 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpect the Unexpected? Testing the Surprisal of Salient Entities
Apr 12, 2026Previous work examining the Uniform Information Density (UID) hypothesis has shown that while information as measured by surprisal metrics is distributed more or less evenly across documents overall, local discrepancies can arise due to functional pressures corresponding to syntactic and discourse structural constraints. However, work thus far has largely disregarded the relative salience of discourse participants. We fill this gap by studying how overall salience of entities in discourse relates to surprisal using 70K manually annotated mentions across 16 genres of English and a novel minimal-pair prompting method. Our results show that globally salient entities exhibit significantly higher surprisal than non-salient ones, even controlling for position, length, and nesting confounds. Moreover, salient entities systematically reduce surprisal for surrounding content when used as prompts, enhancing document-level predictability. This effect varies by genre, appearing strongest in topic-coherent texts and weakest in conversational contexts. Our findings refine the UID competing pressures framework by identifying global entity salience as a mechanism shaping information distribution in discourse.
Joint Time Series Chain: Detecting Unusual Evolving Trend across Time Series
Feb 14, 2026Time series chain (TSC) is a recently introduced concept that captures the evolving patterns in large scale time series. Informally, a time series chain is a temporally ordered set of subsequences, in which consecutive subsequences in the chain are similar to one another, but the last and the first subsequences maybe be dissimilar. Time series chain has the great potential to reveal latent unusual evolving trend in the time series, or identify precursor of important events in a complex system. Unfortunately, existing definitions of time series chains only consider finding chains in a single time series. As a result, they are likely to miss unexpected evolving patterns in interrupted time series, or across two related time series. To address this limitation, in this work, we introduce a new definition called \textit{Joint Time Series Chain}, which is specially designed for the task of finding unexpected evolving trend across interrupted time series or two related time series. Our definition focuses on mitigating the robustness issues caused by the gap or interruption in the time series. We further propose an effective ranking criterion to identify the best chain. We demonstrate that our proposed approach outperforms existing TSC work in locating unusual evolving patterns through extensive empirical evaluations. We further demonstrate the utility of our work with a real-life manufacturing application from Intel. Our source code is publicly available at the supporting page https://github.com/lizhang-ts/JointTSC .
GUM-SAGE: A Novel Dataset and Approach for Graded Entity Salience Prediction
Apr 15, 2025Determining and ranking the most salient entities in a text is critical for user-facing systems, especially as users increasingly rely on models to interpret long documents they only partially read. Graded entity salience addresses this need by assigning entities scores that reflect their relative importance in a text. Existing approaches fall into two main categories: subjective judgments of salience, which allow for gradient scoring but lack consistency, and summarization-based methods, which define salience as mention-worthiness in a summary, promoting explainability but limiting outputs to binary labels (entities are either summary-worthy or not). In this paper, we introduce a novel approach for graded entity salience that combines the strengths of both approaches. Using an English dataset spanning 12 spoken and written genres, we collect 5 summaries per document and calculate each entity's salience score based on its presence across these summaries. Our approach shows stronger correlation with scores based on human summaries and alignments, and outperforms existing techniques, including LLMs. We release our data and code at https://github.com/jl908069/gum_sum_salience to support further research on graded salient entity extraction.
VSFormer: Value and Shape-Aware Transformer with Prior-Enhanced Self-Attention for Multivariate Time Series Classification
Dec 21, 2024Multivariate time series classification is a crucial task in data mining, attracting growing research interest due to its broad applications. While many existing methods focus on discovering discriminative patterns in time series, real-world data does not always present such patterns, and sometimes raw numerical values can also serve as discriminative features. Additionally, the recent success of Transformer models has inspired many studies. However, when applying to time series classification, the self-attention mechanisms in Transformer models could introduce classification-irrelevant features, thereby compromising accuracy. To address these challenges, we propose a novel method, VSFormer, that incorporates both discriminative patterns (shape) and numerical information (value). In addition, we extract class-specific prior information derived from supervised information to enrich the positional encoding and provide classification-oriented self-attention learning, thereby enhancing its effectiveness. Extensive experiments on all 30 UEA archived datasets demonstrate the superior performance of our method compared to SOTA models. Through ablation studies, we demonstrate the effectiveness of the improved encoding layer and the proposed self-attention mechanism. Finally, We provide a case study on a real-world time series dataset without discriminative patterns to interpret our model.
