 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMist: Efficient Distributed Training of Large Language Models via Memory-Parallelism Co-Optimization
Mar 24, 2025Various parallelism, such as data, tensor, and pipeline parallelism, along with memory optimizations like activation checkpointing, redundancy elimination, and offloading, have been proposed to accelerate distributed training for Large Language Models. To find the best combination of these techniques, automatic distributed training systems are proposed. However, existing systems only tune a subset of optimizations, due to the lack of overlap awareness, inability to navigate the vast search space, and ignoring the inter-microbatch imbalance, leading to sub-optimal performance. To address these shortcomings, we propose Mist, a memory, overlap, and imbalance-aware automatic distributed training system that comprehensively co-optimizes all memory footprint reduction techniques alongside parallelism. Mist is based on three key ideas: (1) fine-grained overlap-centric scheduling, orchestrating optimizations in an overlapped manner, (2) symbolic-based performance analysis that predicts runtime and memory usage using symbolic expressions for fast tuning, and (3) imbalance-aware hierarchical tuning, decoupling the process into an inter-stage imbalance and overlap aware Mixed Integer Linear Programming problem and an intra-stage Dual-Objective Constrained Optimization problem, and connecting them through Pareto frontier sampling. Our evaluation results show that Mist achieves an average of 1.28$\times$ (up to 1.73$\times$) and 1.27$\times$ (up to 2.04$\times$) speedup compared to state-of-the-art manual system Megatron-LM and state-of-the-art automatic system Aceso, respectively.
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
