 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaReprop: Fast Parallelized Reversible Backpropagation
Paper and Code
Jun 15, 2023

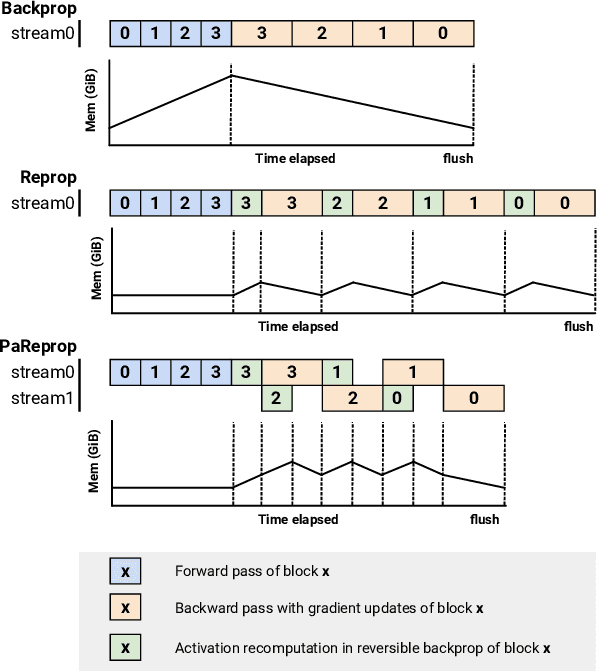
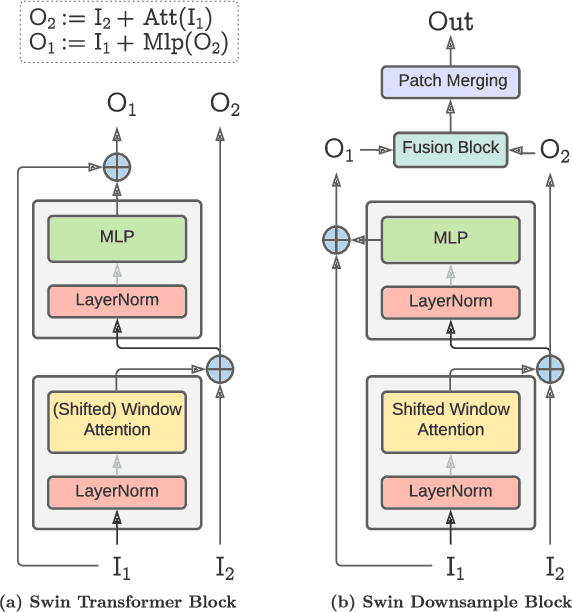
The growing size of datasets and deep learning models has made faster and memory-efficient training crucial. Reversible transformers have recently been introduced as an exciting new method for extremely memory-efficient training, but they come with an additional computation overhead of activation re-computation in the backpropagation phase. We present PaReprop, a fast Parallelized Reversible Backpropagation algorithm that parallelizes the additional activation re-computation overhead in reversible training with the gradient computation itself in backpropagation phase. We demonstrate the effectiveness of the proposed PaReprop algorithm through extensive benchmarking across model families (ViT, MViT, Swin and RoBERTa), data modalities (Vision & NLP), model sizes (from small to giant), and training batch sizes. Our empirical results show that PaReprop achieves up to 20% higher training throughput than vanilla reversible training, largely mitigating the theoretical overhead of 25% lower throughput from activation recomputation in reversible training. Project page: https://tylerzhu.com/pareprop.