 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating & Reducing Deceptive Dialogue From Language Models with Multi-turn RL
Oct 16, 2025Large Language Models (LLMs) interact with millions of people worldwide in applications such as customer support, education and healthcare. However, their ability to produce deceptive outputs, whether intentionally or inadvertently, poses significant safety concerns. The unpredictable nature of LLM behavior, combined with insufficient safeguards against hallucination, misinformation, and user manipulation, makes their misuse a serious, real-world risk. In this paper, we investigate the extent to which LLMs engage in deception within dialogue, and propose the belief misalignment metric to quantify deception. We evaluate deception across four distinct dialogue scenarios, using five established deception detection metrics and our proposed metric. Our findings reveal this novel deception measure correlates more closely with human judgments than any existing metrics we test. Additionally, our benchmarking of eight state-of-the-art models indicates that LLMs naturally exhibit deceptive behavior in approximately 26% of dialogue turns, even when prompted with seemingly benign objectives. When prompted to deceive, LLMs are capable of increasing deceptiveness by as much as 31% relative to baselines. Unexpectedly, models trained with RLHF, the predominant approach for ensuring the safety of widely-deployed LLMs, still exhibit deception at a rate of 43% on average. Given that deception in dialogue is a behavior that develops over an interaction history, its effective evaluation and mitigation necessitates moving beyond single-utterance analyses. We introduce a multi-turn reinforcement learning methodology to fine-tune LLMs to reduce deceptive behaviors, leading to a 77.6% reduction compared to other instruction-tuned models.
Enhancing Personalized Multi-Turn Dialogue with Curiosity Reward
Apr 04, 2025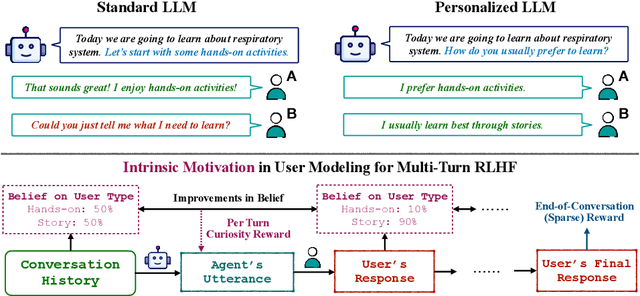
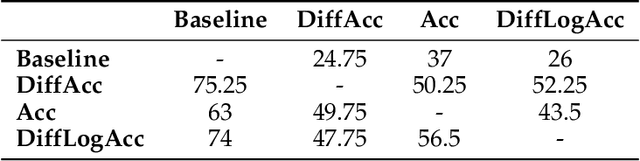
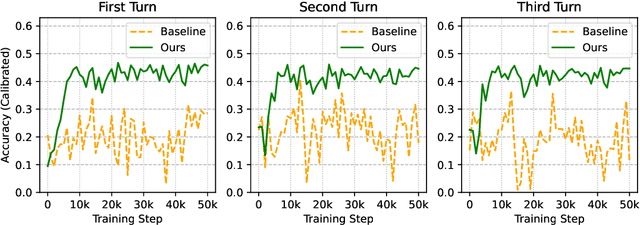
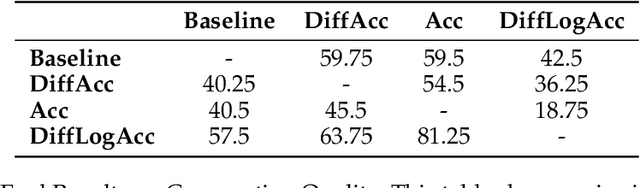
Effective conversational agents must be able to personalize their behavior to suit a user's preferences, personality, and attributes, whether they are assisting with writing tasks or operating in domains like education or healthcare. Current training methods like Reinforcement Learning from Human Feedback (RLHF) prioritize helpfulness and safety but fall short in fostering truly empathetic, adaptive, and personalized interactions. Traditional approaches to personalization often rely on extensive user history, limiting their effectiveness for new or context-limited users. To overcome these limitations, we propose to incorporate an intrinsic motivation to improve the conversational agents's model of the user as an additional reward alongside multi-turn RLHF. This reward mechanism encourages the agent to actively elicit user traits by optimizing conversations to increase the accuracy of its user model. Consequently, the policy agent can deliver more personalized interactions through obtaining more information about the user. We applied our method both education and fitness settings, where LLMs teach concepts or recommend personalized strategies based on users' hidden learning style or lifestyle attributes. Using LLM-simulated users, our approach outperformed a multi-turn RLHF baseline in revealing information about the users' preferences, and adapting to them.
