 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOOVs in the Spotlight: How to Inflect them?
Apr 13, 2024We focus on morphological inflection in out-of-vocabulary (OOV) conditions, an under-researched subtask in which state-of-the-art systems usually are less effective. We developed three systems: a retrograde model and two sequence-to-sequence (seq2seq) models based on LSTM and Transformer. For testing in OOV conditions, we automatically extracted a large dataset of nouns in the morphologically rich Czech language, with lemma-disjoint data splits, and we further manually annotated a real-world OOV dataset of neologisms. In the standard OOV conditions, Transformer achieves the best results, with increasing performance in ensemble with LSTM, the retrograde model and SIGMORPHON baselines. On the real-world OOV dataset of neologisms, the retrograde model outperforms all neural models. Finally, our seq2seq models achieve state-of-the-art results in 9 out of 16 languages from SIGMORPHON 2022 shared task data in the OOV evaluation (feature overlap) in the large data condition. We release the Czech OOV Inflection Dataset for rigorous evaluation in OOV conditions. Further, we release the inflection system with the seq2seq models as a ready-to-use Python library.
DialogueScript: Using Dialogue Agents to Produce a Script
Jun 16, 2022


We present a novel approach to generating scripts by using agents with different personality types. To manage character interaction in the script, we employ simulated dramatic networks. Automatic and human evaluation on multiple criteria shows that our approach outperforms a vanilla-GPT2-based baseline. We further introduce a new metric to evaluate dialogue consistency based on natural language inference and demonstrate its validity.
THEaiTRE 1.0: Interactive generation of theatre play scripts
Feb 17, 2021We present the first version of a system for interactive generation of theatre play scripts. The system is based on a vanilla GPT-2 model with several adjustments, targeting specific issues we encountered in practice. We also list other issues we encountered but plan to only solve in a future version of the system. The presented system was used to generate a theatre play script planned for premiere in February 2021.
Predicting Typological Features in WALS using Language Embeddings and Conditional Probabilities: ÚFAL Submission to the SIGTYP 2020 Shared Task
Oct 08, 2020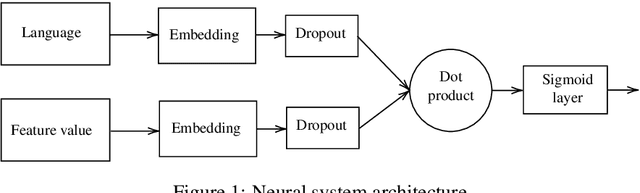
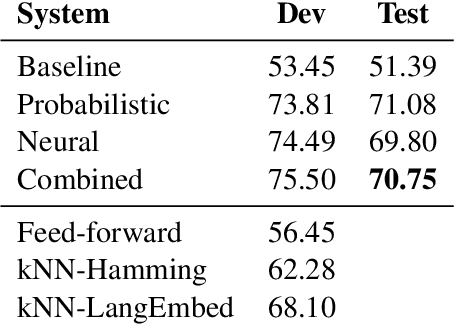
We present our submission to the SIGTYP 2020 Shared Task on the prediction of typological features. We submit a constrained system, predicting typological features only based on the WALS database. We investigate two approaches. The simpler of the two is a system based on estimating correlation of feature values within languages by computing conditional probabilities and mutual information. The second approach is to train a neural predictor operating on precomputed language embeddings based on WALS features. Our submitted system combines the two approaches based on their self-estimated confidence scores. We reach the accuracy of 70.7% on the test data and rank first in the shared task.
