 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHint-Augmented Re-ranking: Efficient Product Search using LLM-Based Query Decomposition
Nov 17, 2025Search queries with superlatives (e.g., best, most popular) require comparing candidates across multiple dimensions, demanding linguistic understanding and domain knowledge. We show that LLMs can uncover latent intent behind these expressions in e-commerce queries through a framework that extracts structured interpretations or hints. Our approach decomposes queries into attribute-value hints generated concurrently with retrieval, enabling efficient integration into the ranking pipeline. Our method improves search performanc eby 10.9 points in MAP and ranking by 5.9 points in MRR over baselines. Since direct LLM-based reranking faces prohibitive latency, we develop an efficient approach transferring superlative interpretations to lightweight models. Our findings provide insights into how superlative semantics can be represented and transferred between models, advancing linguistic interpretation in retrieval systems while addressing practical deployment constraints.
Calibrated Principal Component Regression
Oct 21, 2025We propose a new method for statistical inference in generalized linear models. In the overparameterized regime, Principal Component Regression (PCR) reduces variance by projecting high-dimensional data to a low-dimensional principal subspace before fitting. However, PCR incurs truncation bias whenever the true regression vector has mass outside the retained principal components (PC). To mitigate the bias, we propose Calibrated Principal Component Regression (CPCR), which first learns a low-variance prior in the PC subspace and then calibrates the model in the original feature space via a centered Tikhonov step. CPCR leverages cross-fitting and controls the truncation bias by softening PCR's hard cutoff. Theoretically, we calculate the out-of-sample risk in the random matrix regime, which shows that CPCR outperforms standard PCR when the regression signal has non-negligible components in low-variance directions. Empirically, CPCR consistently improves prediction across multiple overparameterized problems. The results highlight CPCR's stability and flexibility in modern overparameterized settings.
Domain Generalization: A Tale of Two ERMs
Oct 06, 2025Domain generalization (DG) is the problem of generalizing from several distributions (or domains), for which labeled training data are available, to a new test domain for which no labeled data is available. A common finding in the DG literature is that it is difficult to outperform empirical risk minimization (ERM) on the pooled training data. In this work, we argue that this finding has primarily been reported for datasets satisfying a \emph{covariate shift} assumption. When the dataset satisfies a \emph{posterior drift} assumption instead, we show that ``domain-informed ERM,'' wherein feature vectors are augmented with domain-specific information, outperforms pooling ERM. These claims are supported by a theoretical framework and experiments on language and vision tasks.
GDTB: Genre Diverse Data for English Shallow Discourse Parsing across Modalities, Text Types, and Domains
