 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Interaction Agents: Building Real-Time Agents with Asynchronous I/O and Speculative Tool Calling
May 14, 2026There is a growing demand for agentic AI technologies for a range of downstream applications like customer service and personal assistants. For applications where the agent needs to interact with a person, real-time low-latency responsiveness is required; for example, with voice-controlled applications, under 1 second of latency is typically required for the interaction to feel seamless. However, if we want the LLM to reason and execute an agentic workflow with tool calling, this can add several seconds or more of latency, which is prohibitive for real-time latency-sensitive applications. In our work, we propose Speculative Interaction Agents to enable real-time interaction even for agents with complex multi-turn tool calling. We propose Asynchronous I/O, which decouples the core agent reason-and-act thread from waiting for additional information from either the user or environment, thereby allowing for overlapping agentic processing while waiting on external delays. We also propose Speculative Tool Calling as a method to manage task execution when the agent is still unsure if it has received the full information or if additional user information may later be provided. For strong cloud models, our method can be applied out-of-the-box to existing real-time cloud APIs, providing 1.3-1.7$\times$ speedups with minor accuracy loss. To enable real-time interaction with small edge-scale models, we also present a clock-based training methodology that adapts the model to handle streaming inputs and asynchronous responses, and demonstrate a synthetic data generation strategy for SFT. Altogether, this approach provides 1.6-2.2$\times$ speedups with the Qwen2.5-3B-Instruct and Llama-3.2-3B-Instruct models across multiple tool calling benchmarks.
Identity, Cooperation and Framing Effects within Groups of Real and Simulated Humans
Jan 22, 2026Humans act via a nuanced process that depends both on rational deliberation and also on identity and contextual factors. In this work, we study how large language models (LLMs) can simulate human action in the context of social dilemma games. While prior work has focused on "steering" (weak binding) of chat models to simulate personas, we analyze here how deep binding of base models with extended backstories leads to more faithful replication of identity-based behaviors. Our study has these findings: simulation fidelity vs human studies is improved by conditioning base LMs with rich context of narrative identities and checking consistency using instruction-tuned models. We show that LLMs can also model contextual factors such as time (year that a study was performed), question framing, and participant pool effects. LLMs, therefore, allow us to explore the details that affect human studies but which are often omitted from experiment descriptions, and which hamper accurate replication.
Higher-Order Binding of Language Model Virtual Personas: a Study on Approximating Political Partisan Misperceptions
