 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning without Search: Refining Frontier LLMs with Offline Goal-Conditioned RL
May 23, 2025
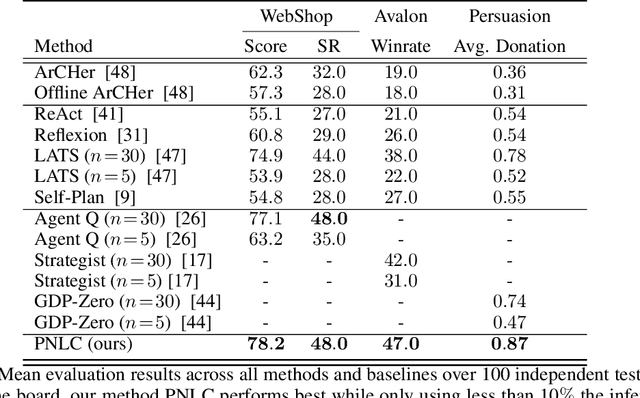
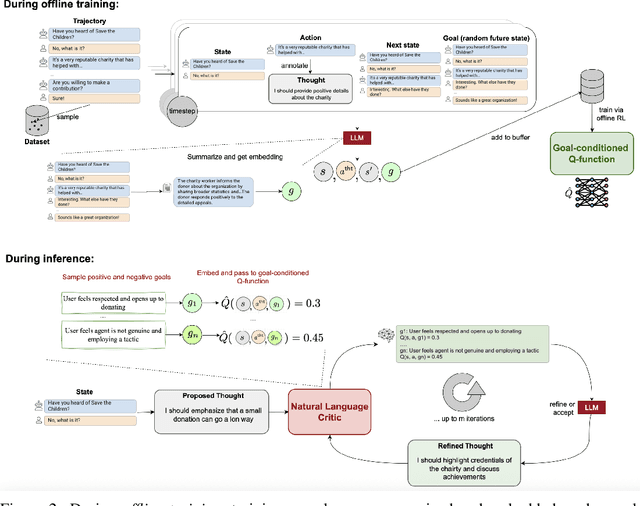
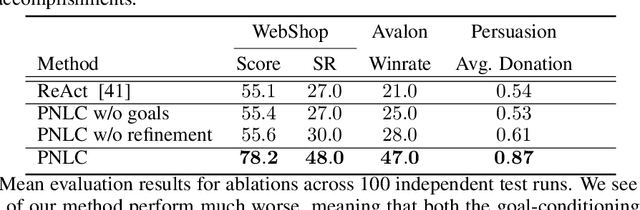
Large language models (LLMs) excel in tasks like question answering and dialogue, but complex tasks requiring interaction, such as negotiation and persuasion, require additional long-horizon reasoning and planning. Reinforcement learning (RL) fine-tuning can enable such planning in principle, but suffers from drawbacks that hinder scalability. In particular, multi-turn RL training incurs high memory and computational costs, which are exacerbated when training LLMs as policies. Furthermore, the largest LLMs do not expose the APIs necessary to be trained in such manner. As a result, modern methods to improve the reasoning of LLMs rely on sophisticated prompting mechanisms rather than RL fine-tuning. To remedy this, we propose a novel approach that uses goal-conditioned value functions to guide the reasoning of LLM agents, that scales even to large API-based models. These value functions predict how a task will unfold given an action, allowing the LLM agent to evaluate multiple possible outcomes, both positive and negative, to plan effectively. In addition, these value functions are trained over reasoning steps rather than full actions, to be a concise and light-weight module that facilitates decision-making in multi-turn interactions. We validate our method on tasks requiring interaction, including tool use, social deduction, and dialogue, demonstrating superior performance over both RL fine-tuning and prompting methods while maintaining efficiency and scalability.
