Representation
Mar 24, 2021
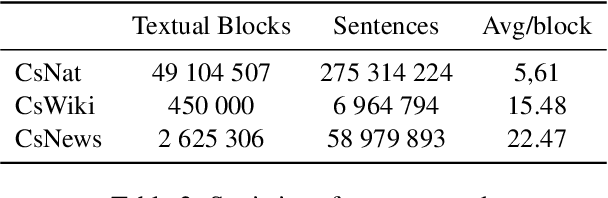


This paper describes the training process of the first Czech monolingual language representation models based on BERT and ALBERT architectures. We pre-train our models on more than 340K of sentences, which is 50 times more than multilingual models that include Czech data. We outperform the multilingual models on 7 out of 10 datasets. In addition, we establish the new state-of-the-art results on seven datasets. At the end, we discuss properties of monolingual and multilingual models based upon our results. We publish all the pre-trained and fine-tuned models freely for the research community.