Virtual Personas for Language Models via an Anthology of Backstories
Jul 09, 2024
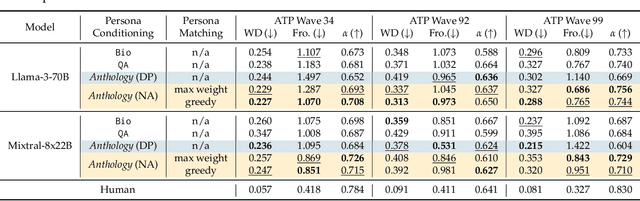
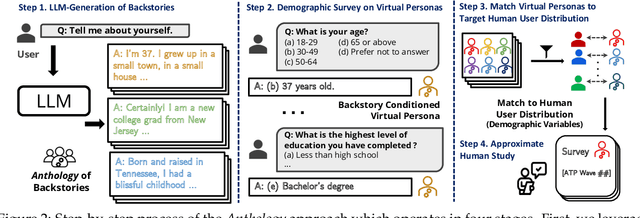

Large language models (LLMs) are trained from vast repositories of text authored by millions of distinct authors, reflecting an enormous diversity of human traits. While these models bear the potential to be used as approximations of human subjects in behavioral studies, prior efforts have been limited in steering model responses to match individual human users. In this work, we introduce "Anthology", a method for conditioning LLMs to particular virtual personas by harnessing open-ended life narratives, which we refer to as "backstories." We show that our methodology enhances the consistency and reliability of experimental outcomes while ensuring better representation of diverse sub-populations. Across three nationally representative human surveys conducted as part of Pew Research Center's American Trends Panel (ATP), we demonstrate that Anthology achieves up to 18% improvement in matching the response distributions of human respondents and 27% improvement in consistency metrics. Our code and generated backstories are available at https://github.com/CannyLab/anthology.
LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models
Nov 30, 2023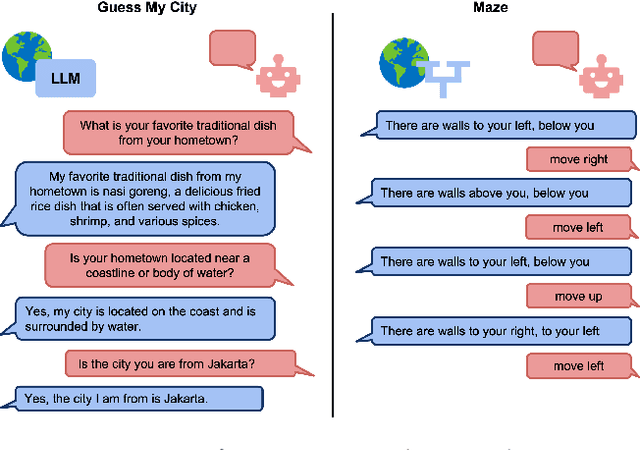
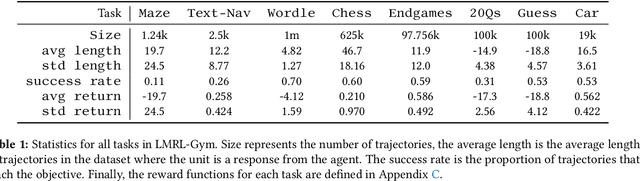
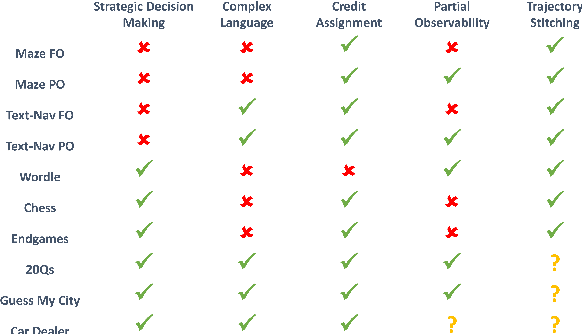
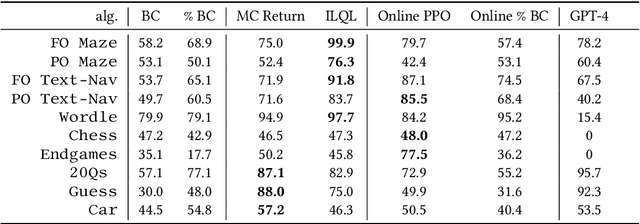
Large language models (LLMs) provide excellent text-generation capabilities, but standard prompting and generation methods generally do not lead to intentional or goal-directed agents and might necessitate considerable prompt tuning. This becomes particularly apparent in multi-turn conversations: even the best current LLMs rarely ask clarifying questions, engage in explicit information gathering, or take actions now that lead to better decisions after multiple turns. Reinforcement learning has the potential to leverage the powerful modeling capabilities of LLMs, as well as their internal representation of textual interactions, to create capable goal-directed language agents. This can enable intentional and temporally extended interactions, such as with humans, through coordinated persuasion and carefully crafted questions, or in goal-directed play through text games to bring about desired final outcomes. However, enabling this requires