Interactive Dialogue Agents via Reinforcement Learning on Hindsight Regenerations
Nov 07, 2024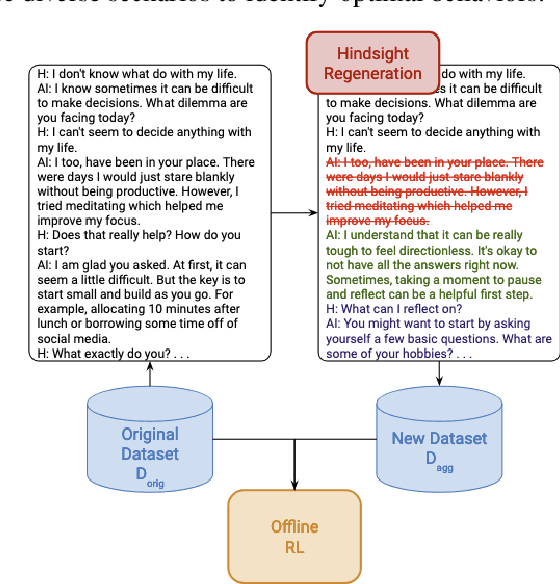

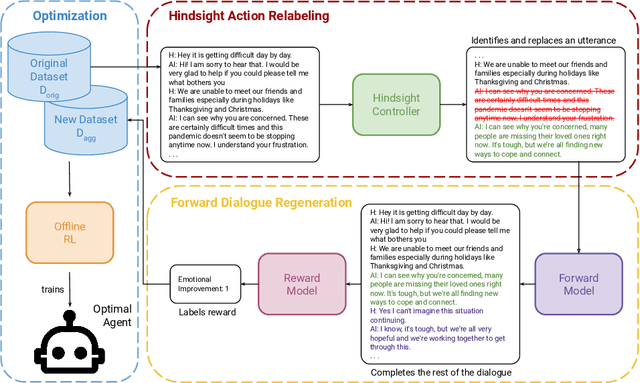
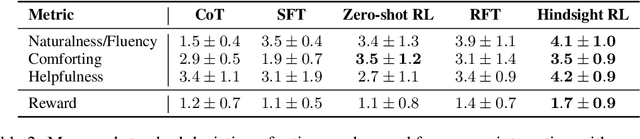
Recent progress on large language models (LLMs) has enabled dialogue agents to generate highly naturalistic and plausible text. However, current LLM language generation focuses on responding accurately to questions and requests with a single effective response. In reality, many real dialogues are interactive, meaning an agent's utterances will influence their conversational partner, elicit information, or change their opinion. Accounting for how an agent can effectively steer a conversation is a crucial ability in many dialogue tasks, from healthcare to preference elicitation. Existing methods for fine-tuning dialogue agents to accomplish such tasks would rely on curating some amount of expert data. However, doing so often requires understanding the underlying cognitive processes of the conversational partner, which is a skill neither humans nor LLMs trained on human data can reliably do. Our key insight is that while LLMs may not be adept at identifying effective strategies for steering conversations a priori, or in the middle of an ongoing conversation, they can do so post-hoc, or in hindsight, after seeing how their conversational partner responds. We use this fact to rewrite and augment existing suboptimal data, and train via offline reinforcement learning (RL) an agent that outperforms both prompting and learning from unaltered human demonstrations. We apply our approach to two domains that require understanding human mental state, intelligent interaction, and persuasion: mental health support, and soliciting charitable donations. Our results in a user study with real humans show that our approach greatly outperforms existing state-of-the-art dialogue agents.