Nov 01, 2024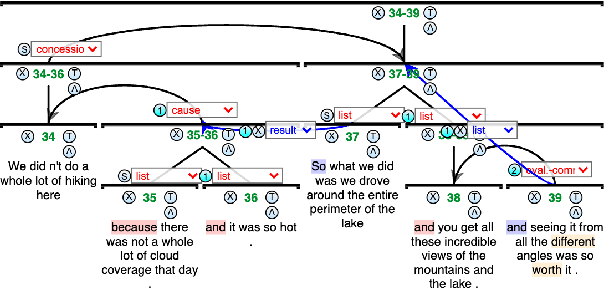
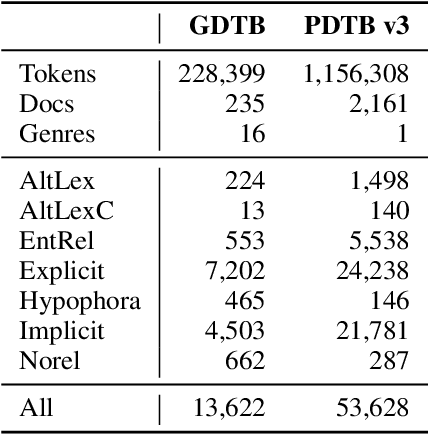
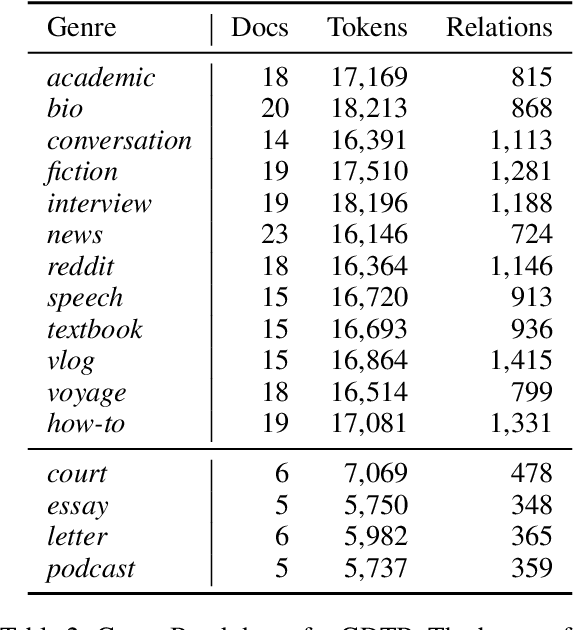
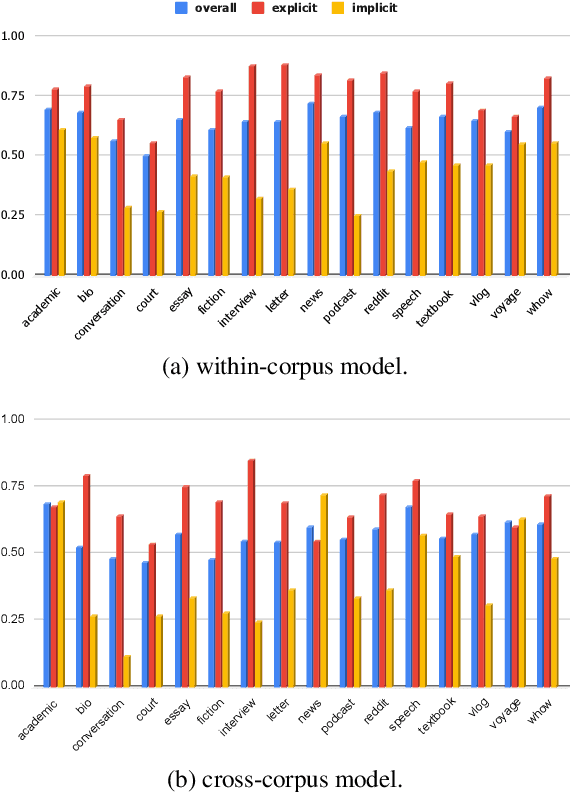
Work on shallow discourse parsing in English has focused on the Wall Street Journal corpus, the only large-scale dataset for the language in the PDTB framework. However, the data is not openly available, is restricted to the news domain, and is by now 35 years old. In this paper, we present and evaluate a new open-access, multi-genre benchmark for PDTB-style shallow discourse parsing, based on the existing UD English GUM corpus, for which discourse relation annotations in other frameworks already exist. In a series of experiments on cross-domain relation classification, we show that while our dataset is compatible with PDTB, substantial out-of-domain degradation is observed, which can be alleviated by joint training on both datasets.
Label Noise: Ignorance Is Bliss
Oct 31, 2024We establish a new theoretical framework for learning under multi-class, instance-dependent label noise. This framework casts learning with label noise as a form of domain adaptation, in particular, domain adaptation under posterior drift. We introduce the concept of \emph{relative signal strength} (RSS), a pointwise measure that quantifies the transferability from noisy to clean posterior. Using RSS, we establish nearly matching upper and lower bounds on the excess risk. Our theoretical findings support the simple \emph{Noise Ignorant Empirical Risk Minimization (NI-ERM)} principle, which minimizes empirical risk while ignoring label noise. Finally, we translate this theoretical insight into practice: by using NI-ERM to fit a linear classifier on top of a self-supervised feature extractor, we achieve state-of-the-art performance on the CIFAR-N data challenge.
SPLICE: A Singleton-Enhanced PipeLIne for Coreference REsolution
Mar 25, 2024



Singleton mentions, i.e.~entities mentioned only once in a text, are important to how humans understand discourse from a theoretical perspective. However previous attempts to incorporate their detection in end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention spans in the OntoNotes benchmark. This paper addresses this limitation by combining predicted mentions from existing nested NER systems and features derived from OntoNotes syntax trees. With this approach, we create a near approximation of the OntoNotes dataset with all singleton mentions, achieving ~94% recall on a sample of gold singletons. We then propose a two-step neural mention and coreference resolution system, named SPLICE, and compare its performance to the end-to-end approach in two scenarios: the OntoNotes test set and the out-of-domain (OOD) OntoGUM corpus. Results indicate that reconstructed singleton training yields results comparable to end-to-end systems for OntoNotes, while improving OOD stability (+1.1 avg. F1). We conduct error analysis for mention detection and delve into its impact on coreference clustering, revealing that precision improvements deliver more substantial benefits than increases in recall for resolving coreference chains.
Can Large Language Models Understand Context?