Measuring Memorization Effect in Word-Level Neural Networks Probing
Jun 29, 2020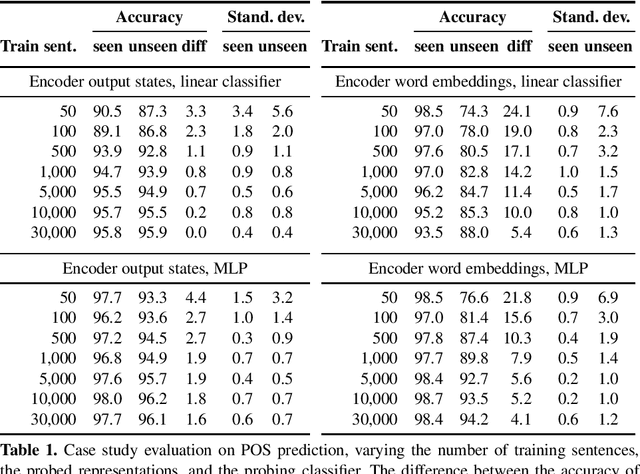
Multiple studies have probed representations emerging in neural networks trained for end-to-end NLP tasks and examined what word-level linguistic information may be encoded in the representations. In classical probing, a classifier is trained on the representations to extract the target linguistic information. However, there is a threat of the classifier simply memorizing the linguistic labels for individual words, instead of extracting the linguistic abstractions from the representations, thus reporting false positive results. While considerable efforts have been made to minimize the memorization problem, the task of actually measuring the amount of memorization happening in the classifier has been understudied so far. In our work, we propose a simple general method for measuring the memorization effect, based on a symmetric selection of comparable sets of test words seen versus unseen in training. Our method can be used to explicitly quantify the amount of memorization happening in a probing setup, so that an adequate setup can be chosen and the results of the probing can be interpreted with a reliability estimate. We exemplify this by showcasing our method on a case study of probing for part of speech in a trained neural machine translation encoder.
THEaiTRE: Artificial Intelligence to Write a Theatre Play
Jun 25, 2020We present THEaiTRE, a starting project aimed at automatic generation of theatre play scripts. This paper reviews related work and drafts an approach we intend to follow. We plan to adopt generative neural language models and hierarchical generation approaches, supported by summarization and machine translation methods, and complemented with a human-in-the-loop approach.
Universal Dependencies according to BERT: both more specific and more general
May 01, 2020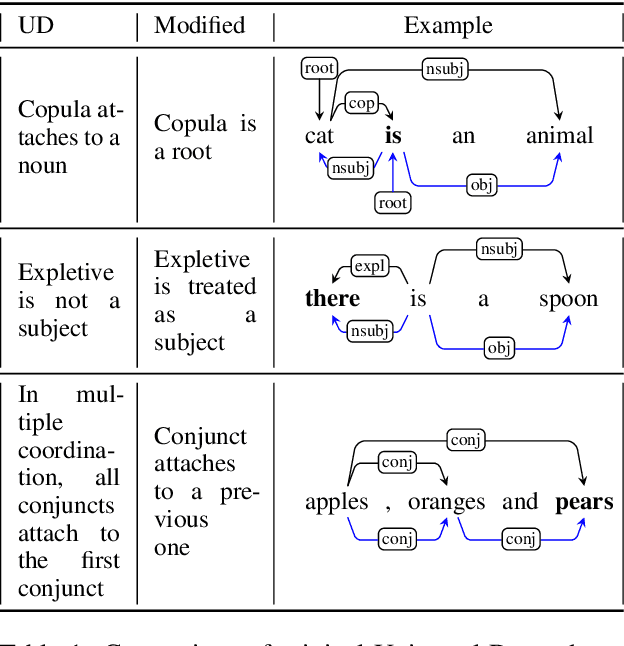
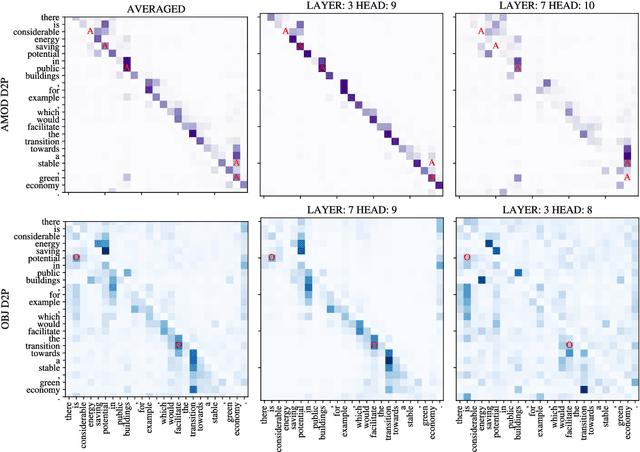
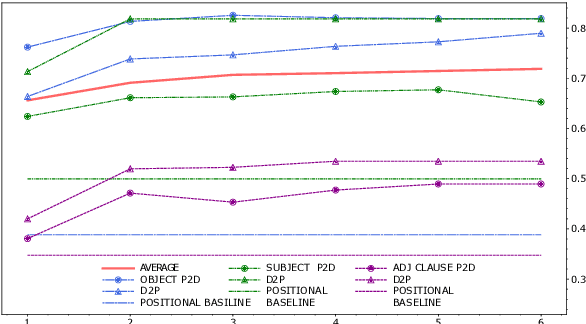
