 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMist: Efficient Distributed Training of Large Language Models via Memory-Parallelism Co-Optimization
Mar 24, 2025Various parallelism, such as data, tensor, and pipeline parallelism, along with memory optimizations like activation checkpointing, redundancy elimination, and offloading, have been proposed to accelerate distributed training for Large Language Models. To find the best combination of these techniques, automatic distributed training systems are proposed. However, existing systems only tune a subset of optimizations, due to the lack of overlap awareness, inability to navigate the vast search space, and ignoring the inter-microbatch imbalance, leading to sub-optimal performance. To address these shortcomings, we propose Mist, a memory, overlap, and imbalance-aware automatic distributed training system that comprehensively co-optimizes all memory footprint reduction techniques alongside parallelism. Mist is based on three key ideas: (1) fine-grained overlap-centric scheduling, orchestrating optimizations in an overlapped manner, (2) symbolic-based performance analysis that predicts runtime and memory usage using symbolic expressions for fast tuning, and (3) imbalance-aware hierarchical tuning, decoupling the process into an inter-stage imbalance and overlap aware Mixed Integer Linear Programming problem and an intra-stage Dual-Objective Constrained Optimization problem, and connecting them through Pareto frontier sampling. Our evaluation results show that Mist achieves an average of 1.28$\times$ (up to 1.73$\times$) and 1.27$\times$ (up to 2.04$\times$) speedup compared to state-of-the-art manual system Megatron-LM and state-of-the-art automatic system Aceso, respectively.
Seesaw: High-throughput LLM Inference via Model Re-sharding
Mar 09, 2025To improve the efficiency of distributed large language model (LLM) inference, various parallelization strategies, such as tensor and pipeline parallelism, have been proposed. However, the distinct computational characteristics inherent in the two stages of LLM inference-prefilling and decoding-render a single static parallelization strategy insufficient for the effective optimization of both stages. In this work, we present Seesaw, an LLM inference engine optimized for throughput-oriented tasks. The key idea behind Seesaw is dynamic model re-sharding, a technique that facilitates the dynamic reconfiguration of parallelization strategies across stages, thereby maximizing throughput at both phases. To mitigate re-sharding overhead and optimize computational efficiency, we employ tiered KV cache buffering and transition-minimizing scheduling. These approaches work synergistically to reduce the overhead caused by frequent stage transitions while ensuring maximum batching efficiency. Our evaluation demonstrates that Seesaw achieves a throughput increase of up to 1.78x (1.36x on average) compared to vLLM, the most widely used state-of-the-art LLM inference engine.
APPL: A Prompt Programming Language for Harmonious Integration of Programs and Large Language Model Prompts
Jun 19, 2024Large Language Models (LLMs) have become increasingly capable of handling diverse tasks with the aid of well-crafted prompts and integration of external tools, but as task complexity rises, the workflow involving LLMs can be complicated and thus challenging to implement and maintain. To address this challenge, we propose APPL, A Prompt Programming Language that acts as a bridge between computer programs and LLMs, allowing seamless embedding of prompts into Python functions, and vice versa. APPL provides an intuitive and Python-native syntax, an efficient parallelized runtime with asynchronous semantics, and a tracing module supporting effective failure diagnosis and replaying without extra costs. We demonstrate that APPL programs are intuitive, concise, and efficient through three representative scenarios: Chain-of-Thought with self-consistency (CoT-SC), ReAct tool use agent, and multi-agent chat. Experiments on three parallelizable workflows further show that APPL can effectively parallelize independent LLM calls, with a significant speedup ratio that almost matches the estimation.