Feb 01, 2024


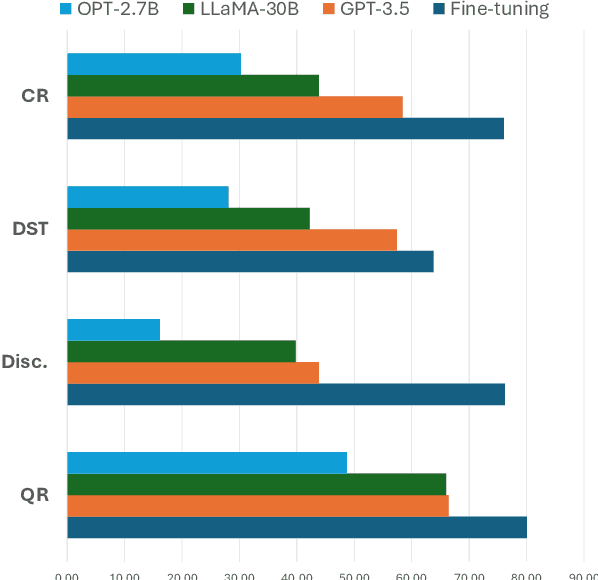
Understanding context is key to understanding human language, an ability which Large Language Models (LLMs) have been increasingly seen to demonstrate to an impressive extent. However, though the evaluation of LLMs encompasses various domains within the realm of Natural Language Processing, limited attention has been paid to probing their linguistic capability of understanding contextual features. This paper introduces a context understanding benchmark by adapting existing datasets to suit the evaluation of generative models. This benchmark comprises of four distinct tasks and nine datasets, all featuring prompts designed to assess the models' ability to understand context. First, we evaluate the performance of LLMs under the in-context learning pretraining scenario. Experimental results indicate that pre-trained dense models struggle with understanding more nuanced contextual features when compared to state-of-the-art fine-tuned models. Second, as LLM compression holds growing significance in both research and real-world applications, we assess the context understanding of quantized models under in-context-learning settings. We find that 3-bit post-training quantization leads to varying degrees of performance reduction on our benchmark. We conduct an extensive analysis of these scenarios to substantiate our experimental results.
Incorporating Singletons and Mention-based Features in Coreference Resolution via Multi-task Learning for Better Generalization
Sep 20, 2023



Previous attempts to incorporate a mention detection step into end-to-end neural coreference resolution for English have been hampered by the lack of singleton mention span data as well as other entity information. This paper presents a coreference model that learns singletons as well as features such as entity type and information status via a multi-task learning-based approach. This approach achieves new state-of-the-art scores on the OntoGUM benchmark (+2.7 points) and increases robustness on multiple out-of-domain datasets (+2.3 points on average), likely due to greater generalizability for mention detection and utilization of more data from singletons when compared to only coreferent mention pair matching.
Fusing Sparsity with Deep Learning for Rotating Scatter Mask Gamma Imaging
Jul 29, 2023Many nuclear safety applications need fast, portable, and accurate imagers to better locate radiation sources. The Rotating Scatter Mask (RSM) system is an emerging device with the potential to meet these needs. The main challenge is the under-determined nature of the data acquisition process: the dimension of the measured signal is far less than the dimension of the image to be reconstructed. To address this challenge, this work aims to fuse model-based sparsity-promoting regularization and a data-driven deep neural network denoising image prior to perform image reconstruction. An efficient algorithm is developed and produces superior reconstructions relative to current approaches.
GENTLE: A Genre-Diverse Multilayer Challenge Set for English NLP and Linguistic Evaluation
Jun 03, 2023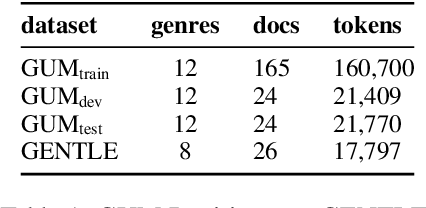
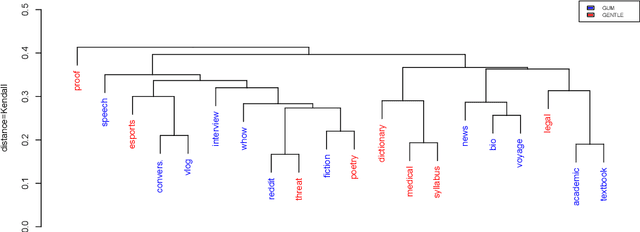
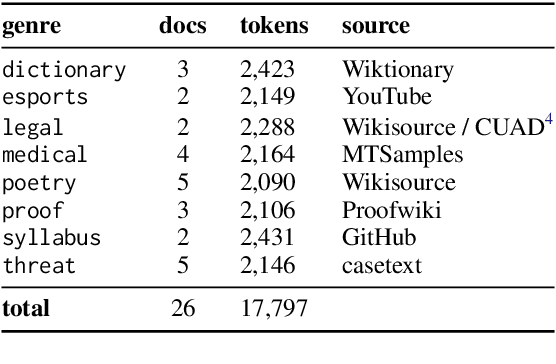
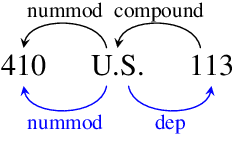
We present GENTLE, a new mixed-genre English challenge corpus totaling 17K tokens and consisting of 8 unusual text types for out-of domain evaluation: dictionary entries, esports commentaries, legal documents, medical notes, poetry, mathematical proofs, syllabuses, and threat letters. GENTLE is manually annotated for a variety of popular NLP tasks, including syntactic dependency parsing, entity recognition, coreference resolution, and discourse parsing. We evaluate state-of-the-art NLP systems on GENTLE and find severe degradation for at least some genres in their performance on all tasks, which indicates GENTLE's utility as an evaluation dataset for NLP systems.