GDTB: Genre Diverse Data for English Shallow Discourse Parsing across Modalities, Text Types, and Domains
Nov 01, 2024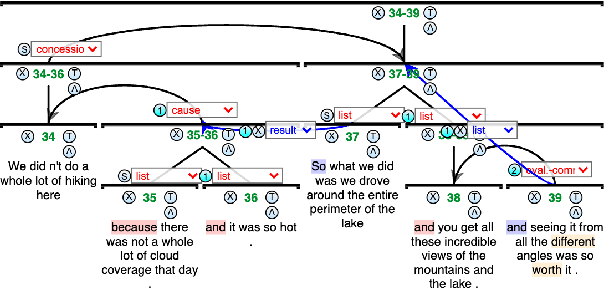
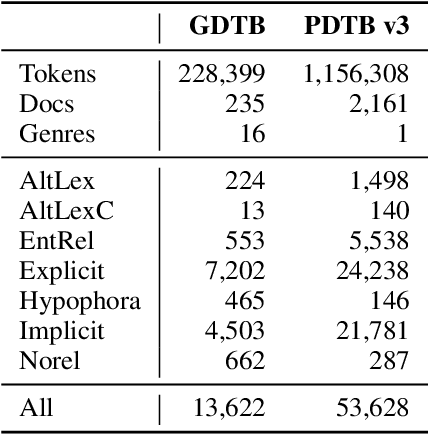
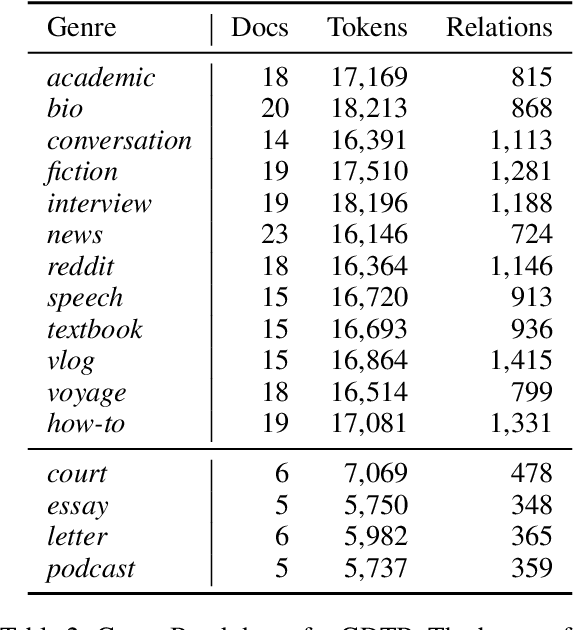
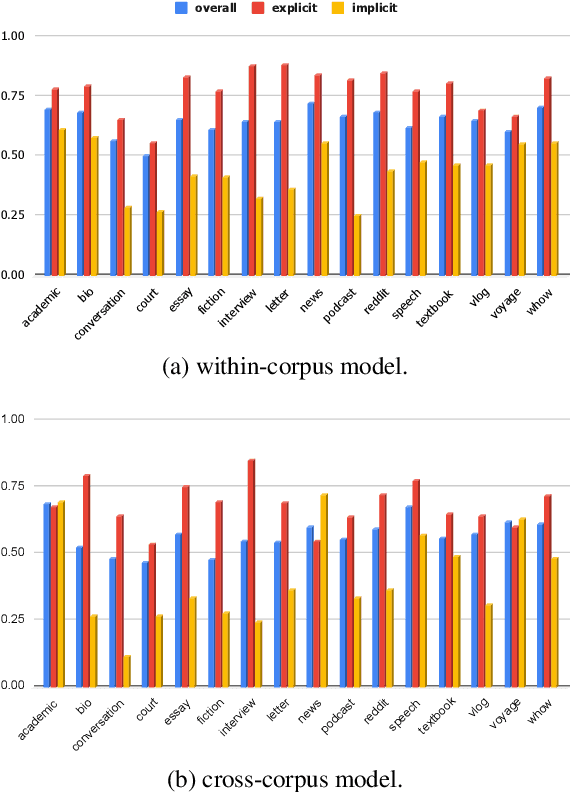
Work on shallow discourse parsing in English has focused on the Wall Street Journal corpus, the only large-scale dataset for the language in the PDTB framework. However, the data is not openly available, is restricted to the news domain, and is by now 35 years old. In this paper, we present and evaluate a new open-access, multi-genre benchmark for PDTB-style shallow discourse parsing, based on the existing UD English GUM corpus, for which discourse relation annotations in other frameworks already exist. In a series of experiments on cross-domain relation classification, we show that while our dataset is compatible with PDTB, substantial out-of-domain degradation is observed, which can be alleviated by joint training on both datasets.