Mar 22, 2024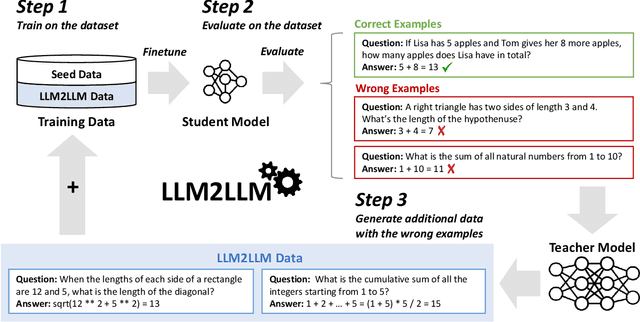
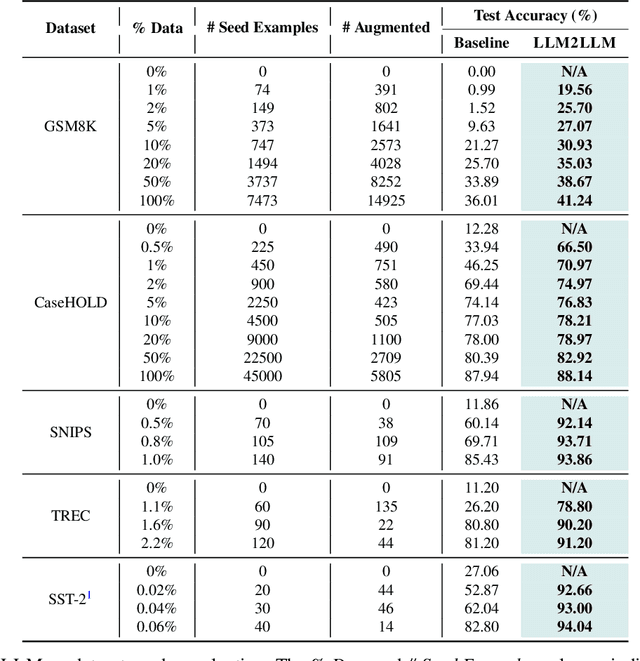
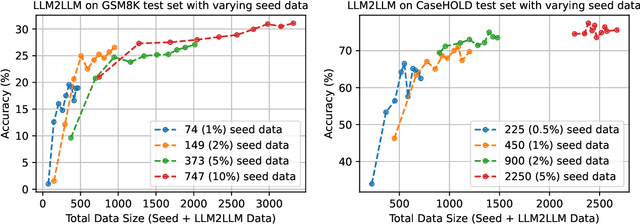
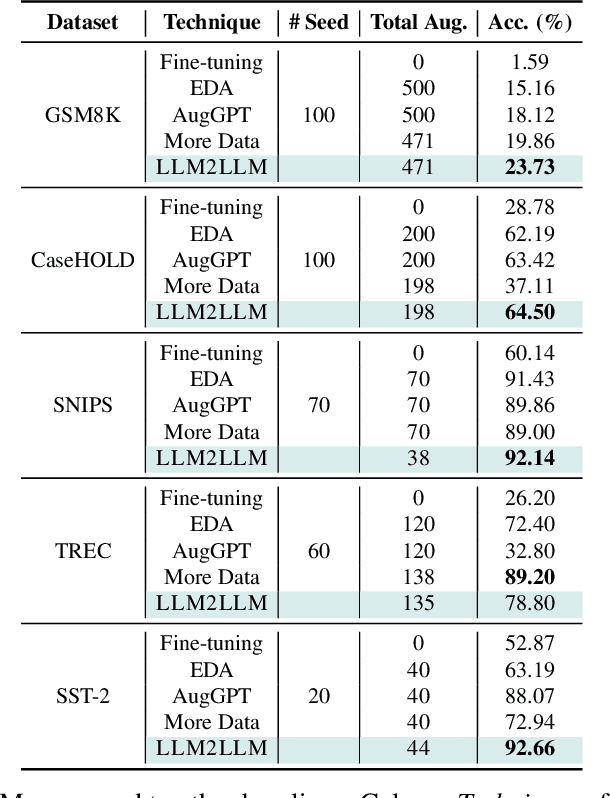
Pretrained large language models (LLMs) are currently state-of-the-art for solving the vast majority of natural language processing tasks. While many real-world applications still require fine-tuning to reach satisfactory levels of performance, many of them are in the low-data regime, making fine-tuning challenging. To address this, we propose LLM2LLM, a targeted and iterative data augmentation strategy that uses a teacher LLM to enhance a small seed dataset by augmenting additional data that can be used for fine-tuning on a specific task. LLM2LLM (1) fine-tunes a baseline student LLM on the initial seed data, (2) evaluates and extracts data points that the model gets wrong, and (3) uses a teacher LLM to generate synthetic data based on these incorrect data points, which are then added back into the training data. This approach amplifies the signal from incorrectly predicted data points by the LLM during training and reintegrates them into the dataset to focus on more challenging examples for the LLM. Our results show that LLM2LLM significantly enhances the performance of LLMs in the low-data regime, outperforming both traditional fine-tuning and other data augmentation baselines. LLM2LLM reduces the dependence on labor-intensive data curation and paves the way for more scalable and performant LLM solutions, allowing us to tackle data-constrained domains and tasks. We achieve improvements up to 24.2% on the GSM8K dataset, 32.6% on CaseHOLD, 32.0% on SNIPS, 52.6% on TREC and 39.8% on SST-2 over regular fine-tuning in the low-data regime using a LLaMA2-7B student model.