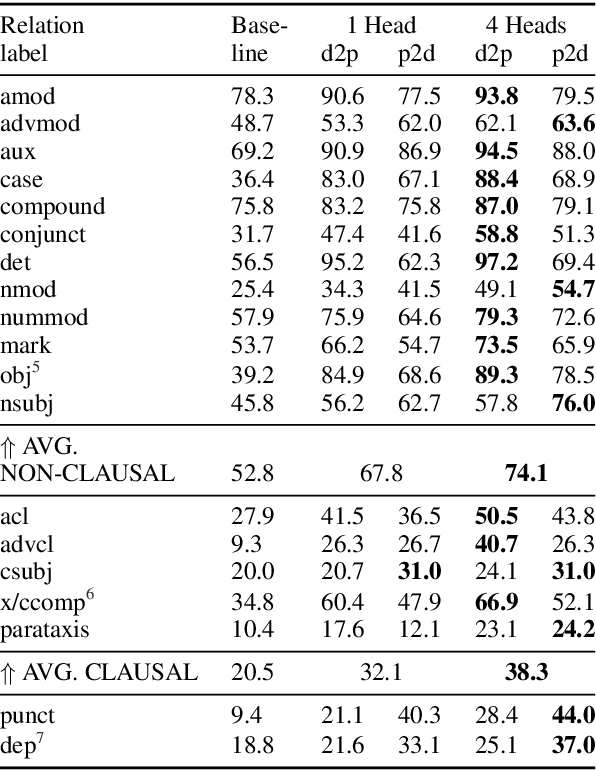
This work focuses on analyzing the form and extent of syntactic abstraction captured by BERT by extracting labeled dependency trees from self-attentions. Previous work showed that individual BERT heads tend to encode particular dependency relation types. We extend these findings by explicitly comparing BERT relations to Universal Dependencies (UD) annotations, showing that they often do not match one-to-one. We suggest a method for relation identification and syntactic tree construction. Our approach produces significantly more consistent dependency trees than previous work, showing that it better explains the syntactic abstractions in BERT. At the same time, it can be successfully applied with only a minimal amount of supervision and generalizes well across languages.
On the Language Neutrality of Pre-trained Multilingual Representations
Apr 23, 2020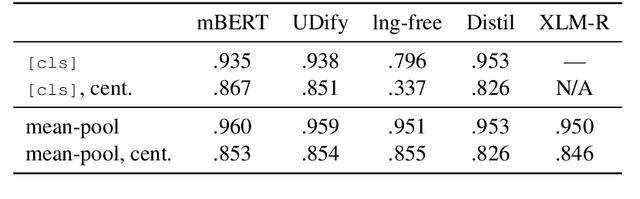
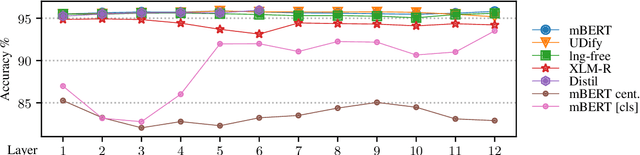


Multilingual contextual embeddings, such as multilingual BERT (mBERT) and XLM-RoBERTa, have proved useful for many multi-lingual tasks. Previous work probed the cross-linguality of the representations indirectly using zero-shot transfer learning on morphological and syntactic tasks. We instead focus on the language-neutrality of mBERT with respect to lexical semantics. Our results show that contextual embeddings are more language-neutral and in general more informative than aligned static word-type embeddings which are explicitly trained for language neutrality. Contextual embeddings are still by default only moderately language-neutral, however, we show two simple methods for achieving stronger language neutrality: first, by unsupervised centering of the representation for languages, and second by fitting an explicit projection on small parallel data. In addition, we show how to reach state-of-the-art accuracy on language identification and word alignment in parallel sentences.
How Language-Neutral is Multilingual BERT?