RandomNet: Clustering Time Series Using Untrained Deep Neural Networks
Aug 15, 2024Neural networks are widely used in machine learning and data mining. Typically, these networks need to be trained, implying the adjustment of weights (parameters) within the network based on the input data. In this work, we propose a novel approach, RandomNet, that employs untrained deep neural networks to cluster time series. RandomNet uses different sets of random weights to extract diverse representations of time series and then ensembles the clustering relationships derived from these different representations to build the final clustering results. By extracting diverse representations, our model can effectively handle time series with different characteristics. Since all parameters are randomly generated, no training is required during the process. We provide a theoretical analysis of the effectiveness of the method. To validate its performance, we conduct extensive experiments on all of the 128 datasets in the well-known UCR time series archive and perform statistical analysis of the results. These datasets have different sizes, sequence lengths, and they are from diverse fields. The experimental results show that the proposed method is competitive compared with existing state-of-the-art methods.
GUMsley: Evaluating Entity Salience in Summarization for 12 English Genres
Jan 31, 2024As NLP models become increasingly capable of understanding documents in terms of coherent entities rather than strings, obtaining the most salient entities for each document is not only an important end task in itself but also vital for Information Retrieval (IR) and other downstream applications such as controllable summarization. In this paper, we present and evaluate GUMsley, the first entity salience dataset covering all named and non-named salient entities for 12 genres of English text, aligned with entity types, Wikification links and full coreference resolution annotations. We promote a strict definition of salience using human summaries and demonstrate high inter-annotator agreement for salience based on whether a source entity is mentioned in the summary. Our evaluation shows poor performance by pre-trained SOTA summarization models and zero-shot LLM prompting in capturing salient entities in generated summaries. We also show that predicting or providing salient entities to several model architectures enhances performance and helps derive higher-quality summaries by alleviating the entity hallucination problem in existing abstractive summarization.
GENTLE: A Genre-Diverse Multilayer Challenge Set for English NLP and Linguistic Evaluation
Jun 03, 2023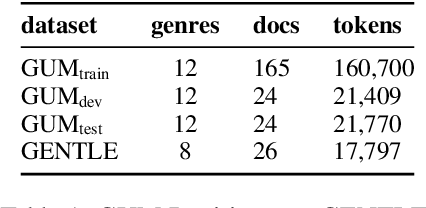
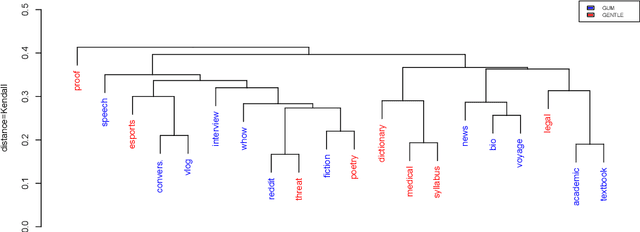
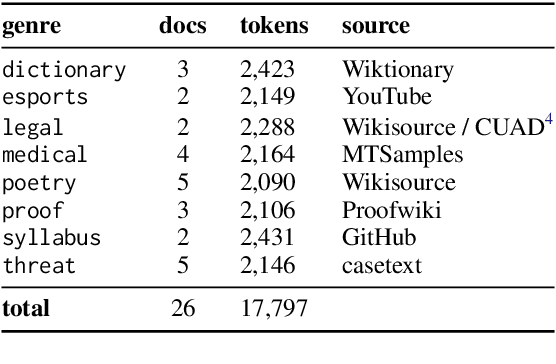
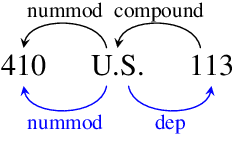
We present GENTLE, a new mixed-genre English challenge corpus totaling 17K tokens and consisting of 8 unusual text types for out-of domain evaluation: dictionary entries, esports commentaries, legal documents, medical notes, poetry, mathematical proofs, syllabuses, and threat letters. GENTLE is manually annotated for a variety of popular NLP tasks, including syntactic dependency parsing, entity recognition, coreference resolution, and discourse parsing. We evaluate state-of-the-art NLP systems on GENTLE and find severe degradation for at least some genres in their performance on all tasks, which indicates GENTLE's utility as an evaluation dataset for NLP systems.
