 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Interaction Agents: Building Real-Time Agents with Asynchronous I/O and Speculative Tool Calling
May 14, 2026There is a growing demand for agentic AI technologies for a range of downstream applications like customer service and personal assistants. For applications where the agent needs to interact with a person, real-time low-latency responsiveness is required; for example, with voice-controlled applications, under 1 second of latency is typically required for the interaction to feel seamless. However, if we want the LLM to reason and execute an agentic workflow with tool calling, this can add several seconds or more of latency, which is prohibitive for real-time latency-sensitive applications. In our work, we propose Speculative Interaction Agents to enable real-time interaction even for agents with complex multi-turn tool calling. We propose Asynchronous I/O, which decouples the core agent reason-and-act thread from waiting for additional information from either the user or environment, thereby allowing for overlapping agentic processing while waiting on external delays. We also propose Speculative Tool Calling as a method to manage task execution when the agent is still unsure if it has received the full information or if additional user information may later be provided. For strong cloud models, our method can be applied out-of-the-box to existing real-time cloud APIs, providing 1.3-1.7$\times$ speedups with minor accuracy loss. To enable real-time interaction with small edge-scale models, we also present a clock-based training methodology that adapts the model to handle streaming inputs and asynchronous responses, and demonstrate a synthetic data generation strategy for SFT. Altogether, this approach provides 1.6-2.2$\times$ speedups with the Qwen2.5-3B-Instruct and Llama-3.2-3B-Instruct models across multiple tool calling benchmarks.
Quantifying the Utility of User Simulators for Building Collaborative LLM Assistants
May 10, 2026User simulators are increasingly leveraged to build interactive AI assistants, yet how to measure the quality of these simulators remains an open question. In this work, we show how simulator quality can be quantified in terms of its downstream utility: how an LLM assistant trained with this user simulator performs in the wild when interacting with real humans. In a controlled experiment where only the user simulator varies, we train LLM assistants via reinforcement learning against a spectrum of simulators, from an LLM prompted to role-play a user to one fine-tuned on human utterances from WildChat. As evaluation, we measure pairwise win rates in a user study with 283 participants and on WildBench, a benchmark derived from real human--AI conversations. Training against the role-playing LLM yields an assistant statistically indistinguishable from the initial assistant in our user study (51% win rate), whereas training against the fine-tuned simulator yields significant gains (58% over the initial and 57% over the one trained against role-playing). Closer inspection reveals three further patterns: methods for making role-playing LLMs more realistic (e.g., persona conditioning) improve trained assistants but do not close the gap to the fine-tuned simulator; scaling the simulator's model size benefits the fine-tuned simulator but yields no gain for role-playing ones; and assistants trained against role-playing simulators fail to generalize when paired with other simulators at test time, while the one trained against fine-tuned simulator does. Together, these results argue for grounding user simulators in real human behavior and measuring their quality by their downstream effect on real users.
Identity, Cooperation and Framing Effects within Groups of Real and Simulated Humans
Jan 22, 2026Humans act via a nuanced process that depends both on rational deliberation and also on identity and contextual factors. In this work, we study how large language models (LLMs) can simulate human action in the context of social dilemma games. While prior work has focused on "steering" (weak binding) of chat models to simulate personas, we analyze here how deep binding of base models with extended backstories leads to more faithful replication of identity-based behaviors. Our study has these findings: simulation fidelity vs human studies is improved by conditioning base LMs with rich context of narrative identities and checking consistency using instruction-tuned models. We show that LLMs can also model contextual factors such as time (year that a study was performed), question framing, and participant pool effects. LLMs, therefore, allow us to explore the details that affect human studies but which are often omitted from experiment descriptions, and which hamper accurate replication.
Puzzled by Puzzles: When Vision-Language Models Can't Take a Hint
May 29, 2025Rebus puzzles, visual riddles that encode language through imagery, spatial arrangement, and symbolic substitution, pose a unique challenge to current vision-language models (VLMs). Unlike traditional image captioning or question answering tasks, rebus solving requires multi-modal abstraction, symbolic reasoning, and a grasp of cultural, phonetic and linguistic puns. In this paper, we investigate the capacity of contemporary VLMs to interpret and solve rebus puzzles by constructing a hand-generated and annotated benchmark of diverse English-language rebus puzzles, ranging from simple pictographic substitutions to spatially-dependent cues ("head" over "heels"). We analyze how different VLMs perform, and our findings reveal that while VLMs exhibit some surprising capabilities in decoding simple visual clues, they struggle significantly with tasks requiring abstract reasoning, lateral thinking, and understanding visual metaphors.