Q-SFT: Q-Learning for Language Models via Supervised Fine-Tuning
Nov 07, 2024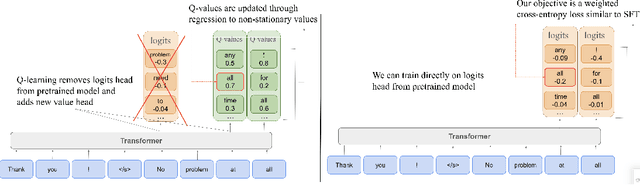



Value-based reinforcement learning (RL) can in principle learn effective policies for a wide range of multi-turn problems, from games to dialogue to robotic control, including via offline RL from static previously collected datasets. However, despite the widespread use of policy gradient methods to train large language models for single turn tasks (e.g., question answering), value-based methods for multi-turn RL in an off-policy or offline setting have proven particularly challenging to scale to the setting of large language models. This setting requires effectively leveraging pretraining, scaling to large architectures with billions of parameters, and training on large datasets, all of which represent major challenges for current value-based RL methods. In this work, we propose a novel offline RL algorithm that addresses these drawbacks, casting Q-learning as a modified supervised fine-tuning (SFT) problem where the probabilities of tokens directly translate to Q-values. In this way we obtain an algorithm that smoothly transitions from maximizing the likelihood of the data during pretraining to learning a near-optimal Q-function during finetuning. Our algorithm has strong theoretical foundations, enjoying performance bounds similar to state-of-the-art Q-learning methods, while in practice utilizing an objective that closely resembles SFT. Because of this, our approach can enjoy the full benefits of the pretraining of language models, without the need to reinitialize any weights before RL finetuning, and without the need to initialize new heads for predicting values or advantages. Empirically, we evaluate our method on both pretrained LLMs and VLMs, on a variety of tasks including both natural language dialogue and robotic manipulation and navigation from images.
Interactive Dialogue Agents via Reinforcement Learning on Hindsight Regenerations
Nov 07, 2024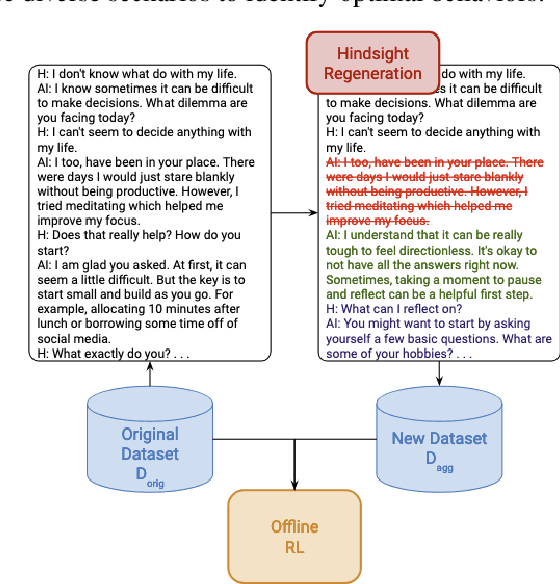

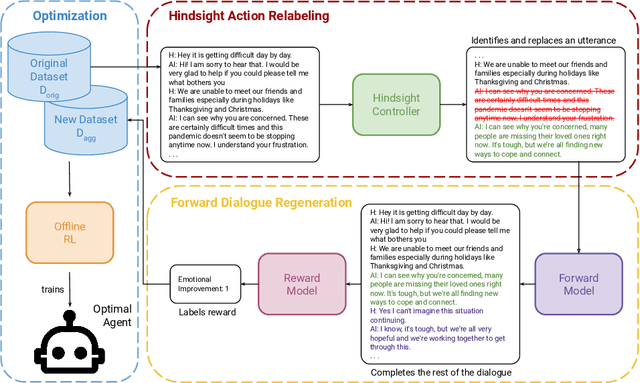
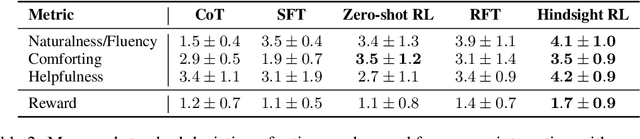
Recent progress on large language models (LLMs) has enabled dialogue agents to generate highly naturalistic and plausible text. However, current LLM language generation focuses on responding accurately to questions and requests with a single effective response. In reality, many real dialogues are interactive, meaning an agent's utterances will influence their conversational partner, elicit information, or change their opinion. Accounting for how an agent can effectively steer a conversation is a crucial ability in many dialogue tasks, from healthcare to preference elicitation. Existing methods for fine-tuning dialogue agents to accomplish such tasks would rely on curating some amount of expert data. However, doing so often requires understanding the underlying cognitive processes of the conversational partner, which is a skill neither humans nor LLMs trained on human data can reliably do. Our key insight is that while LLMs may not be adept at identifying effective strategies for steering conversations a priori, or in the middle of an ongoing conversation, they can do so post-hoc, or in hindsight, after seeing how their conversational partner responds. We use this fact to rewrite and augment existing suboptimal data, and train via offline reinforcement learning (RL) an agent that outperforms both prompting and learning from unaltered human demonstrations. We apply our approach to two domains that require understanding human mental state, intelligent interaction, and persuasion: mental health support, and soliciting charitable donations. Our results in a user study with real humans show that our approach greatly outperforms existing state-of-the-art dialogue agents.