xT: Nested Tokenization for Larger Context in Large Images
Mar 04, 2024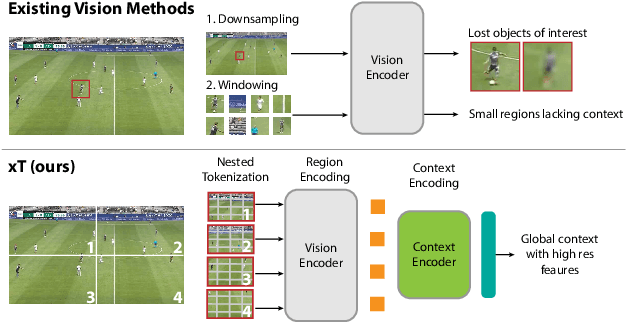
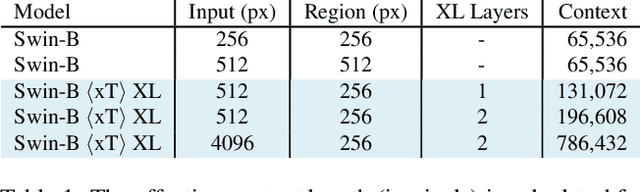
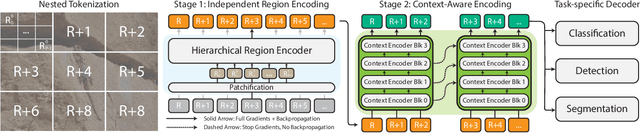
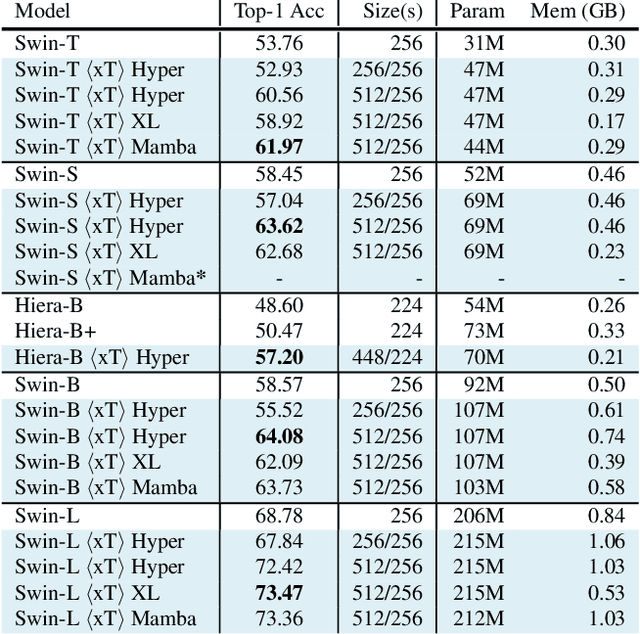
Modern computer vision pipelines handle large images in one of two sub-optimal ways: down-sampling or cropping. These two methods incur significant losses in the amount of information and context present in an image. There are many downstream applications in which global context matters as much as high frequency details, such as in real-world satellite imagery; in such cases researchers have to make the uncomfortable choice of which information to discard. We introduce xT, a simple framework for vision transformers which effectively aggregates global context with local details and can model large images end-to-end on contemporary GPUs. We select a set of benchmark datasets across classic vision tasks which accurately reflect a vision model's ability to understand truly large images and incorporate fine details over large scales and assess our method's improvement on them. By introducing a nested tokenization scheme for large images in conjunction with long-sequence length models normally used for natural language processing, we are able to increase accuracy by up to 8.6% on challenging classification tasks and $F_1$ score by 11.6 on context-dependent segmentation in large images.
Do Vision and Language Encoders Represent the World Similarly?
Jan 10, 2024



Aligned text-image encoders such as CLIP have become the de facto model for vision-language tasks. Furthermore, modality-specific encoders achieve impressive performances in their respective domains. This raises a central question: does an alignment exist between uni-modal vision and language encoders since they fundamentally represent the same physical world? Analyzing the latent spaces structure of vision and language models on image-caption benchmarks using the Centered Kernel Alignment (CKA), we find that the representation spaces of unaligned and aligned encoders are semantically similar. In the absence of statistical similarity in aligned encoders like CLIP, we show that a possible matching of unaligned encoders exists without any training. We frame this as a seeded graph-matching problem exploiting the semantic similarity between graphs and propose two methods - a Fast Quadratic Assignment Problem optimization, and a novel localized CKA metric-based matching/retrieval. We demonstrate the effectiveness of this on several downstream tasks including cross-lingual, cross-domain caption matching and image classification.