the community to develop stable and reliable reinforcement learning algorithms that can effectively train LLMs. Developing such algorithms requires tasks that can gauge progress on algorithm design, provide accessible and reproducible evaluations for multi-turn interactions, and cover a range of task properties and challenges in improving reinforcement learning algorithms. Our paper introduces the LMRL-Gym benchmark for evaluating multi-turn RL for LLMs, together with an open-source research framework containing a basic toolkit for getting started on multi-turn RL with offline value-based and policy-based RL methods. Our benchmark consists of 8 different language tasks, which require multiple rounds of language interaction and cover a range of tasks in open-ended dialogue and text games.
Moral Foundations of Large Language Models
Oct 23, 2023



Moral foundations theory (MFT) is a psychological assessment tool that decomposes human moral reasoning into five factors, including care/harm, liberty/oppression, and sanctity/degradation (Graham et al., 2009). People vary in the weight they place on these dimensions when making moral decisions, in part due to their cultural upbringing and political ideology. As large language models (LLMs) are trained on datasets collected from the internet, they may reflect the biases that are present in such corpora. This paper uses MFT as a lens to analyze whether popular LLMs have acquired a bias towards a particular set of moral values. We analyze known LLMs and find they exhibit particular moral foundations, and show how these relate to human moral foundations and political affiliations. We also measure the consistency of these biases, or whether they vary strongly depending on the context of how the model is prompted. Finally, we show that we can adversarially select prompts that encourage the moral to exhibit a particular set of moral foundations, and that this can affect the model's behavior on downstream tasks. These findings help illustrate the potential risks and unintended consequences of LLMs assuming a particular moral stance.
Personality Traits in Large Language Models
Jul 01, 2023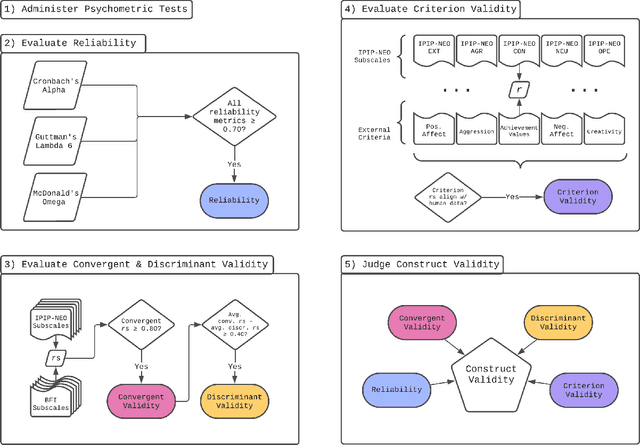

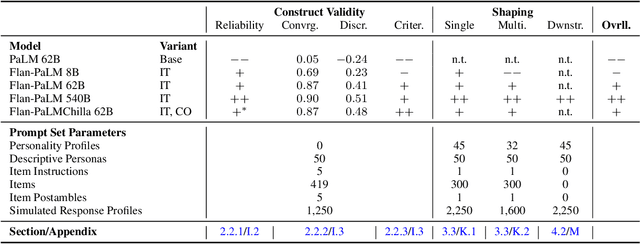
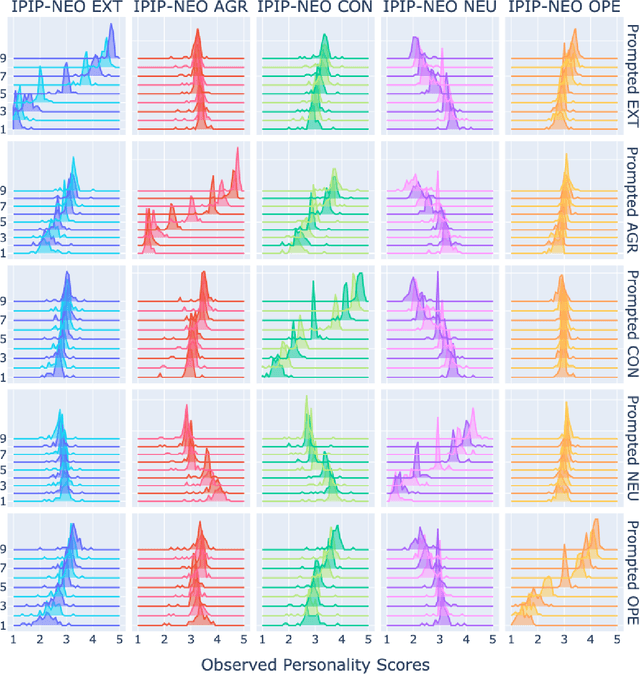