Deep RL at Scale: Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators
May 05, 2023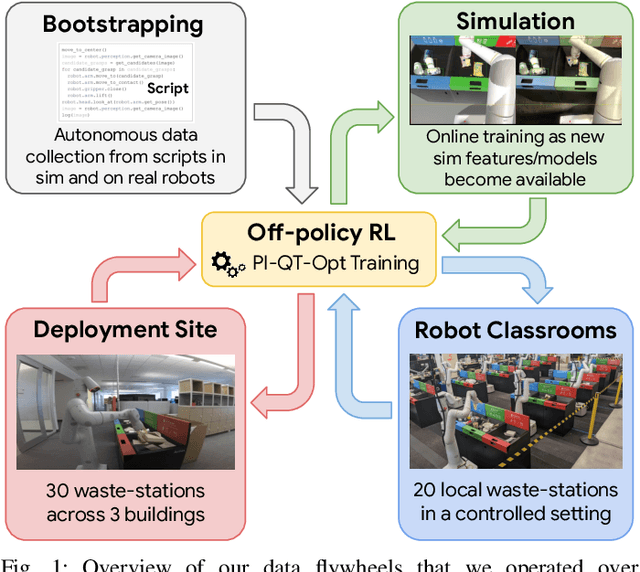

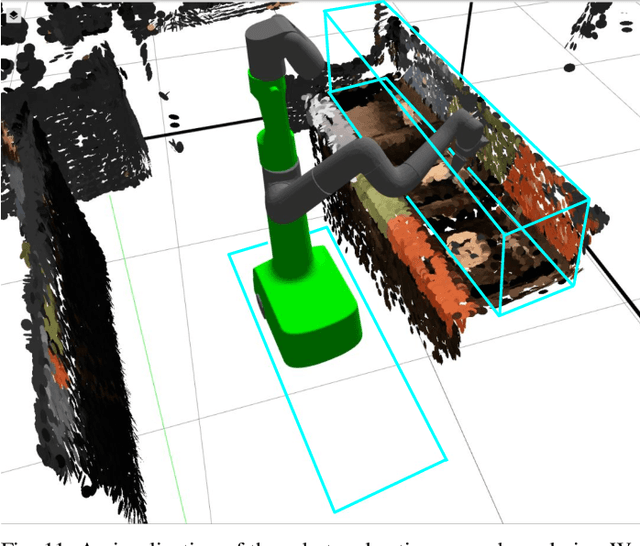

We describe a system for deep reinforcement learning of robotic manipulation skills applied to a large-scale real-world task: sorting recyclables and trash in office buildings. Real-world deployment of deep RL policies requires not only effective training algorithms, but the ability to bootstrap real-world training and enable broad generalization. To this end, our system combines scalable deep RL from real-world data with bootstrapping from training in simulation, and incorporates auxiliary inputs from existing computer vision systems as a way to boost generalization to novel objects, while retaining the benefits of end-to-end training. We analyze the tradeoffs of different design decisions in our system, and present a large-scale empirical validation that includes training on real-world data gathered over the course of 24 months of experimentation, across a fleet of 23 robots in three office buildings, with a total training set of 9527 hours of robotic experience. Our final validation also consists of 4800 evaluation trials across 240 waste station configurations, in order to evaluate in detail the impact of the design decisions in our system, the scaling effects of including more real-world data, and the performance of the method on novel objects. The projects website and videos can be found at \href{http://rl-at-scale.github.io}{rl-at-scale.github.io}.