Dr$^2$Net: Dynamic Reversible Dual-Residual Networks for Memory-Efficient Finetuning
Jan 08, 2024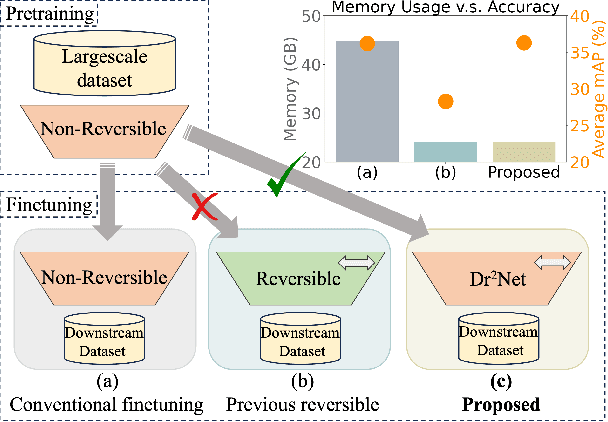

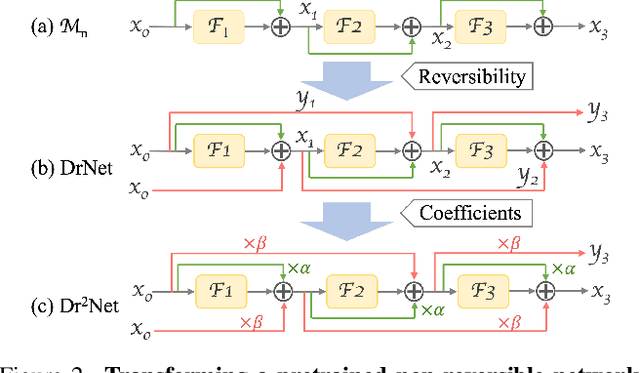
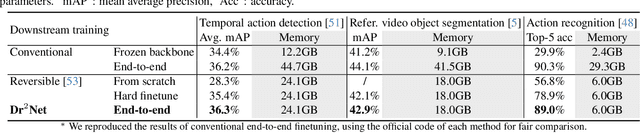
Large pretrained models are increasingly crucial in modern computer vision tasks. These models are typically used in downstream tasks by end-to-end finetuning, which is highly memory-intensive for tasks with high-resolution data, e.g., video understanding, small object detection, and point cloud analysis. In this paper, we propose Dynamic Reversible Dual-Residual Networks, or Dr$^2$Net, a novel family of network architectures that acts as a surrogate network to finetune a pretrained model with substantially reduced memory consumption. Dr$^2$Net contains two types of residual connections, one maintaining the residual structure in the pretrained models, and the other making the network reversible. Due to its reversibility, intermediate activations, which can be reconstructed from output, are cleared from memory during training. We use two coefficients on either type of residual connections respectively, and introduce a dynamic training strategy that seamlessly transitions the pretrained model to a reversible network with much higher numerical precision. We evaluate Dr$^2$Net on various pretrained models and various tasks, and show that it can reach comparable performance to conventional finetuning but with significantly less memory usage.
Adaptive Human Trajectory Prediction via Latent Corridors
Dec 11, 2023



Human trajectory prediction is typically posed as a zero-shot generalization problem: a predictor is learnt on a dataset of human motion in training scenes, and then deployed on unseen test scenes. While this paradigm has yielded tremendous progress, it fundamentally assumes that trends in human behavior within the deployment scene are constant over time. As such, current prediction models are unable to adapt to scene-specific transient human behaviors, such as crowds temporarily gathering to see buskers, pedestrians hurrying through the rain and avoiding puddles, or a protest breaking out. We formalize the problem of scene-specific adaptive trajectory prediction and propose a new adaptation approach inspired by prompt tuning called latent corridors. By augmenting the input of any pre-trained human trajectory predictor with learnable image prompts, the predictor can improve in the deployment scene by inferring trends from extremely small amounts of new data (e.g., 2 humans observed for 30 seconds). With less than 0.1% additional model parameters, we see up to 23.9% ADE improvement in MOTSynth simulated data and 16.4% ADE in MOT and Wildtrack real pedestrian data. Qualitatively, we observe that latent corridors imbue predictors with an awareness of scene geometry and scene-specific human behaviors that non-adaptive predictors struggle to capture. The project website can be found at https://neerja.me/atp_latent_corridors/.