Apr 16, 2025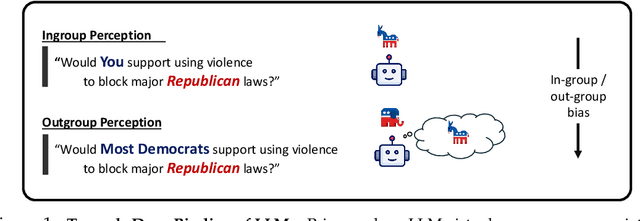
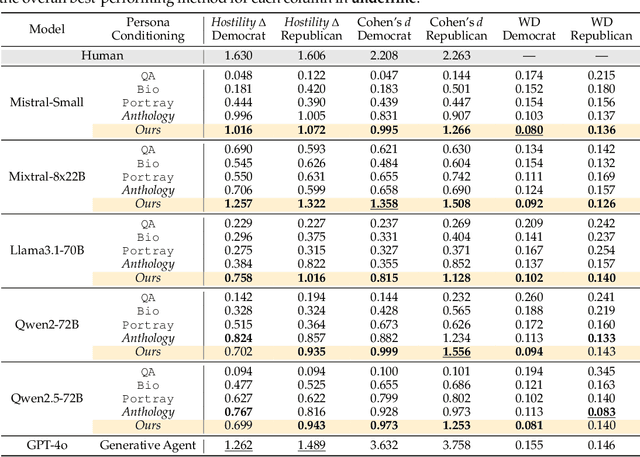

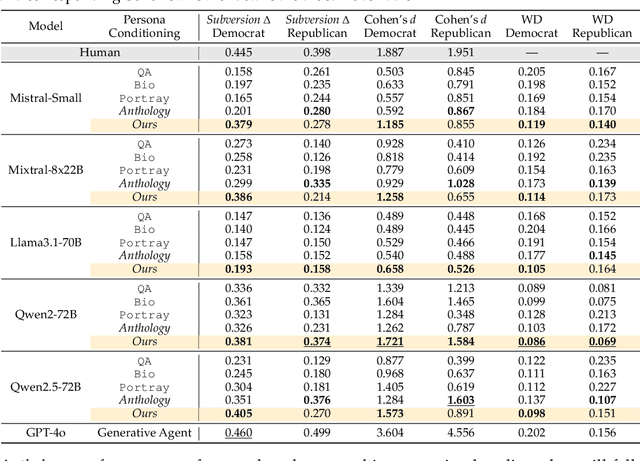
Large language models (LLMs) are increasingly capable of simulating human behavior, offering cost-effective ways to estimate user responses during the early phases of survey design. While previous studies have examined whether models can reflect individual opinions or attitudes, we argue that a \emph{higher-order} binding of virtual personas requires successfully approximating not only the opinions of a user as an identified member of a group, but also the nuanced ways in which that user perceives and evaluates those outside the group. In particular, faithfully simulating how humans perceive different social groups is critical for applying LLMs to various political science studies, including timely topics on polarization dynamics, inter-group conflict, and democratic backsliding. To this end, we propose a novel methodology for constructing virtual personas with synthetic user ``backstories" generated as extended, multi-turn interview transcripts. Our generated backstories are longer, rich in detail, and consistent in authentically describing a singular individual, compared to previous methods. We show that virtual personas conditioned on our backstories closely replicate human response distributions (up to an 87\% improvement as measured by Wasserstein Distance) and produce effect sizes that closely match those observed in the original studies. Altogether, our work extends the applicability of LLMs beyond estimating individual self-opinions, enabling their use in a broader range of human studies.
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
Mar 12, 2025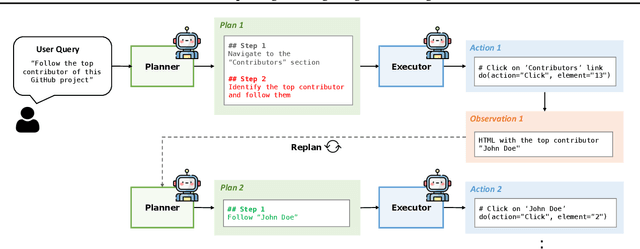
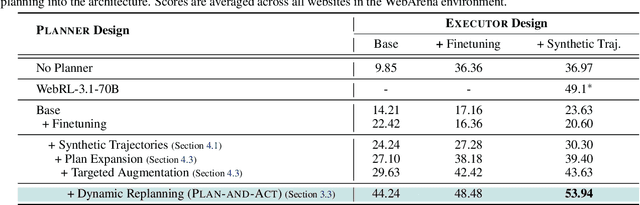
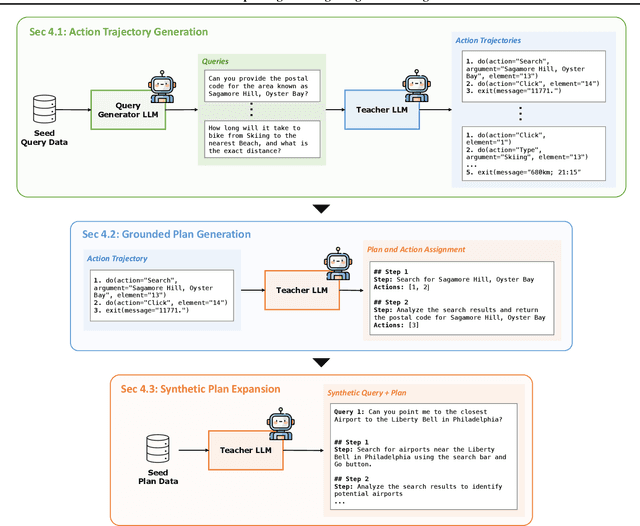
Large language models (LLMs) have shown remarkable advancements in enabling language agents to tackle simple tasks. However, applying them for complex, multi-step, long-horizon tasks remains a challenge. Recent work have found success by separating high-level planning from low-level execution, which enables the model to effectively balance high-level planning objectives and low-level execution details. However, generating accurate plans remains difficult since LLMs are not inherently trained for this task. To address this, we propose Plan-and-Act, a novel framework that incorporates explicit planning into LLM-based agents and introduces a scalable method to enhance plan generation through a novel synthetic data generation method. Plan-and-Act consists of a Planner model which generates structured, high-level plans to achieve user goals, and an Executor model that translates these plans into environment-specific actions. To train the Planner effectively, we introduce a synthetic data generation method that annotates ground-truth trajectories with feasible plans, augmented with diverse and extensive examples to enhance generalization. We evaluate Plan-and-Act using web navigation as a representative long-horizon planning environment, demonstrating a state-of the-art 54% success rate on the WebArena-Lite benchmark.
