 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
Mar 22, 2024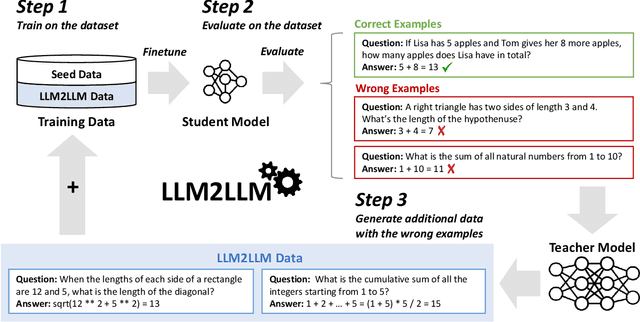
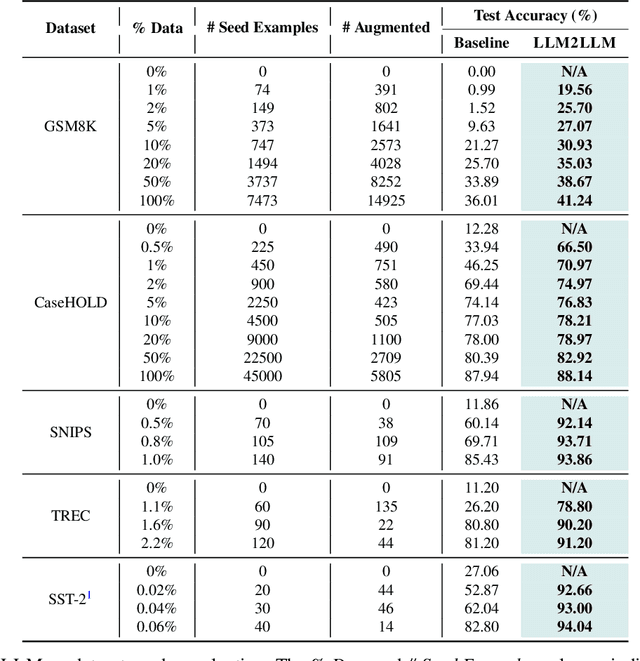
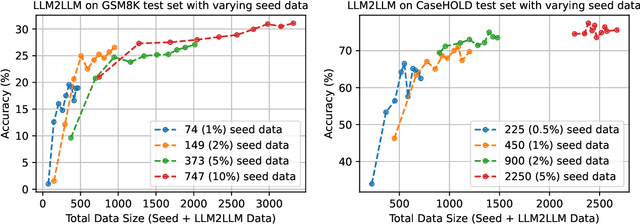
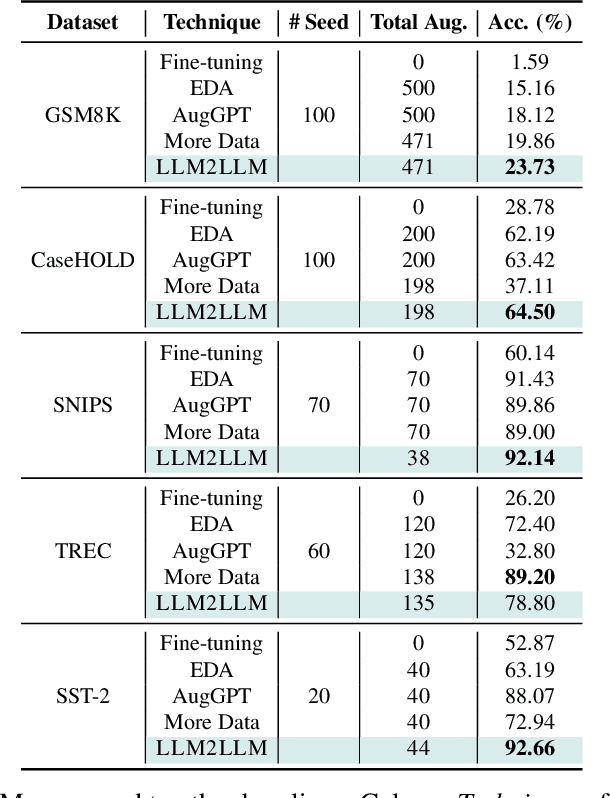
Pretrained large language models (LLMs) are currently state-of-the-art for solving the vast majority of natural language processing tasks. While many real-world applications still require fine-tuning to reach satisfactory levels of performance, many of them are in the low-data regime, making fine-tuning challenging. To address this, we propose LLM2LLM, a targeted and iterative data augmentation strategy that uses a teacher LLM to enhance a small seed dataset by augmenting additional data that can be used for fine-tuning on a specific task. LLM2LLM (1) fine-tunes a baseline student LLM on the initial seed data, (2) evaluates and extracts data points that the model gets wrong, and (3) uses a teacher LLM to generate synthetic data based on these incorrect data points, which are then added back into the training data. This approach amplifies the signal from incorrectly predicted data points by the LLM during training and reintegrates them into the dataset to focus on more challenging examples for the LLM. Our results show that LLM2LLM significantly enhances the performance of LLMs in the low-data regime, outperforming both traditional fine-tuning and other data augmentation baselines. LLM2LLM reduces the dependence on labor-intensive data curation and paves the way for more scalable and performant LLM solutions, allowing us to tackle data-constrained domains and tasks. We achieve improvements up to 24.2% on the GSM8K dataset, 32.6% on CaseHOLD, 32.0% on SNIPS, 52.6% on TREC and 39.8% on SST-2 over regular fine-tuning in the low-data regime using a LLaMA2-7B student model.
Full Stack Optimization of Transformer Inference: a Survey
Feb 27, 2023Recent advances in state-of-the-art DNN architecture design have been moving toward Transformer models. These models achieve superior accuracy across a wide range of applications. This trend has been consistent over the past several years since Transformer models were originally introduced. However, the amount of compute and bandwidth required for inference of recent Transformer models is growing at a significant rate, and this has made their deployment in latency-sensitive applications challenging. As such, there has been an increased focus on making Transformer models more efficient, with methods that range from changing the architecture design, all the way to developing dedicated domain-specific accelerators. In this work, we survey different approaches for efficient Transformer inference, including: (i) analysis and profiling of the bottlenecks in existing Transformer architectures and their similarities and differences with previous convolutional models; (ii) implications of Transformer architecture on hardware, including the impact of non-linear operations such as Layer Normalization, Softmax, and GELU, as well as linear operations, on hardware design; (iii) approaches for optimizing a fixed Transformer architecture; (iv) challenges in finding the right mapping and scheduling of operations for Transformer models; and (v) approaches for optimizing Transformer models by adapting the architecture using neural architecture search. Finally, we perform a case study by applying the surveyed optimizations on Gemmini, the open-source, full-stack DNN accelerator generator, and we show how each of these approaches can yield improvements, compared to previous benchmark results on Gemmini. Among other things, we find that a full-stack co-design approach with the aforementioned methods can result in up to 88.7x speedup with a minimal performance degradation for Transformer inference.