Nov 08, 2019


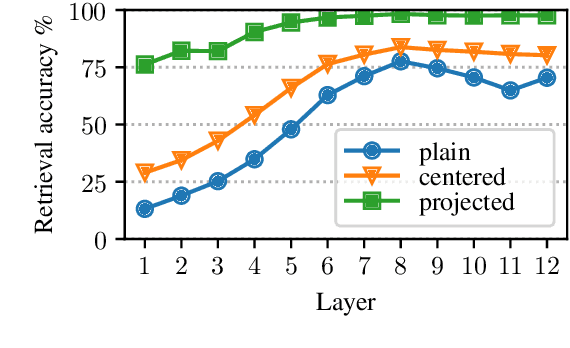
Multilingual BERT (mBERT) provides sentence representations for 104 languages, which are useful for many multi-lingual tasks. Previous work probed the cross-linguality of mBERT using zero-shot transfer learning on morphological and syntactic tasks. We instead focus on the semantic properties of mBERT. We show that mBERT representations can be split into a language-specific component and a language-neutral component, and that the language-neutral component is sufficiently general in terms of modeling semantics to allow high-accuracy word-alignment and sentence retrieval but is not yet good enough for the more difficult task of MT quality estimation. Our work presents interesting challenges which must be solved to build better language-neutral representations, particularly for tasks requiring linguistic transfer of semantics.
Unsupervised Lemmatization as Embeddings-Based Word Clustering
Aug 22, 2019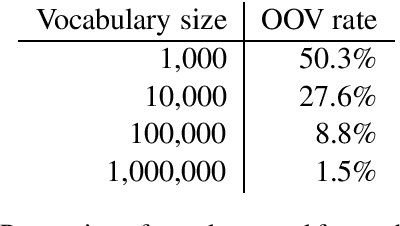
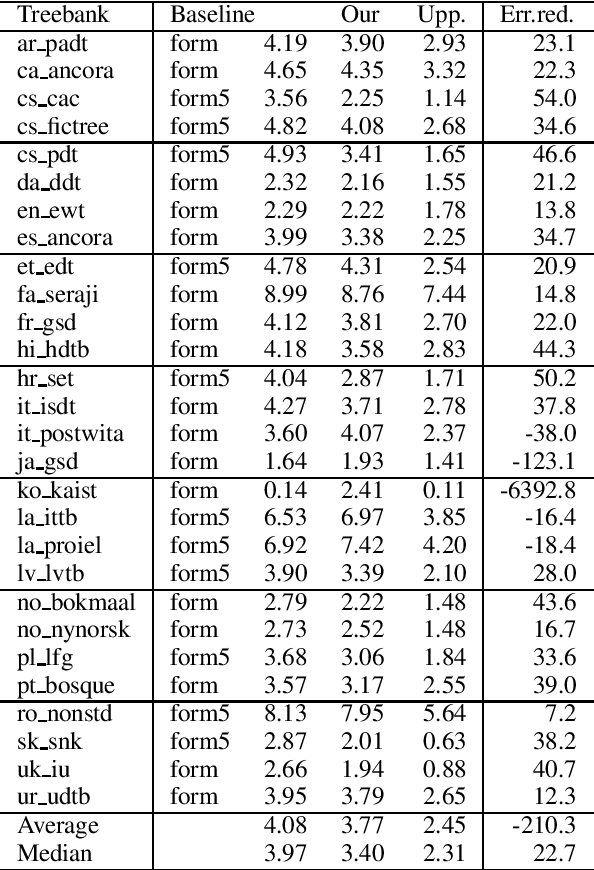
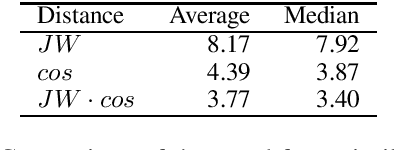
We focus on the task of unsupervised lemmatization, i.e. grouping together inflected forms of one word under one label (a lemma) without the use of annotated training data. We propose to perform agglomerative clustering of word forms with a novel distance measure. Our distance measure is based on the observation that inflections of the same word tend to be similar both string-wise and in meaning. We therefore combine word embedding cosine similarity, serving as a proxy to the meaning similarity, with Jaro-Winkler edit distance. Our experiments on 23 languages show our approach to be promising, surpassing the baseline on 23 of the 28 evaluation datasets.