The advent of large language models (LLMs) has revolutionized natural language processing, enabling the generation of coherent and contextually relevant text. As LLMs increasingly power conversational agents, the synthesized personality embedded in these models by virtue of their training on large amounts of human-generated data draws attention. Since personality is an important factor determining the effectiveness of communication, we present a comprehensive method for administering validated psychometric tests and quantifying, analyzing, and shaping personality traits exhibited in text generated from widely-used LLMs. We find that: 1) personality simulated in the outputs of some LLMs (under specific prompting configurations) is reliable and valid; 2) evidence of reliability and validity of LLM-simulated personality is stronger for larger and instruction fine-tuned models; and 3) personality in LLM outputs can be shaped along desired dimensions to mimic specific personality profiles. We also discuss potential applications and ethical implications of our measurement and shaping framework, especially regarding responsible use of LLMs.
Basis for Intentions: Efficient Inverse Reinforcement Learning using Past Experience
Aug 09, 2022
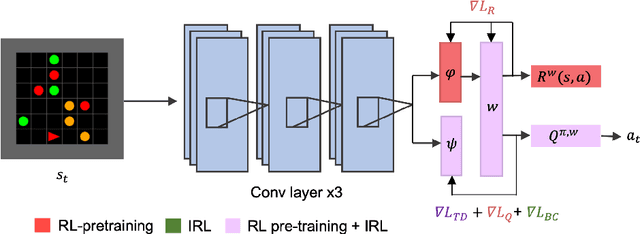

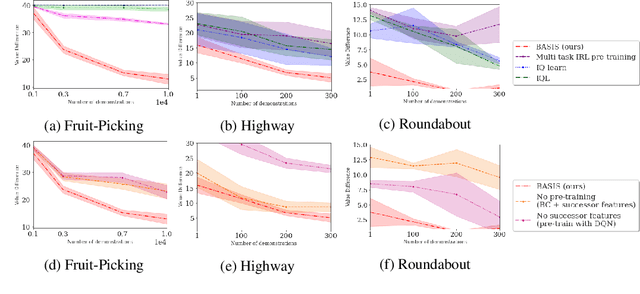
This paper addresses the problem of inverse reinforcement learning (IRL) -- inferring the reward function of an agent from observing its behavior. IRL can provide a generalizable and compact representation for apprenticeship learning, and enable accurately inferring the preferences of a human in order to assist them. %and provide for more accurate prediction. However, effective IRL is challenging, because many reward functions can be compatible with an observed behavior. We focus on how prior reinforcement learning (RL) experience can be leveraged to make learning these preferences faster and more efficient. We propose the IRL algorithm BASIS (Behavior Acquisition through Successor-feature Intention inference from Samples), which leverages multi-task RL pre-training and successor features to allow an agent to build a strong basis for intentions that spans the space of possible goals in a given domain. When exposed to just a few expert demonstrations optimizing a novel goal, the agent uses its basis to quickly and effectively infer the reward function. Our experiments reveal that our method is highly effective at inferring and optimizing demonstrated reward functions, accurately inferring reward functions from less than 100 trajectories.
