 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich course? Discourse! Teaching Discourse and Generation in the Era of LLMs
Feb 02, 2026The field of NLP has undergone vast, continuous transformations over the past few years, sparking debates going beyond discipline boundaries. This begs important questions in education: how do we design courses that bridge sub-disciplines in this shifting landscape? This paper explores this question from the angle of discourse processing, an area with rich linguistic insights and computational models for the intentional, attentional, and coherence structure of language. Discourse is highly relevant for open-ended or long-form text generation, yet this connection is under-explored in existing undergraduate curricula. We present a new course, "Computational Discourse and Natural Language Generation". The course is collaboratively designed by a team with complementary expertise and was offered for the first time in Fall 2025 as an upper-level undergraduate course, cross-listed between Linguistics and Computer Science. Our philosophy is to deeply integrate the theoretical and empirical aspects, and create an exploratory mindset inside the classroom and in the assignments. This paper describes the course in detail and concludes with takeaways from an independent survey as well as our vision for future directions.
Evaluation Should Not Ignore Variation: On the Impact of Reference Set Choice on Summarization Metrics
Jun 17, 2025Human language production exhibits remarkable richness and variation, reflecting diverse communication styles and intents. However, this variation is often overlooked in summarization evaluation. While having multiple reference summaries is known to improve correlation with human judgments, the impact of using different reference sets on reference-based metrics has not been systematically investigated. This work examines the sensitivity of widely used reference-based metrics in relation to the choice of reference sets, analyzing three diverse multi-reference summarization datasets: SummEval, GUMSum, and DUC2004. We demonstrate that many popular metrics exhibit significant instability. This instability is particularly concerning for n-gram-based metrics like ROUGE, where model rankings vary depending on the reference sets, undermining the reliability of model comparisons. We also collect human judgments on LLM outputs for genre-diverse data and examine their correlation with metrics to supplement existing findings beyond newswire summaries, finding weak-to-no correlation. Taken together, we recommend incorporating reference set variation into summarization evaluation to enhance consistency alongside correlation with human judgments, especially when evaluating LLMs.
Threading the Needle: Reweaving Chain-of-Thought Reasoning to Explain Human Label Variation
May 29, 2025



The recent rise of reasoning-tuned Large Language Models (LLMs)--which generate chains of thought (CoTs) before giving the final answer--has attracted significant attention and offers new opportunities for gaining insights into human label variation, which refers to plausible differences in how multiple annotators label the same data instance. Prior work has shown that LLM-generated explanations can help align model predictions with human label distributions, but typically adopt a reverse paradigm: producing explanations based on given answers. In contrast, CoTs provide a forward reasoning path that may implicitly embed rationales for each answer option, before generating the answers. We thus propose a novel LLM-based pipeline enriched with linguistically-grounded discourse segmenters to extract supporting and opposing statements for each answer option from CoTs with improved accuracy. We also propose a rank-based HLV evaluation framework that prioritizes the ranking of answers over exact scores, which instead favor direct comparison of label distributions. Our method outperforms a direct generation method as well as baselines on three datasets, and shows better alignment of ranking methods with humans, highlighting the effectiveness of our approach.