Strategically Conservative Q-Learning
Jun 06, 2024



Offline reinforcement learning (RL) is a compelling paradigm to extend RL's practical utility by leveraging pre-collected, static datasets, thereby avoiding the limitations associated with collecting online interactions. The major difficulty in offline RL is mitigating the impact of approximation errors when encountering out-of-distribution (OOD) actions; doing so ineffectively will lead to policies that prefer OOD actions, which can lead to unexpected and potentially catastrophic results. Despite the variety of works proposed to address this issue, they tend to excessively suppress the value function in and around OOD regions, resulting in overly pessimistic value estimates. In this paper, we propose a novel framework called Strategically Conservative Q-Learning (SCQ) that distinguishes between OOD data that is easy and hard to estimate, ultimately resulting in less conservative value estimates. Our approach exploits the inherent strengths of neural networks to interpolate, while carefully navigating their limitations in extrapolation, to obtain pessimistic yet still property calibrated value estimates. Theoretical analysis also shows that the value function learned by SCQ is still conservative, but potentially much less so than that of Conservative Q-learning (CQL). Finally, extensive evaluation on the D4RL benchmark tasks shows our proposed method outperforms state-of-the-art methods. Our code is available through \url{https://github.com/purewater0901/SCQ}.
LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models
Nov 30, 2023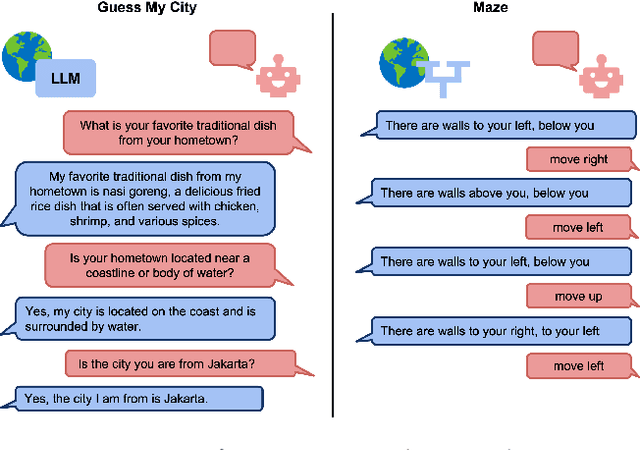
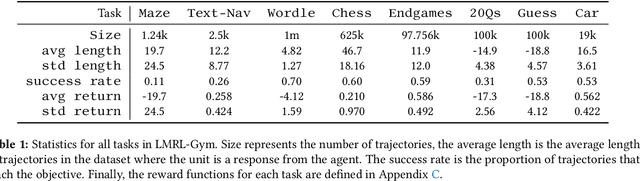
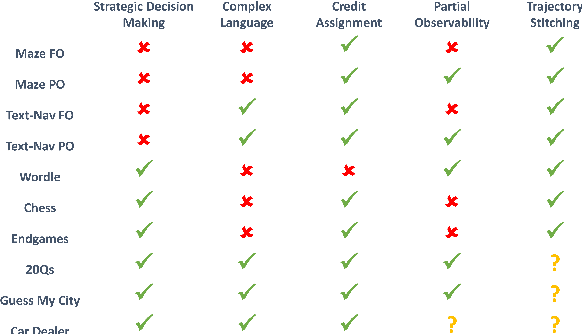
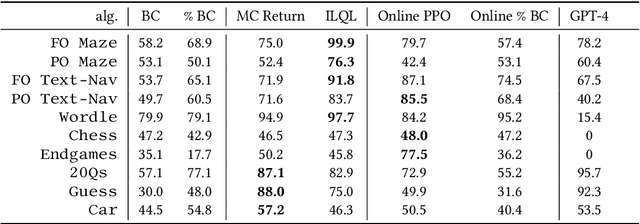
Large language models (LLMs) provide excellent text-generation capabilities, but standard prompting and generation methods generally do not lead to intentional or goal-directed agents and might necessitate considerable prompt tuning. This becomes particularly apparent in multi-turn conversations: even the best current LLMs rarely ask clarifying questions, engage in explicit information gathering, or take actions now that lead to better decisions after multiple turns. Reinforcement learning has the potential to leverage the powerful modeling capabilities of LLMs, as well as their internal representation of textual interactions, to create capable goal-directed language agents. This can enable intentional and temporally extended interactions, such as with humans, through coordinated persuasion and carefully crafted questions, or in goal-directed play through text games to bring about desired final outcomes. However, enabling this requires the community to develop stable and reliable reinforcement learning algorithms that can effectively train LLMs. Developing such algorithms requires tasks that can gauge progress on algorithm design, provide accessible and reproducible evaluations for multi-turn interactions, and cover a range of task properties and challenges in improving reinforcement learning algorithms. Our paper introduces the LMRL-Gym benchmark for evaluating multi-turn RL for LLMs, together with an open-source research framework containing a basic toolkit for getting started on multi-turn RL with offline value-based and policy-based RL methods. Our benchmark consists of 8 different language tasks, which require multiple rounds of language interaction and cover a range of tasks in open-ended dialogue and text games.
Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations
Nov 09, 2023Large language models (LLMs) have emerged as powerful and general solutions to many natural language tasks. However, many of the most important applications of language generation are interactive, where an agent has to talk to a person to reach a desired outcome. For example, a teacher might try to understand their student's current comprehension level to tailor their instruction accordingly, and a travel agent might ask questions of their customer to understand their preferences in order to recommend activities they might enjoy. LLMs trained with supervised fine-tuning or "single-step" RL, as with standard RLHF, might struggle which tasks that require such goal-directed behavior, since they are not trained to optimize for overall conversational outcomes after multiple turns of interaction. In this work, we explore a new method for adapting LLMs with RL for such goal-directed dialogue. Our key insight is that, though LLMs might not effectively solve goal-directed dialogue tasks out of the box, they can provide useful data for solving such tasks by simulating suboptimal but human-like behaviors. Given a textual description of a goal-directed dialogue task, we leverage LLMs to sample diverse synthetic rollouts of hypothetical in-domain human-human interactions. Our algorithm then utilizes this dataset with offline reinforcement learning to train an interactive conversational agent that can optimize goal-directed objectives over multiple turns. In effect, the LLM produces examples of possible interactions, and RL then processes these examples to learn to perform more optimal interactions. Empirically, we show that our proposed approach achieves state-of-the-art performance in various goal-directed dialogue tasks that include teaching and preference elicitation.
Offline RL with Observation Histories: Analyzing and Improving Sample Complexity
Oct 31, 2023Offline reinforcement learning (RL) can in principle synthesize more optimal behavior from a dataset consisting only of suboptimal trials. One way that this can happen is by "stitching" together the best parts of otherwise suboptimal trajectories that overlap on similar states, to create new behaviors where each individual state is in-distribution, but the overall returns are higher. However, in many interesting and complex applications, such as autonomous navigation and dialogue systems, the state is partially observed. Even worse, the state representation is unknown or not easy to define. In such cases, policies and value functions are often conditioned on observation histories instead of states. In these cases, it is not clear if the same kind of "stitching" is feasible at the level of observation histories, since two different trajectories would always have different histories, and thus "similar states" that might lead to effective stitching cannot be leveraged. Theoretically, we show that standard offline RL algorithms conditioned on observation histories suffer from poor sample complexity, in accordance with the above intuition. We then identify sufficient conditions under which offline RL can still be efficient -- intuitively, it needs to learn a compact representation of history comprising only features relevant for action selection. We introduce a bisimulation loss that captures the extent to which this happens, and propose that offline RL can explicitly optimize this loss to aid worst-case sample complexity. Empirically, we show that across a variety of tasks either our proposed loss improves performance, or the value of this loss is already minimized as a consequence of standard offline RL, indicating that it correlates well with good performance.
ExeDec: Execution Decomposition for Compositional Generalization in Neural Program Synthesis
Jul 26, 2023When writing programs, people have the ability to tackle a new complex task by decomposing it into smaller and more familiar subtasks. While it is difficult to measure whether neural program synthesis methods have similar capabilities, we can measure whether they compositionally generalize, that is, whether a model that has been trained on the simpler subtasks is subsequently able to solve more complex tasks. In this paper, we characterize several different forms of compositional generalization that are desirable in program synthesis, forming a meta-benchmark which we use to create generalization tasks for two popular datasets, RobustFill and DeepCoder. We then propose ExeDec, a novel decomposition-based synthesis strategy that predicts execution subgoals to solve problems step-by-step informed by program execution at each step. ExeDec has better synthesis performance and greatly improved compositional generalization ability compared to baselines.