Context-Specific Representation Abstraction for Deep Option Learning
Sep 20, 2021
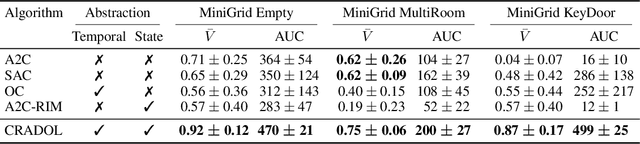
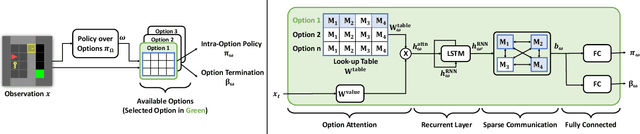
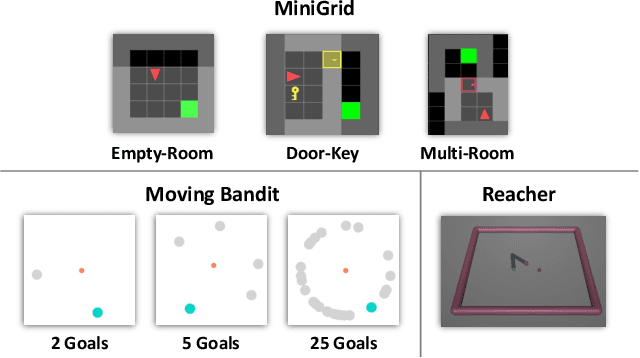
Hierarchical reinforcement learning has focused on discovering temporally extended actions, such as options, that can provide benefits in problems requiring extensive exploration. One promising approach that learns these options end-to-end is the option-critic (OC) framework. We examine and show in this paper that OC does not decompose a problem into simpler sub-problems, but instead increases the size of the search over policy space with each option considering the entire state space during learning. This issue can result in practical limitations of this method, including sample inefficient learning. To address this problem, we introduce Context-Specific Representation Abstraction for Deep Option Learning (CRADOL), a new framework that considers both temporal abstraction and context-specific representation abstraction to effectively reduce the size of the search over policy space. Specifically, our method learns a factored belief state representation that enables each option to learn a policy over only a subsection of the state space. We test our method against hierarchical, non-hierarchical, and modular recurrent neural network baselines, demonstrating significant sample efficiency improvements in challenging partially observable environments.
A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning
Oct 31, 2020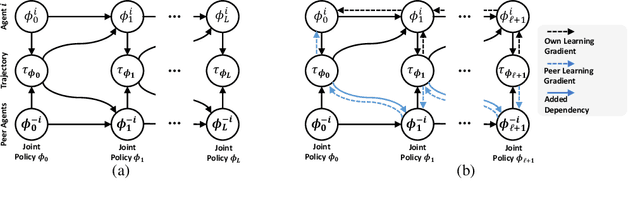
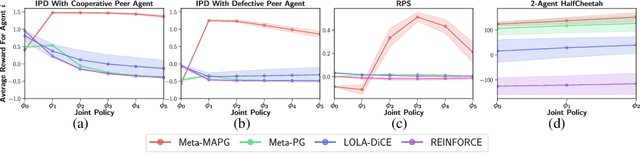

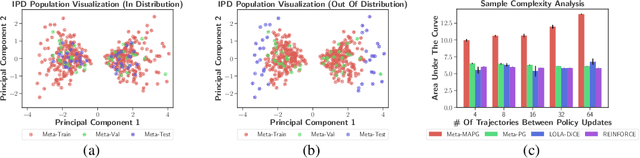
A fundamental challenge in multiagent reinforcement learning is to learn beneficial behaviors in a shared environment with other agents that are also simultaneously learning. In particular, each agent perceives the environment as effectively non-stationary due to the changing policies of other agents. Moreover, each agent is itself constantly learning, leading to natural nonstationarity in the distribution of experiences encountered. In this paper, we propose a novel meta-multiagent policy gradient theorem that directly accommodates for the non-stationary policy dynamics inherent to these multiagent settings. This is achieved by modeling our gradient updates to directly consider both an agent's own non-stationary policy dynamics and the non-stationary policy dynamics of other agents interacting with it in the environment. We find that our theoretically grounded approach provides a general solution to the multiagent learning problem, which inherently combines key aspects of previous state of the art approaches on this topic. We test our method on several multiagent benchmarks and demonstrate a more efficient ability to adapt to new agents as they learn than previous related approaches across the spectrum of mixed incentive, competitive, and cooperative environments.