Probing LLMs for Multilingual Discourse Generalization Through a Unified Label Set
Mar 13, 2025
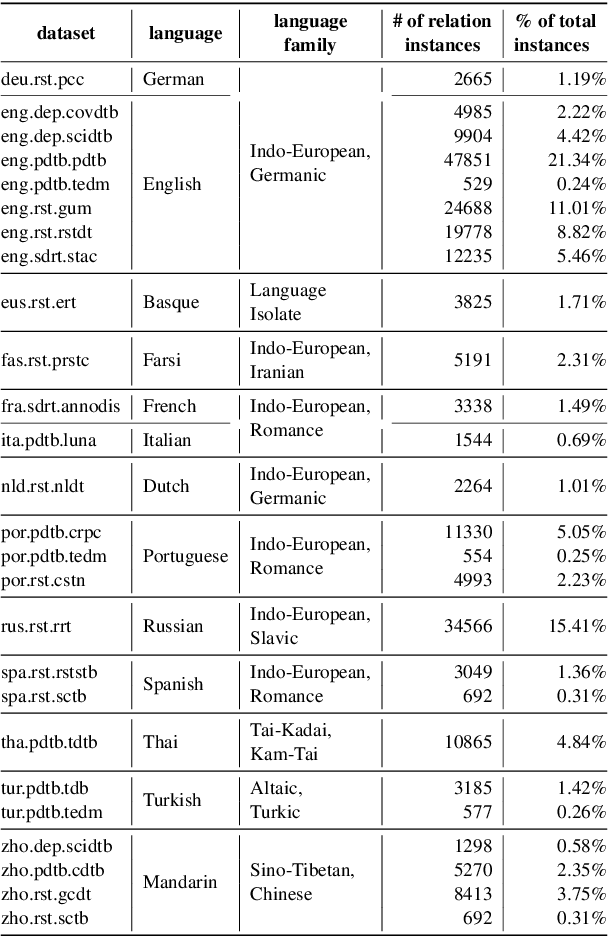
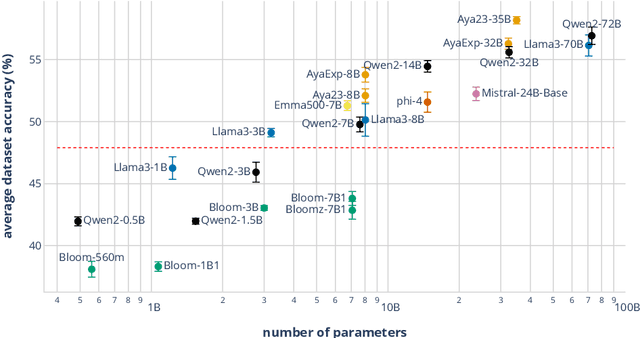
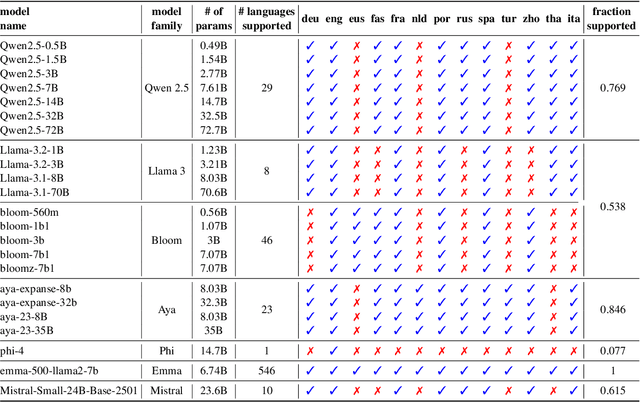
Discourse understanding is essential for many NLP tasks, yet most existing work remains constrained by framework-dependent discourse representations. This work investigates whether large language models (LLMs) capture discourse knowledge that generalizes across languages and frameworks. We address this question along two dimensions: (1) developing a unified discourse relation label set to facilitate cross-lingual and cross-framework discourse analysis, and (2) probing LLMs to assess whether they encode generalizable discourse abstractions. Using multilingual discourse relation classification as a testbed, we examine a comprehensive set of 23 LLMs of varying sizes and multilingual capabilities. Our results show that LLMs, especially those with multilingual training corpora, can generalize discourse information across languages and frameworks. Further layer-wise analyses reveal that language generalization at the discourse level is most salient in the intermediate layers. Lastly, our error analysis provides an account of challenging relation classes.
Pragmatics in the Era of Large Language Models: A Survey on Datasets, Evaluation, Opportunities and Challenges
Feb 17, 2025Understanding pragmatics-the use of language in context-is crucial for developing NLP systems capable of interpreting nuanced language use. Despite recent advances in language technologies, including large language models, evaluating their ability to handle pragmatic phenomena such as implicatures and references remains challenging. To advance pragmatic abilities in models, it is essential to understand current evaluation trends and identify existing limitations. In this survey, we provide a comprehensive review of resources designed for evaluating pragmatic capabilities in NLP, categorizing datasets by the pragmatics phenomena they address. We analyze task designs, data collection methods, evaluation approaches, and their relevance to real-world applications. By examining these resources in the context of modern language models, we highlight emerging trends, challenges, and gaps in existing benchmarks. Our survey aims to clarify the landscape of pragmatic evaluation and guide the development of more comprehensive and targeted benchmarks, ultimately contributing to more nuanced and context-aware NLP models.