Sequential Modeling Enables Scalable Learning for Large Vision Models
Dec 01, 2023
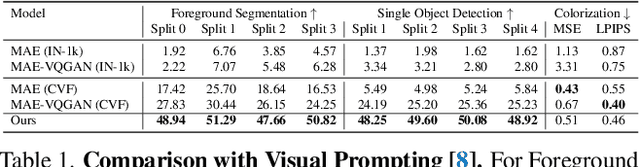
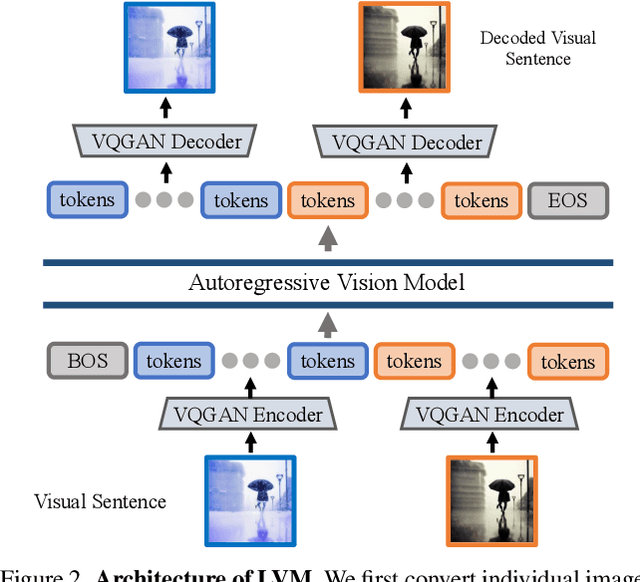
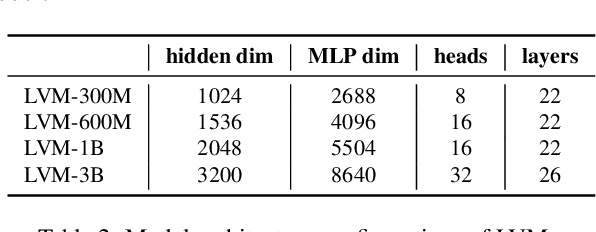
We introduce a novel sequential modeling approach which enables learning a Large Vision Model (LVM) without making use of any linguistic data. To do this, we define a common format, "visual sentences", in which we can represent raw images and videos as well as annotated data sources such as semantic segmentations and depth reconstructions without needing any meta-knowledge beyond the pixels. Once this wide variety of visual data (comprising 420 billion tokens) is represented as sequences, the model can be trained to minimize a cross-entropy loss for next token prediction. By training across various scales of model architecture and data diversity, we provide empirical evidence that our models scale effectively. Many different vision tasks can be solved by designing suitable visual prompts at test time.
EgoSchema: A Diagnostic Benchmark for Very Long-form Video Language Understanding
Aug 17, 2023



We introduce EgoSchema, a very long-form video question-answering dataset, and benchmark to evaluate long video understanding capabilities of modern vision and language systems. Derived from Ego4D, EgoSchema consists of over 5000 human curated multiple choice question answer pairs, spanning over 250 hours of real video data, covering a very broad range of natural human activity and behavior. For each question, EgoSchema requires the correct answer to be selected between five given options based on a three-minute-long video clip. While some prior works have proposed video datasets with long clip lengths, we posit that merely the length of the video clip does not truly capture the temporal difficulty of the video task that is being considered. To remedy this, we introduce temporal certificate sets, a general notion for capturing the intrinsic temporal understanding length associated with a broad range of video understanding tasks & datasets. Based on this metric, we find EgoSchema to have intrinsic temporal lengths over 5.7x longer than the second closest dataset and 10x to 100x longer than any other video understanding dataset. Further, our evaluation of several current state-of-the-art video and language models shows them to be severely lacking in long-term video understanding capabilities. Even models with several billions of parameters achieve QA accuracy less than 33% (random is 20%) on the EgoSchema multi-choice question answering