 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Dialogue Agents via Reinforcement Learning on Hindsight Regenerations
Paper and Code
Nov 07, 2024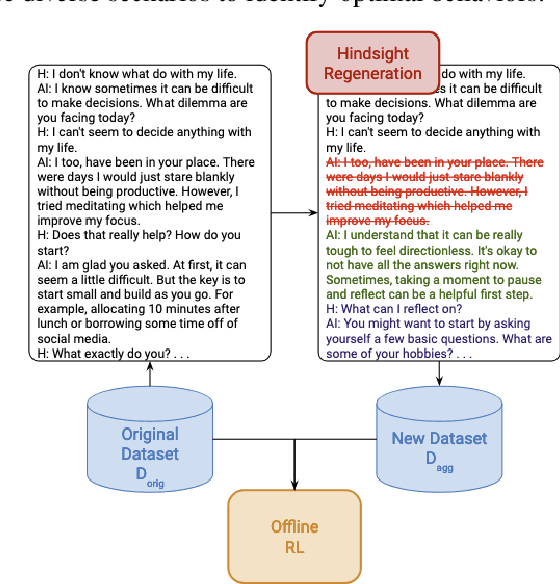

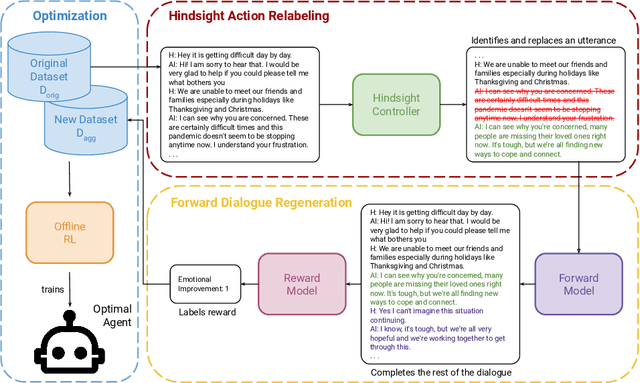
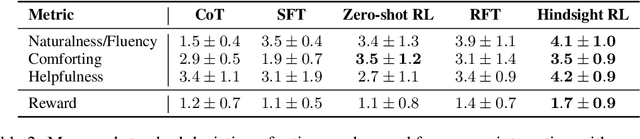
Recent progress on large language models (LLMs) has enabled dialogue agents to generate highly naturalistic and plausible text. However, current LLM language generation focuses on responding accurately to questions and requests with a single effective response. In reality, many real dialogues are interactive, meaning an agent's utterances will influence their conversational partner, elicit information, or change their opinion. Accounting for how an agent can effectively steer a conversation is a crucial ability in many dialogue tasks, from healthcare to preference elicitation. Existing methods for fine-tuning dialogue agents to accomplish such tasks would rely on curating some amount of expert data. However, doing so often requires understanding the underlying cognitive processes of the conversational partner, which is a skill neither humans nor LLMs trained on human data can reliably do. Our key insight is that while LLMs may not be adept at identifying effective strategies for steering conversations a priori, or in the middle of an ongoing conversation, they can do so post-hoc, or in hindsight, after seeing how their conversational partner responds. We use this fact to rewrite and augment existing suboptimal data, and train via offline reinforcement learning (RL) an agent that outperforms both prompting and learning from unaltered human demonstrations. We apply our approach to two domains that require understanding human mental state, intelligent interaction, and persuasion: mental health support, and soliciting charitable donations. Our results in a user study with real humans show that our approach greatly outperforms existing state-of-the-art dialogue agents.