GDTB: Genre Diverse Data for English Shallow Discourse Parsing across Modalities, Text Types, and Domains
Nov 01, 2024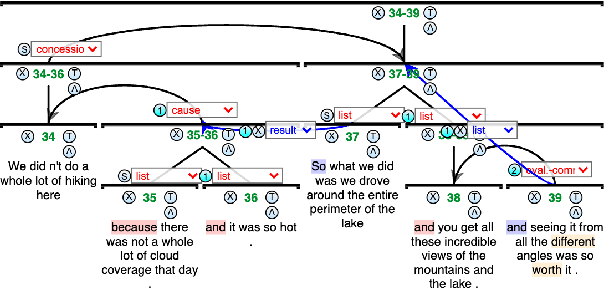
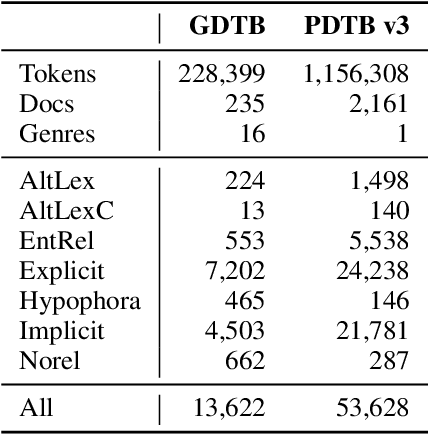
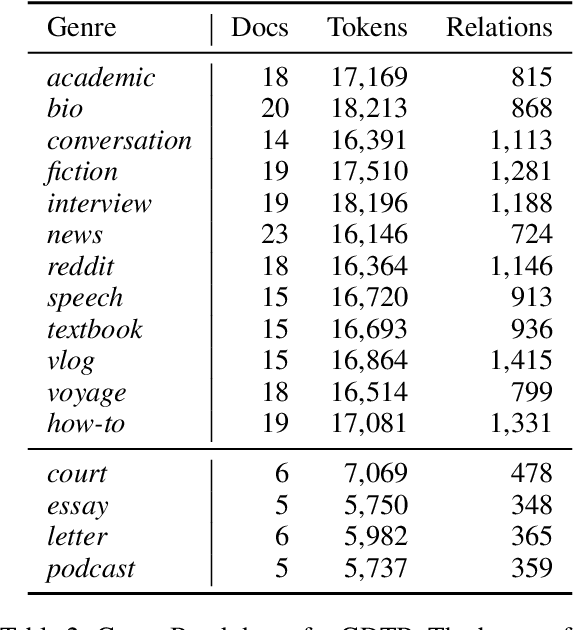
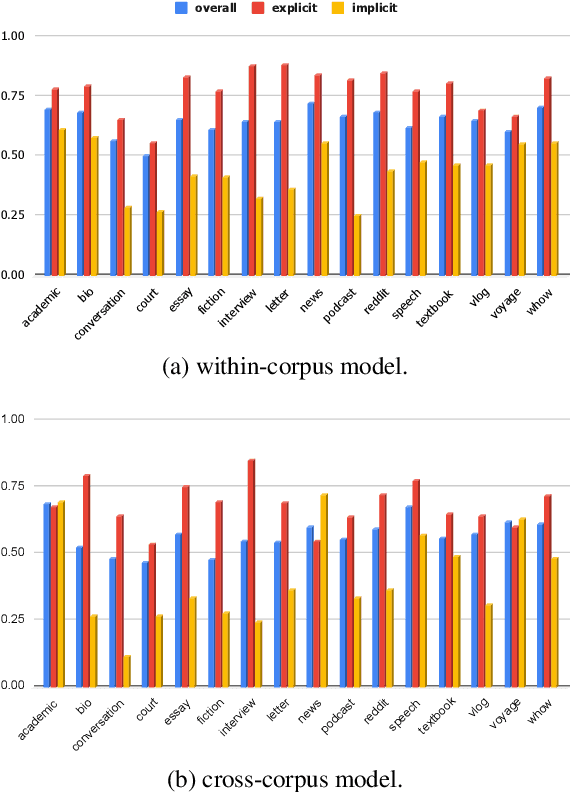
Work on shallow discourse parsing in English has focused on the Wall Street Journal corpus, the only large-scale dataset for the language in the PDTB framework. However, the data is not openly available, is restricted to the news domain, and is by now 35 years old. In this paper, we present and evaluate a new open-access, multi-genre benchmark for PDTB-style shallow discourse parsing, based on the existing UD English GUM corpus, for which discourse relation annotations in other frameworks already exist. In a series of experiments on cross-domain relation classification, we show that while our dataset is compatible with PDTB, substantial out-of-domain degradation is observed, which can be alleviated by joint training on both datasets.