Higher-Order Binding of Language Model Virtual Personas: a Study on Approximating Political Partisan Misperceptions
Apr 16, 2025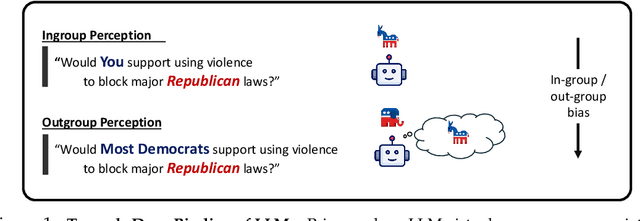
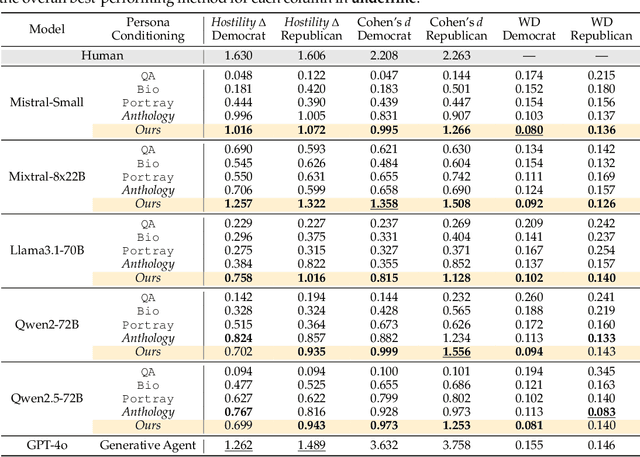

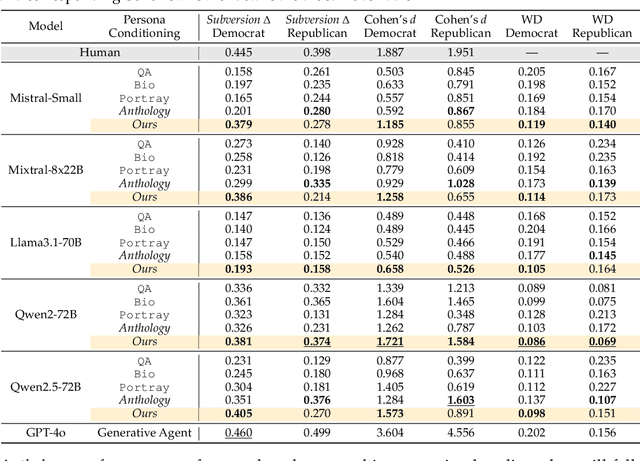
Large language models (LLMs) are increasingly capable of simulating human behavior, offering cost-effective ways to estimate user responses during the early phases of survey design. While previous studies have examined whether models can reflect individual opinions or attitudes, we argue that a \emph{higher-order} binding of virtual personas requires successfully approximating not only the opinions of a user as an identified member of a group, but also the nuanced ways in which that user perceives and evaluates those outside the group. In particular, faithfully simulating how humans perceive different social groups is critical for applying LLMs to various political science studies, including timely topics on polarization dynamics, inter-group conflict, and democratic backsliding. To this end, we propose a novel methodology for constructing virtual personas with synthetic user ``backstories" generated as extended, multi-turn interview transcripts. Our generated backstories are longer, rich in detail, and consistent in authentically describing a singular individual, compared to previous methods. We show that virtual personas conditioned on our backstories closely replicate human response distributions (up to an 87\% improvement as measured by Wasserstein Distance) and produce effect sizes that closely match those observed in the original studies. Altogether, our work extends the applicability of LLMs beyond estimating individual self-opinions, enabling their use in a broader range of human studies.
Language Model Fine-Tuning on Scaled Survey Data for Predicting Distributions of Public Opinions
Feb 24, 2025Large language models (LLMs) present novel opportunities in public opinion research by predicting survey responses in advance during the early stages of survey design. Prior methods steer LLMs via descriptions of subpopulations as LLMs' input prompt, yet such prompt engineering approaches have struggled to faithfully predict the distribution of survey responses from human subjects. In this work, we propose directly fine-tuning LLMs to predict response distributions by leveraging unique structural characteristics of survey data. To enable fine-tuning, we curate SubPOP, a significantly scaled dataset of 3,362 questions and 70K subpopulation-response pairs from well-established public opinion surveys. We show that fine-tuning on SubPOP greatly improves the match between LLM predictions and human responses across various subpopulations, reducing the LLM-human gap by up to 46% compared to baselines, and achieves strong generalization to unseen surveys and subpopulations. Our findings highlight the potential of survey-based fine-tuning to improve opinion prediction for diverse, real-world subpopulations and therefore enable more efficient survey designs. Our code is available at https://github.com/JosephJeesungSuh/subpop.
