 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Third Shared Task on Multilingual Coreference Resolution
Oct 21, 2024



The paper presents an overview of the third edition of the shared task on multilingual coreference resolution, held as part of the CRAC 2024 workshop. Similarly to the previous two editions, the participants were challenged to develop systems capable of identifying mentions and clustering them based on identity coreference. This year's edition took another step towards real-world application by not providing participants with gold slots for zero anaphora, increasing the task's complexity and realism. In addition, the shared task was expanded to include a more diverse set of languages, with a particular focus on historical languages. The training and evaluation data were drawn from version 1.2 of the multilingual collection of harmonized coreference resources CorefUD, encompassing 21 datasets across 15 languages. 6 systems competed in this shared task.
Findings of the Shared Task on Multilingual Coreference Resolution
Sep 16, 2022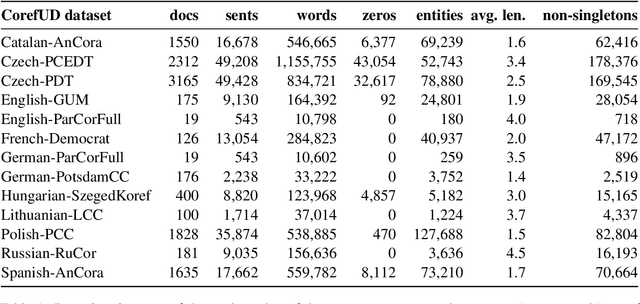

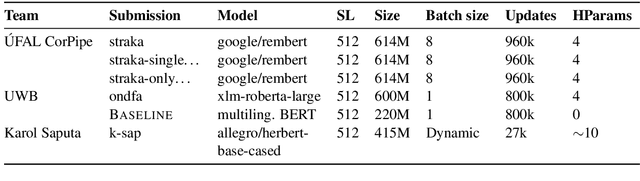
This paper presents an overview of the shared task on multilingual coreference resolution associated with the CRAC 2022 workshop. Shared task participants were supposed to develop trainable systems capable of identifying mentions and clustering them according to identity coreference. The public edition of CorefUD 1.0, which contains 13 datasets for 10 languages, was used as the source of training and evaluation data. The CoNLL score used in previous coreference-oriented shared tasks was used as the main evaluation metric. There were 8 coreference prediction systems submitted by 5 participating teams; in addition, there was a competitive Transformer-based baseline system provided by the organizers at the beginning of the shared task. The winner system outperformed the baseline by 12 percentage points (in terms of the CoNLL scores averaged across all datasets for individual languages).