Language Model Fine-Tuning on Scaled Survey Data for Predicting Distributions of Public Opinions
Feb 24, 2025Large language models (LLMs) present novel opportunities in public opinion research by predicting survey responses in advance during the early stages of survey design. Prior methods steer LLMs via descriptions of subpopulations as LLMs' input prompt, yet such prompt engineering approaches have struggled to faithfully predict the distribution of survey responses from human subjects. In this work, we propose directly fine-tuning LLMs to predict response distributions by leveraging unique structural characteristics of survey data. To enable fine-tuning, we curate SubPOP, a significantly scaled dataset of 3,362 questions and 70K subpopulation-response pairs from well-established public opinion surveys. We show that fine-tuning on SubPOP greatly improves the match between LLM predictions and human responses across various subpopulations, reducing the LLM-human gap by up to 46% compared to baselines, and achieves strong generalization to unseen surveys and subpopulations. Our findings highlight the potential of survey-based fine-tuning to improve opinion prediction for diverse, real-world subpopulations and therefore enable more efficient survey designs. Our code is available at https://github.com/JosephJeesungSuh/subpop.
ETS: Efficient Tree Search for Inference-Time Scaling
Feb 19, 2025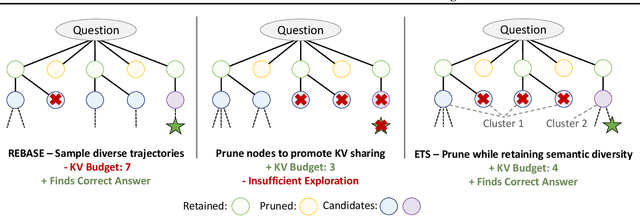
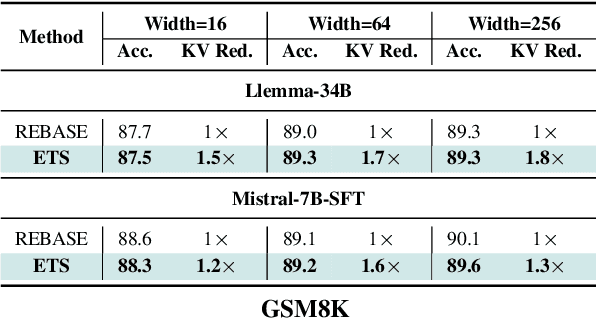
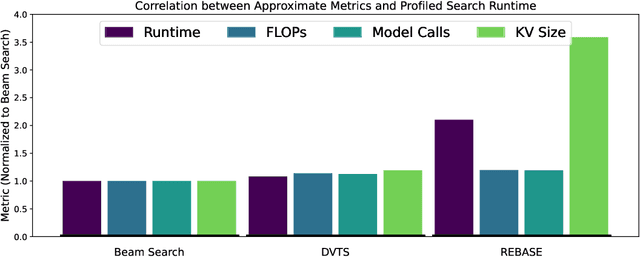
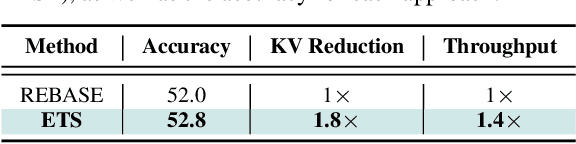
Test-time compute scaling has emerged as a new axis along which to improve model accuracy, where additional computation is used at inference time to allow the model to think longer for more challenging problems. One promising approach for test-time compute scaling is search against a process reward model, where a model generates multiple potential candidates at each step of the search, and these partial trajectories are then scored by a separate reward model in order to guide the search process. The diversity of trajectories in the tree search process affects the accuracy of the search, since increasing diversity promotes more exploration. However, this diversity comes at a cost, as divergent trajectories have less KV sharing, which means they consume more memory and slow down the search process. Previous search methods either do not perform sufficient exploration, or else explore diverse trajectories but have high latency. We address this challenge by proposing Efficient Tree Search (ETS), which promotes KV sharing by pruning redundant trajectories while maintaining necessary diverse trajectories. ETS incorporates a linear programming cost model to promote KV cache sharing by penalizing the number of nodes retained, while incorporating a semantic coverage term into the cost model to ensure that we retain trajectories which are semantically different. We demonstrate how ETS can achieve 1.8$\times$ reduction in average KV cache size during the search process, leading to 1.4$\times$ increased throughput relative to prior state-of-the-art methods, with minimal accuracy degradation and without requiring any custom kernel implementation. Code is available at: https://github.com/SqueezeAILab/ETS.