High-Throughput SAT Sampling
Feb 12, 2025In this work, we present a novel technique for GPU-accelerated Boolean satisfiability (SAT) sampling. Unlike conventional sampling algorithms that directly operate on conjunctive normal form (CNF), our method transforms the logical constraints of SAT problems by factoring their CNF representations into simplified multi-level, multi-output Boolean functions. It then leverages gradient-based optimization to guide the search for a diverse set of valid solutions. Our method operates directly on the circuit structure of refactored SAT instances, reinterpreting the SAT problem as a supervised multi-output regression task. This differentiable technique enables independent bit-wise operations on each tensor element, allowing parallel execution of learning processes. As a result, we achieve GPU-accelerated sampling with significant runtime improvements ranging from $33.6\times$ to $523.6\times$ over state-of-the-art heuristic samplers. We demonstrate the superior performance of our sampling method through an extensive evaluation on $60$ instances from a public domain benchmark suite utilized in previous studies.
Rediscovering the Latent Dimensions of Personality with Large Language Models as Trait Descriptors
Sep 16, 2024



Assessing personality traits using large language models (LLMs) has emerged as an interesting and challenging area of research. While previous methods employ explicit questionnaires, often derived from the Big Five model of personality, we hypothesize that LLMs implicitly encode notions of personality when modeling next-token responses. To demonstrate this, we introduce a novel approach that uncovers latent personality dimensions in LLMs by applying singular value de-composition (SVD) to the log-probabilities of trait-descriptive adjectives. Our experiments show that LLMs "rediscover" core personality traits such as extraversion, agreeableness, conscientiousness, neuroticism, and openness without relying on direct questionnaire inputs, with the top-5 factors corresponding to Big Five traits explaining 74.3% of the variance in the latent space. Moreover, we can use the derived principal components to assess personality along the Big Five dimensions, and achieve improvements in average personality prediction accuracy of up to 5% over fine-tuned models, and up to 21% over direct LLM-based scoring techniques.
Virtual Personas for Language Models via an Anthology of Backstories
Jul 09, 2024
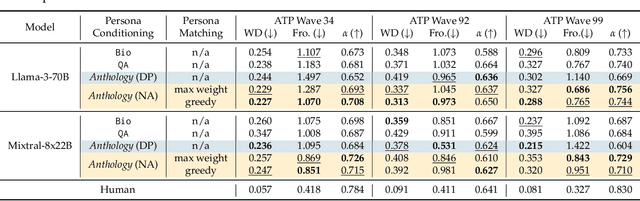
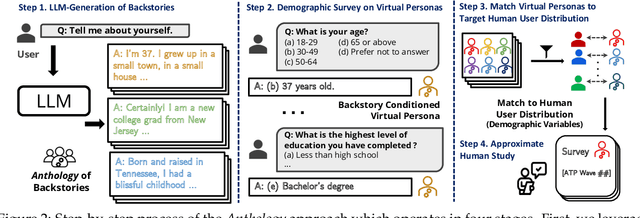

Large language models (LLMs) are trained from vast repositories of text authored by millions of distinct authors, reflecting an enormous diversity of human traits. While these models bear the potential to be used as approximations of human subjects in behavioral studies, prior efforts have been limited in steering model responses to match individual human users. In this work, we introduce "Anthology", a method for conditioning LLMs to particular virtual personas by harnessing open-ended life narratives, which we refer to as "backstories." We show that our methodology enhances the consistency and reliability of experimental outcomes while ensuring better representation of diverse sub-populations. Across three nationally representative human surveys conducted as part of Pew Research Center's American Trends Panel (ATP), we demonstrate that Anthology achieves up to 18% improvement in matching the response distributions of human respondents and 27% improvement in consistency metrics. Our code and generated backstories are available at https://github.com/CannyLab/anthology.
Full Stack Optimization of Transformer Inference: a Survey
Feb 27, 2023Recent advances in state-of-the-art DNN architecture design have been moving toward Transformer models. These models achieve superior accuracy across a wide range of applications. This trend has been consistent over the past several years since Transformer models were originally introduced. However, the amount of compute and bandwidth required for inference of recent Transformer models is growing at a significant rate, and this has made their deployment in latency-sensitive applications challenging. As such, there has been an increased focus on making Transformer models more efficient, with methods that range from changing the architecture design, all the way to developing dedicated domain-specific accelerators. In this work, we survey different approaches for efficient Transformer inference, including: (i) analysis and profiling of the bottlenecks in existing Transformer architectures and their similarities and differences with previous convolutional models; (ii) implications of Transformer architecture on hardware, including the impact of non-linear operations such as Layer Normalization, Softmax, and GELU, as well as linear operations, on hardware design; (iii) approaches for optimizing a fixed Transformer architecture; (iv) challenges in finding the right mapping and scheduling of operations for Transformer models; and (v) approaches for optimizing Transformer models by adapting the architecture using neural architecture search. Finally, we perform a case study by applying the surveyed optimizations on Gemmini, the open-source, full-stack DNN accelerator generator, and we show how each of these approaches can yield improvements, compared to previous benchmark results on Gemmini. Among other things, we find that a full-stack co-design approach with the aforementioned methods can result in up to 88.7x speedup with a minimal performance degradation for Transformer inference.