Learning to Influence Human Behavior with Offline Reinforcement Learning
Mar 10, 2023

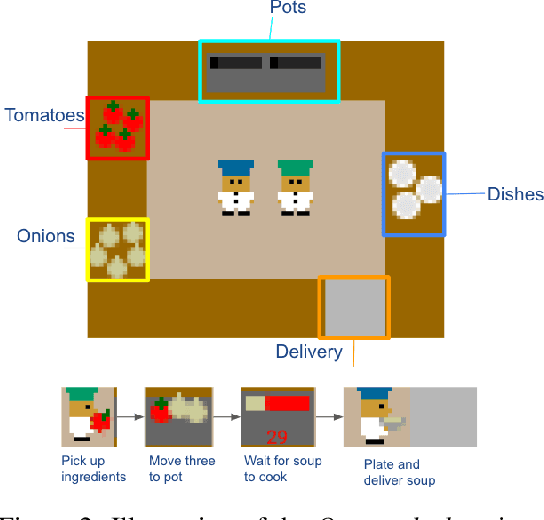

In the real world, some of the most complex settings for learned agents involve interaction with humans, who often exhibit suboptimal, unpredictable behavior due to sophisticated biases. Agents that interact with people in such settings end up influencing the actions that these people take. Our goal in this work is to enable agents to leverage that influence to improve the human's performance in collaborative tasks, as the task unfolds. Unlike prior work, we do not assume online training with people (which tends to be too expensive and unsafe), nor access to a high fidelity simulator of the environment. Our idea is that by taking a variety of previously observed human-human interaction data and labeling it with the task reward, offline reinforcement learning (RL) can learn to combine components of behavior, and uncover actions that lead to more desirable human actions. First, we show that offline RL can learn strategies to influence and improve human behavior, despite those strategies not appearing in the dataset, by utilizing components of diverse, suboptimal interactions. In addition, we demonstrate that offline RL can learn influence that adapts with humans, thus achieving long-term coordination with them even when their behavior changes. We evaluate our proposed method with real people in the Overcooked collaborative benchmark domain, and demonstrate successful improvement in human performance.
On the Sensitivity of Reward Inference to Misspecified Human Models
Dec 09, 2022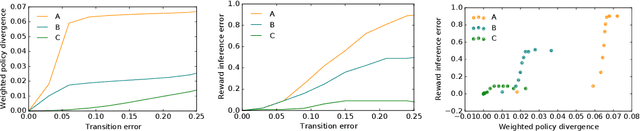
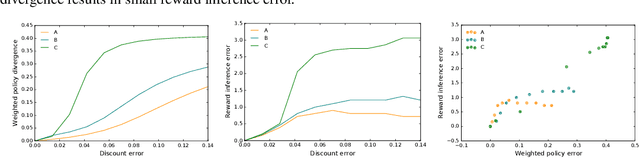
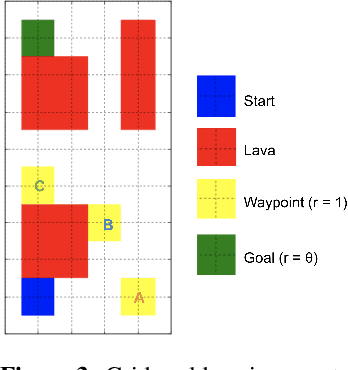
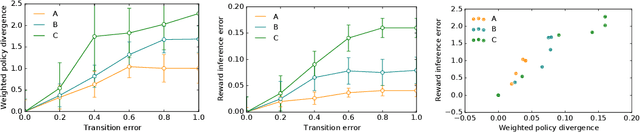
Inferring reward functions from human behavior is at the center of value alignment - aligning AI objectives with what we, humans, actually want. But doing so relies on models of how humans behave given their objectives. After decades of research in cognitive science, neuroscience, and behavioral economics, obtaining accurate human models remains an open research topic. This begs the question: how accurate do these models need to be in order for the reward inference to be accurate? On the one hand, if small errors in the model can lead to catastrophic error in inference, the entire framework of reward learning seems ill-fated, as we will never have perfect models of human behavior. On the other hand, if as our models improve, we can have a guarantee that reward accuracy also improves, this would show the benefit of more work on the modeling side. We study this question both theoretically and empirically. We do show that it is unfortunately possible to construct small adversarial biases in behavior that lead to arbitrarily large errors in the inferred reward. However, and arguably more importantly, we are also able to identify reasonable assumptions under which the reward inference error can be bounded linearly in the error in the human model. Finally, we verify our theoretical insights in discrete and continuous control tasks with simulated and human data.