 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-Order Binding of Language Model Virtual Personas: a Study on Approximating Political Partisan Misperceptions
Apr 16, 2025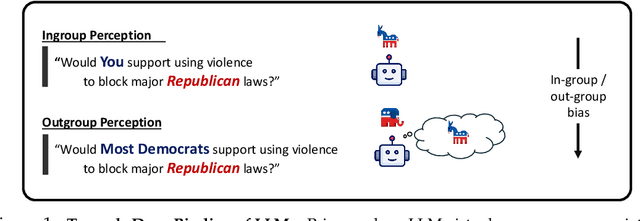
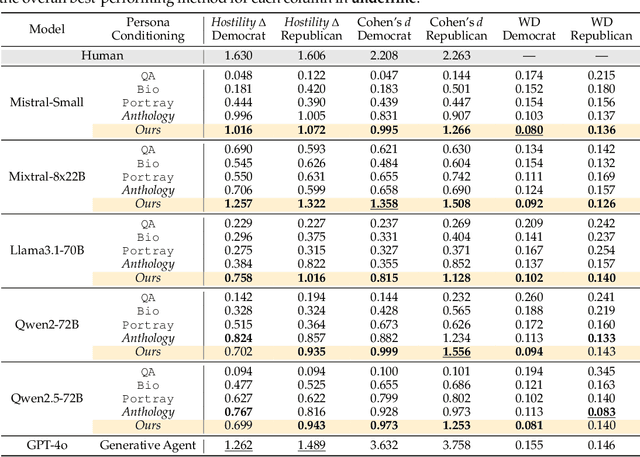

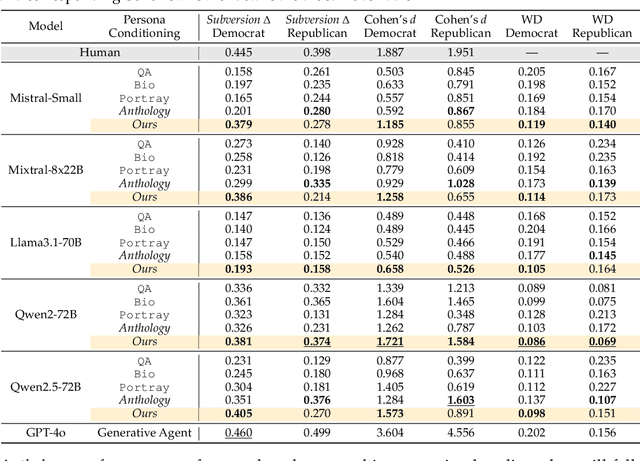
Large language models (LLMs) are increasingly capable of simulating human behavior, offering cost-effective ways to estimate user responses during the early phases of survey design. While previous studies have examined whether models can reflect individual opinions or attitudes, we argue that a \emph{higher-order} binding of virtual personas requires successfully approximating not only the opinions of a user as an identified member of a group, but also the nuanced ways in which that user perceives and evaluates those outside the group. In particular, faithfully simulating how humans perceive different social groups is critical for applying LLMs to various political science studies, including timely topics on polarization dynamics, inter-group conflict, and democratic backsliding. To this end, we propose a novel methodology for constructing virtual personas with synthetic user ``backstories" generated as extended, multi-turn interview transcripts. Our generated backstories are longer, rich in detail, and consistent in authentically describing a singular individual, compared to previous methods. We show that virtual personas conditioned on our backstories closely replicate human response distributions (up to an 87\% improvement as measured by Wasserstein Distance) and produce effect sizes that closely match those observed in the original studies. Altogether, our work extends the applicability of LLMs beyond estimating individual self-opinions, enabling their use in a broader range of human studies.
Autoregressive Adaptive Hypergraph Transformer for Skeleton-based Activity Recognition
Nov 08, 2024
Extracting multiscale contextual information and higher-order correlations among skeleton sequences using Graph Convolutional Networks (GCNs) alone is inadequate for effective action classification. Hypergraph convolution addresses the above issues but cannot harness the long-range dependencies. Transformer proves to be effective in capturing these dependencies and making complex contextual features accessible. We propose an Autoregressive Adaptive HyperGraph Transformer (AutoregAd-HGformer) model for in-phase (autoregressive and discrete) and out-phase (adaptive) hypergraph generation. The vector quantized in-phase hypergraph equipped with powerful autoregressive learned priors produces a more robust and informative representation suitable for hyperedge formation. The out-phase hypergraph generator provides a model-agnostic hyperedge learning technique to align the attributes with input skeleton embedding. The hybrid (supervised and unsupervised) learning in AutoregAd-HGformer explores the action-dependent feature along spatial, temporal, and channel dimensions. The extensive experimental results and ablation study indicate the superiority of our model over state-of-the-art hypergraph architectures on NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.