task, while humans achieve about 76% accuracy. We posit that \name{}{}, with its long intrinsic temporal structures and diverse complexity, would serve as a valuable evaluation probe for developing effective long-term video understanding systems in the future. Data and Zero-shot model evaluation code are open-sourced for both public and commercial use under the Ego4D license at http://egoschema.github.io
PaReprop: Fast Parallelized Reversible Backpropagation
Jun 15, 2023

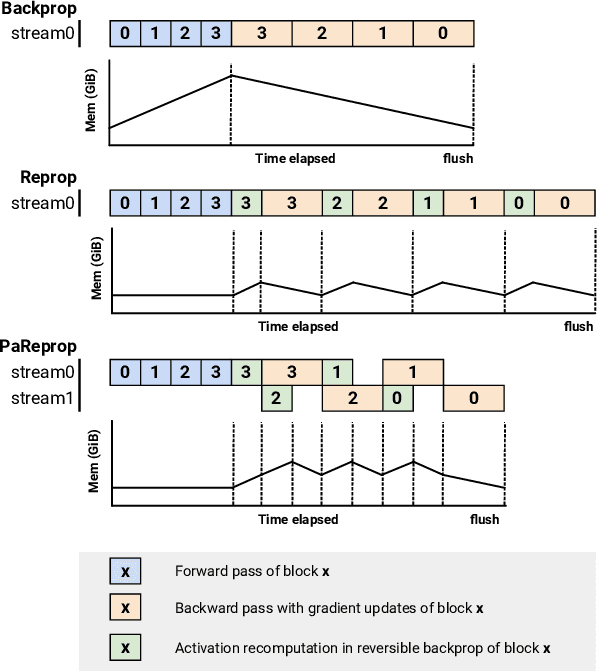
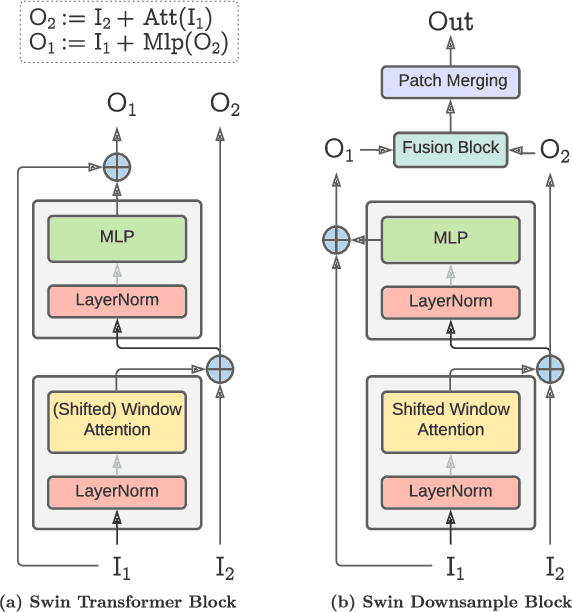
The growing size of datasets and deep learning models has made faster and memory-efficient training crucial. Reversible transformers have recently been introduced as an exciting new method for extremely memory-efficient training, but they come with an additional computation overhead of activation re-computation in the backpropagation phase. We present PaReprop, a fast Parallelized Reversible Backpropagation algorithm that parallelizes the additional activation re-computation overhead in reversible training with the gradient computation itself in backpropagation phase. We demonstrate the effectiveness of the proposed PaReprop algorithm through extensive benchmarking across model families (ViT, MViT, Swin and RoBERTa), data modalities (Vision & NLP), model sizes (from small to giant), and training batch sizes. Our empirical results show that PaReprop achieves up to 20% higher training throughput than vanilla reversible training, largely mitigating the theoretical overhead of 25% lower throughput from activation recomputation in reversible training. Project page: https://tylerzhu.com/pareprop.
Diffusion Models as Masked Autoencoders
Apr 06, 2023



There has been a longstanding belief that generation can facilitate a true understanding of visual data. In line with this, we revisit generatively pre-training visual representations in light of recent interest in denoising diffusion models. While directly pre-training with diffusion models does not produce strong representations, we condition diffusion models on masked input and formulate diffusion models as masked autoencoders (DiffMAE). Our approach is capable of (i) serving as a strong initialization for downstream recognition tasks, (ii) conducting high-quality image inpainting, and (iii) being effortlessly extended to video where it produces state-of-the-art classification accuracy. We further perform a comprehensive study on the pros and cons of design choices and build connections between diffusion models and masked autoencoders.