eRST: A Signaled Graph Theory of Discourse Relations and Organization
Mar 20, 2024


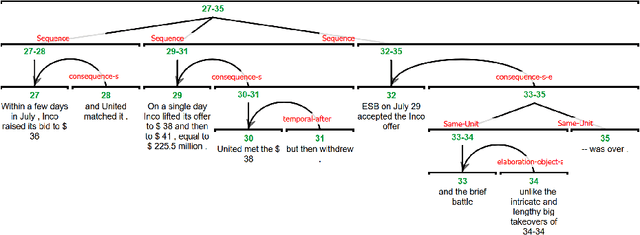
In this article we present Enhanced Rhetorical Structure Theory (eRST), a new theoretical framework for computational discourse analysis, based on an expansion of Rhetorical Structure Theory (RST). The framework encompasses discourse relation graphs with tree-breaking, nonprojective and concurrent relations, as well as implicit and explicit signals which give explainable rationales to our analyses. We survey shortcomings of RST and other existing frameworks, such as Segmented Discourse Representation Theory (SDRT), the Penn Discourse Treebank (PDTB) and Discourse Dependencies, and address these using constructs in the proposed theory. We provide annotation, search and visualization tools for data, and present and evaluate a freely available corpus of English annotated according to our framework, encompassing 12 spoken and written genres with over 200K tokens. Finally, we discuss automatic parsing, evaluation metrics and applications for data in our framework.
What's Hard in English RST Parsing? Predictive Models for Error Analysis
Sep 10, 2023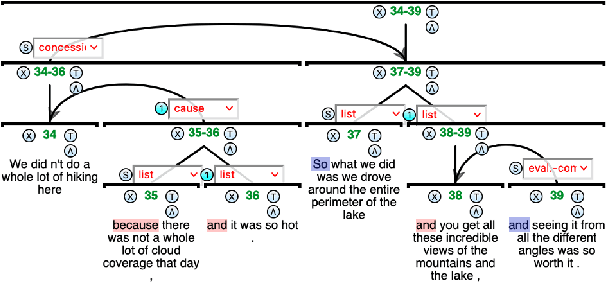
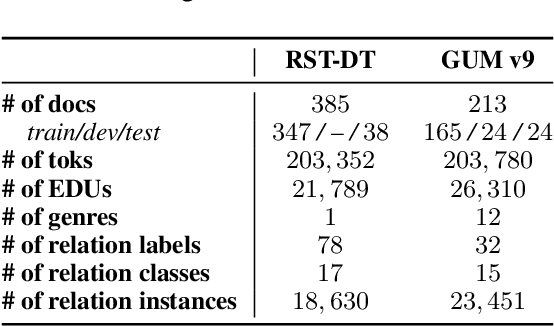
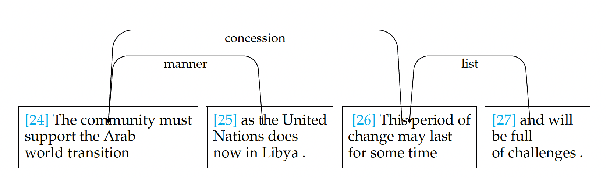
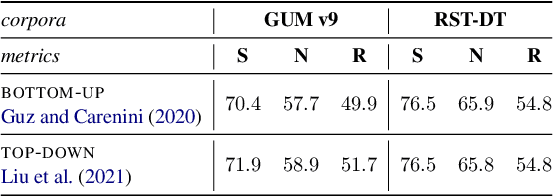
Despite recent advances in Natural Language Processing (NLP), hierarchical discourse parsing in the framework of Rhetorical Structure Theory remains challenging, and our understanding of the reasons for this are as yet limited. In this paper, we examine and model some of the factors associated with parsing difficulties in previous work: the existence of implicit discourse relations, challenges in identifying long-distance relations, out-of-vocabulary items, and more. In order to assess the relative importance of these variables, we also release two annotated English test-sets with explicit correct and distracting discourse markers associated with gold standard RST relations. Our results show that as in shallow discourse parsing, the explicit/implicit distinction plays a role, but that long-distance dependencies are the main challenge, while lack of lexical overlap is less of a problem, at least for in-domain parsing. Our final model is able to predict where errors will occur with an accuracy of 76.3% for the bottom-up parser and 76.6% for the top-down parser.