HWRCNet: Handwritten Word Recognition in JPEG Compressed Domain using CNN-BiLSTM Network
Jan 08, 2022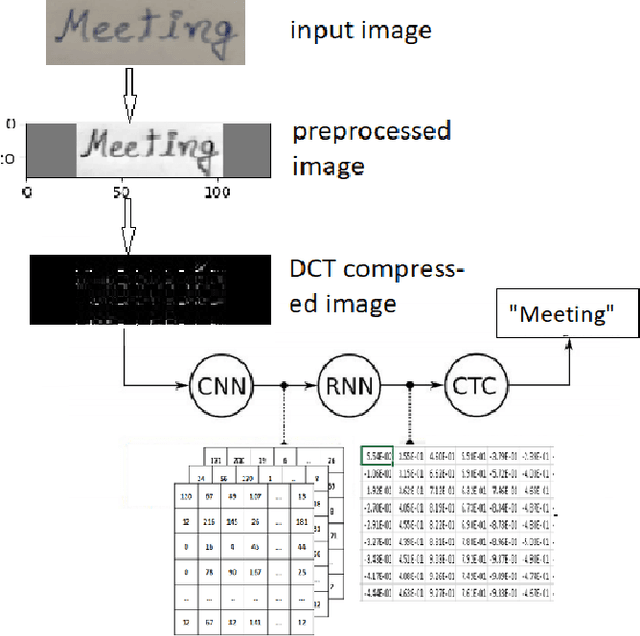
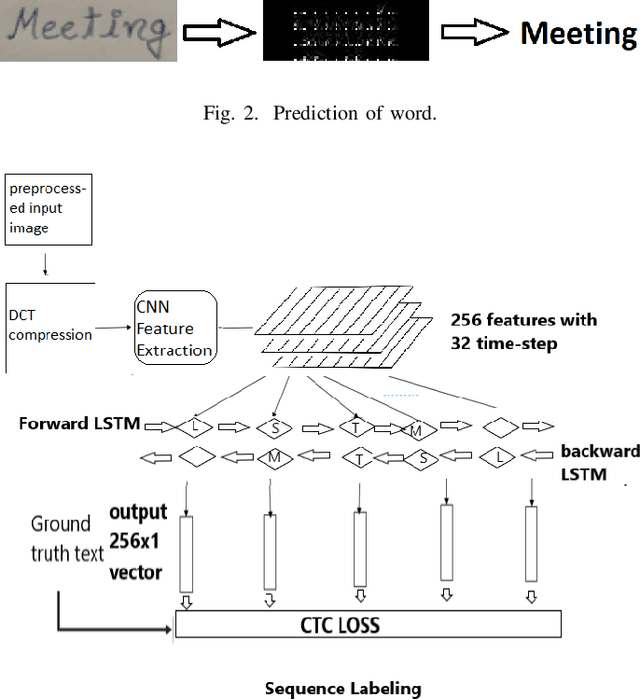
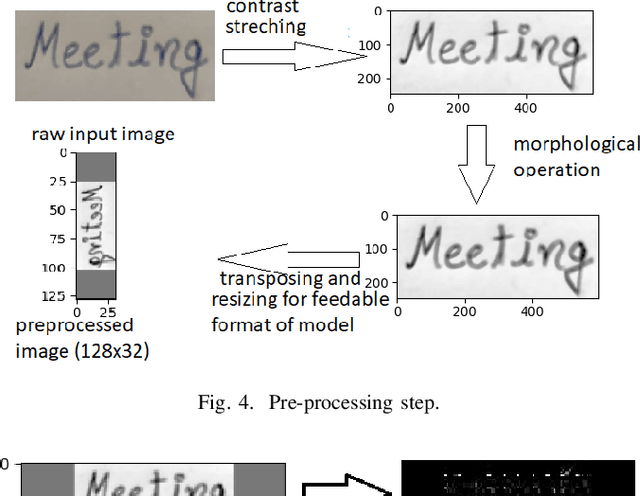
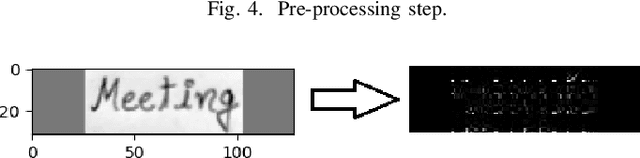
The handwritten word recognition from images using deep learning is an active research area with promising performance. It practical scenario, it might be required to process the handwritten images in the compressed domain due to due to security reasons. However, the utilization of deep learning is still very limited for the processing of compressed images. Motivated by the need of processing document images in the compressed domain using recent developments in deep learning, we propose a HWRCNet model for handwritten word recognition in JPEG compressed domain. The proposed model combines the Convolutional Neural Network (CNN) and Bi-Directional Long Short Term Memory (BiLSTM) based Recurrent Neural Network (RNN). Basically, we train the model using compressed domain images and observe a very appealing performance with 89.05% word recognition accuracy and 13.37% character error rate.