The SIGMORPHON 2022 Shared Task on Morpheme Segmentation
Jun 15, 2022
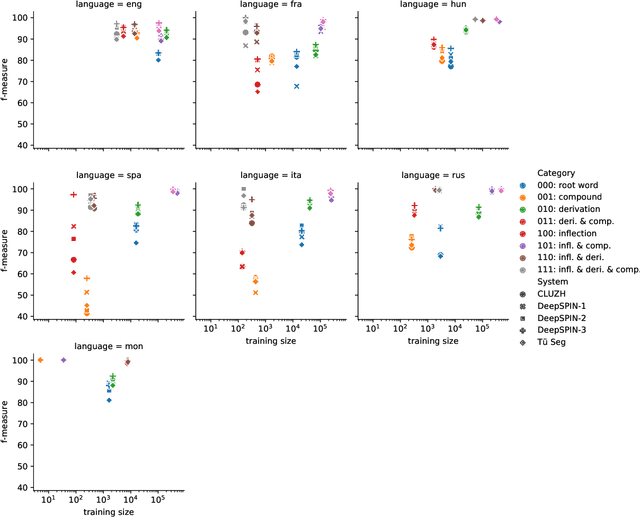
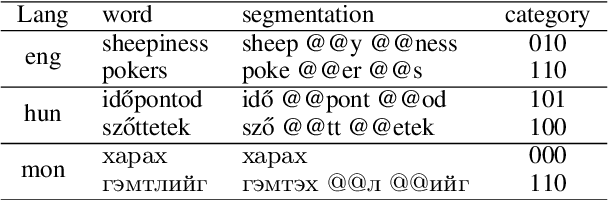
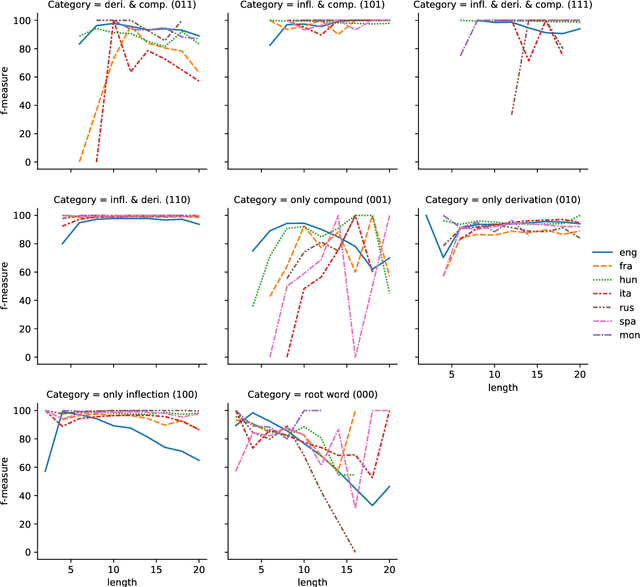
The SIGMORPHON 2022 shared task on morpheme segmentation challenged systems to decompose a word into a sequence of morphemes and covered most types of morphology: compounds, derivations, and inflections. Subtask 1, word-level morpheme segmentation, covered 5 million words in 9 languages (Czech, English, Spanish, Hungarian, French, Italian, Russian, Latin, Mongolian) and received 13 system submissions from 7 teams and the best system averaged 97.29% F1 score across all languages, ranging English (93.84%) to Latin (99.38%). Subtask 2, sentence-level morpheme segmentation, covered 18,735 sentences in 3 languages (Czech, English, Mongolian), received 10 system submissions from 3 teams, and the best systems outperformed all three state-of-the-art subword tokenization methods (BPE, ULM, Morfessor2) by 30.71% absolute. To facilitate error analysis and support any type of future studies, we released all system predictions, the evaluation script, and all gold standard datasets.
Unsupervised Lemmatization as Embeddings-Based Word Clustering
Aug 22, 2019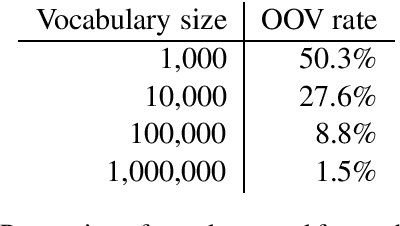
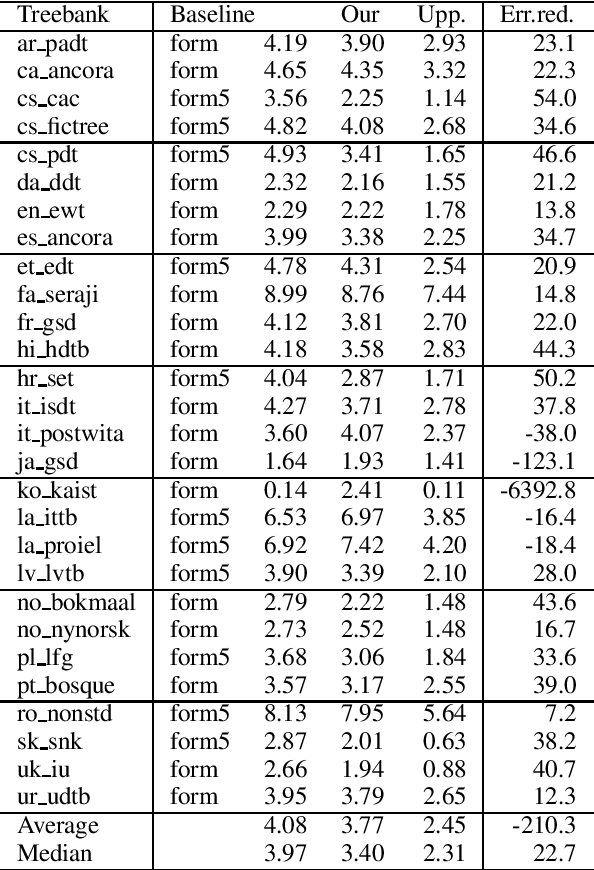
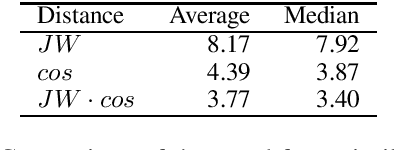
We focus on the task of unsupervised lemmatization, i.e. grouping together inflected forms of one word under one label (a lemma) without the use of annotated training data. We propose to perform agglomerative clustering of word forms with a novel distance measure. Our distance measure is based on the observation that inflections of the same word tend to be similar both string-wise and in meaning. We therefore combine word embedding cosine similarity, serving as a proxy to the meaning similarity, with Jaro-Winkler edit distance. Our experiments on 23 languages show our approach to be promising, surpassing the baseline on 23 of the 28 evaluation datasets.