GUMSum: Multi-Genre Data and Evaluation for English Abstractive Summarization
Jun 20, 2023



Automatic summarization with pre-trained language models has led to impressively fluent results, but is prone to 'hallucinations', low performance on non-news genres, and outputs which are not exactly summaries. Targeting ACL 2023's 'Reality Check' theme, we present GUMSum, a small but carefully crafted dataset of English summaries in 12 written and spoken genres for evaluation of abstractive summarization. Summaries are highly constrained, focusing on substitutive potential, factuality, and faithfulness. We present guidelines and evaluate human agreement as well as subjective judgments on recent system outputs, comparing general-domain untuned approaches, a fine-tuned one, and a prompt-based approach, to human performance. Results show that while GPT3 achieves impressive scores, it still underperforms humans, with varying quality across genres. Human judgments reveal different types of errors in supervised, prompted, and human-generated summaries, shedding light on the challenges of producing a good summary.
GENTLE: A Genre-Diverse Multilayer Challenge Set for English NLP and Linguistic Evaluation
Jun 03, 2023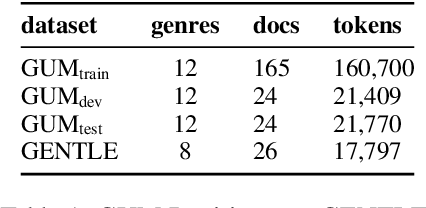
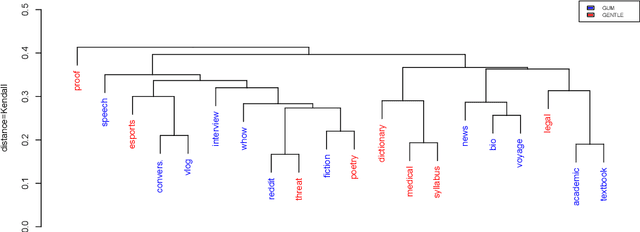
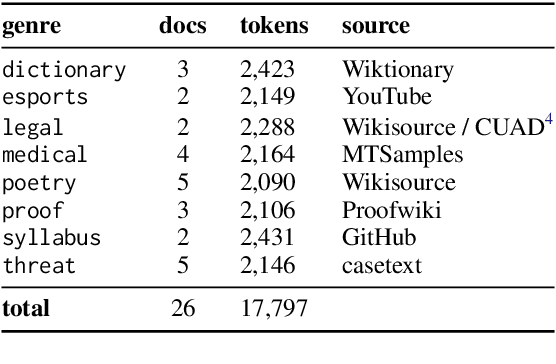
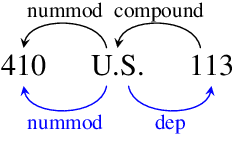
We present GENTLE, a new mixed-genre English challenge corpus totaling 17K tokens and consisting of 8 unusual text types for out-of domain evaluation: dictionary entries, esports commentaries, legal documents, medical notes, poetry, mathematical proofs, syllabuses, and threat letters. GENTLE is manually annotated for a variety of popular NLP tasks, including syntactic dependency parsing, entity recognition, coreference resolution, and discourse parsing. We evaluate state-of-the-art NLP systems on GENTLE and find severe degradation for at least some genres in their performance on all tasks, which indicates GENTLE's utility as an evaluation dataset for NLP systems.