Rediscovering the Latent Dimensions of Personality with Large Language Models as Trait Descriptors
Sep 16, 2024



Assessing personality traits using large language models (LLMs) has emerged as an interesting and challenging area of research. While previous methods employ explicit questionnaires, often derived from the Big Five model of personality, we hypothesize that LLMs implicitly encode notions of personality when modeling next-token responses. To demonstrate this, we introduce a novel approach that uncovers latent personality dimensions in LLMs by applying singular value de-composition (SVD) to the log-probabilities of trait-descriptive adjectives. Our experiments show that LLMs "rediscover" core personality traits such as extraversion, agreeableness, conscientiousness, neuroticism, and openness without relying on direct questionnaire inputs, with the top-5 factors corresponding to Big Five traits explaining 74.3% of the variance in the latent space. Moreover, we can use the derived principal components to assess personality along the Big Five dimensions, and achieve improvements in average personality prediction accuracy of up to 5% over fine-tuned models, and up to 21% over direct LLM-based scoring techniques.
Efficient and Scalable Estimation of Tool Representations in Vector Space
Sep 02, 2024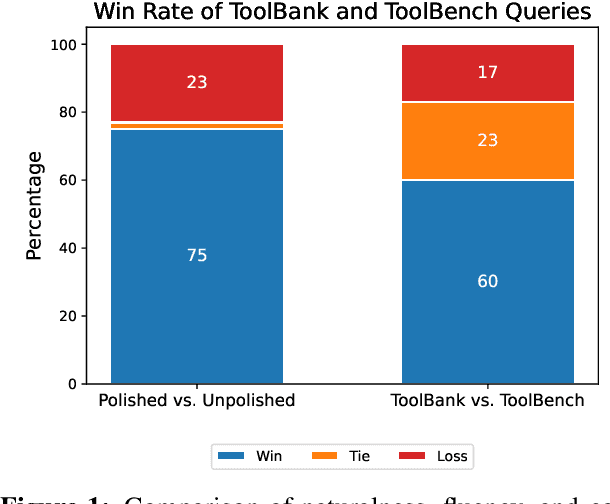
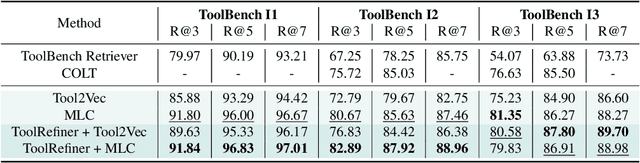
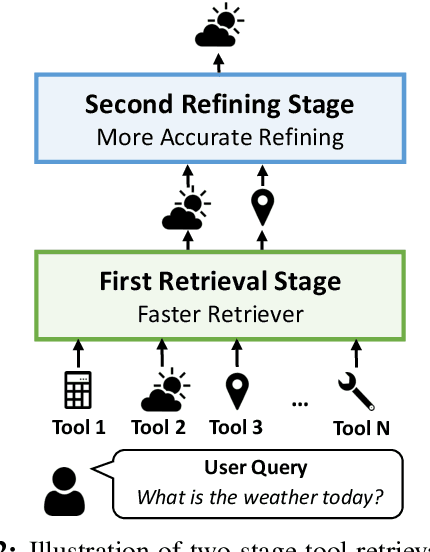
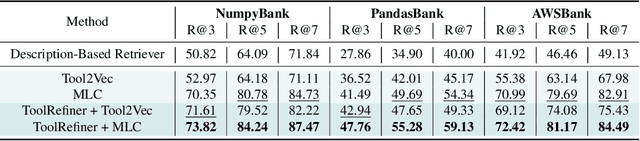
Recent advancements in function calling and tool use have significantly enhanced the capabilities of large language models (LLMs) by enabling them to interact with external information sources and execute complex tasks. However, the limited context window of LLMs presents challenges when a large number of tools are available, necessitating efficient methods to manage prompt length and maintain accuracy. Existing approaches, such as fine-tuning LLMs or leveraging their reasoning capabilities, either require frequent retraining or incur significant latency overhead. A more efficient solution involves training smaller models to retrieve the most relevant tools for a given query, although this requires high quality, domain-specific data. To address those challenges, we present a novel framework for generating synthetic data for tool retrieval applications and an efficient data-driven tool retrieval strategy using small encoder models. Empowered by LLMs, we create ToolBank, a new tool retrieval dataset that reflects real human user usages. For tool retrieval methodologies, we propose novel approaches: (1) Tool2Vec: usage-driven tool embedding generation for tool retrieval, (2) ToolRefiner: a staged retrieval method that iteratively improves the quality of retrieved tools, and (3) MLC: framing tool retrieval as a multi-label classification problem. With these new methods, we achieve improvements of up to 27.28 in Recall@K on the ToolBench dataset and 30.5 in Recall@K on ToolBank. Additionally, we present further experimental results to rigorously validate our methods. Our code is available at \url{https://github.com/SqueezeAILab/Tool2Vec}
TinyAgent: Function Calling at the Edge
Sep 01, 2024



Recent large language models (LLMs) have enabled the development of advanced agentic systems that can integrate various tools and APIs to fulfill user queries through function calling. However, the deployment of these LLMs on the edge has not been explored since they typically require cloud-based infrastructure due to their substantial model size and computational demands. To this end, we present TinyAgent, an end-to-end framework for training and deploying task-specific small language model agents capable of function calling for driving agentic systems at the edge. We first show how to enable accurate function calling for open-source models via the LLMCompiler framework. We then systematically curate a high-quality dataset for function calling, which we use to fine-tune two small language models, TinyAgent-1.1B and 7B. For efficient inference, we introduce a novel tool retrieval method to reduce the input prompt length and utilize quantization to further accelerate the inference speed. As a driving application, we demonstrate a local Siri-like system for Apple's MacBook that can execute user commands through text or voice input. Our results show that our models can achieve, and even surpass, the function-calling capabilities of larger models like GPT-4-Turbo, while being fully deployed at the edge. We open-source our dataset, models, and installable package and provide a demo video for our MacBook assistant agent.
Virtual Personas for Language Models via an Anthology of Backstories
Jul 09, 2024
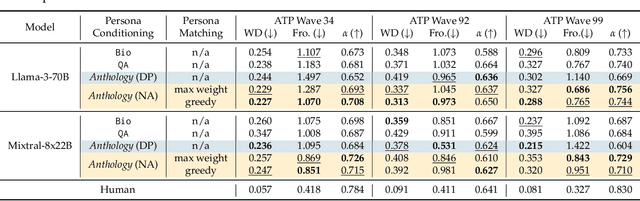
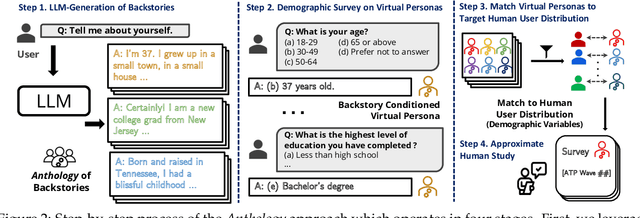

Large language models (LLMs) are trained from vast repositories of text authored by millions of distinct authors, reflecting an enormous diversity of human traits. While these models bear the potential to be used as approximations of human subjects in behavioral studies, prior efforts have been limited in steering model responses to match individual human users. In this work, we introduce "Anthology", a method for conditioning LLMs to particular virtual personas by harnessing open-ended life narratives, which we refer to as "backstories." We show that our methodology enhances the consistency and reliability of experimental outcomes while ensuring better representation of diverse sub-populations. Across three nationally representative human surveys conducted as part of Pew Research Center's American Trends Panel (ATP), we demonstrate that Anthology achieves up to 18% improvement in matching the response distributions of human respondents and 27% improvement in consistency metrics. Our code and generated backstories are available at https://github.com/CannyLab/anthology.