The Synergy of Speculative Decoding and Batching in Serving Large Language Models
Oct 28, 2023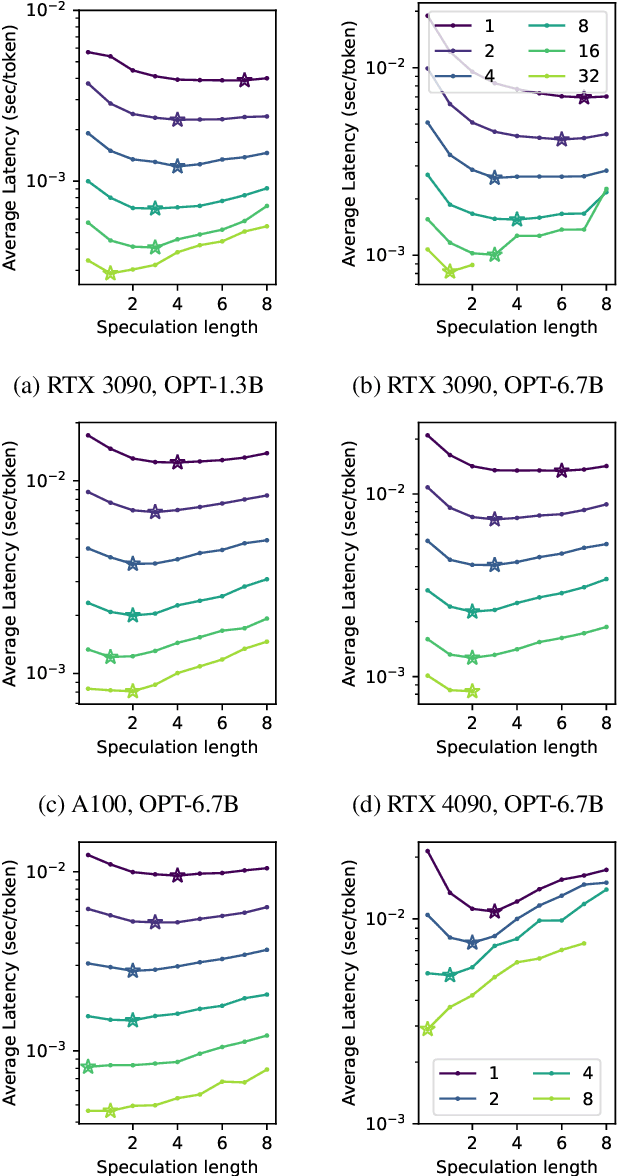
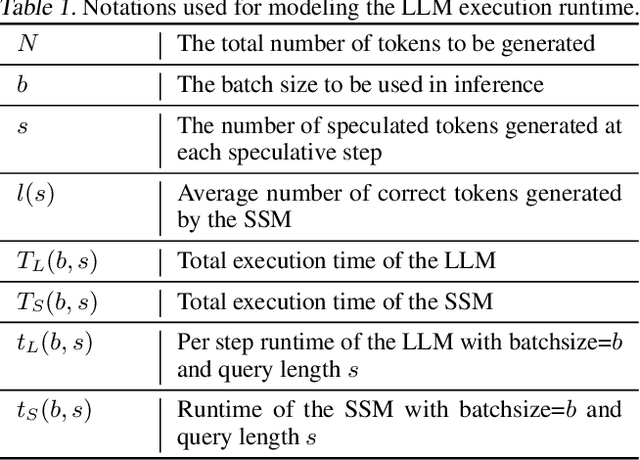
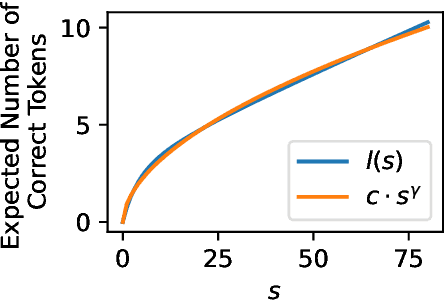
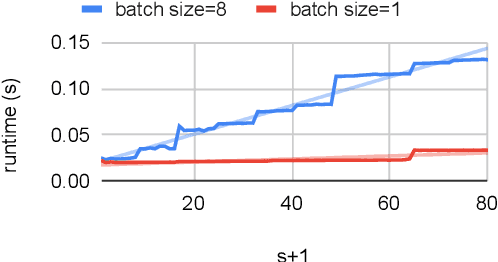
Large Language Models (LLMs) like GPT are state-of-the-art text generation models that provide significant assistance in daily routines. However, LLM execution is inherently sequential, since they only produce one token at a time, thus incurring low hardware utilization on modern GPUs. Batching and speculative decoding are two techniques to improve GPU hardware utilization in LLM inference. To study their synergy, we implement a prototype implementation and perform an extensive characterization analysis on various LLM models and GPU architectures. We observe that the optimal speculation length depends on the batch size used. We analyze the key observation and build a quantitative model to explain it. Based on our analysis, we propose a new adaptive speculative decoding strategy that chooses the optimal speculation length for different batch sizes. Our evaluations show that our proposed method can achieve equal or better performance than the state-of-the-art speculation decoding schemes with fixed speculation length.
DistDGL: Distributed Graph Neural Network Training for Billion-Scale Graphs
Oct 16, 2020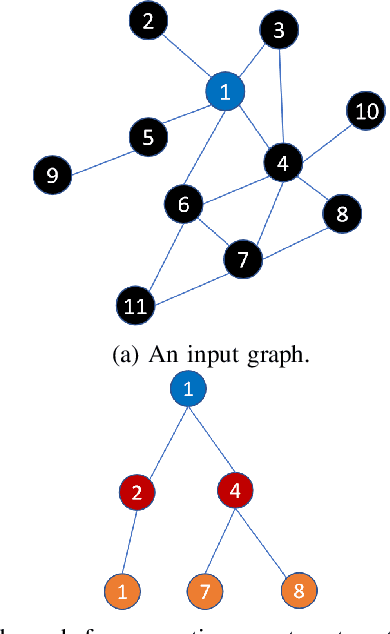
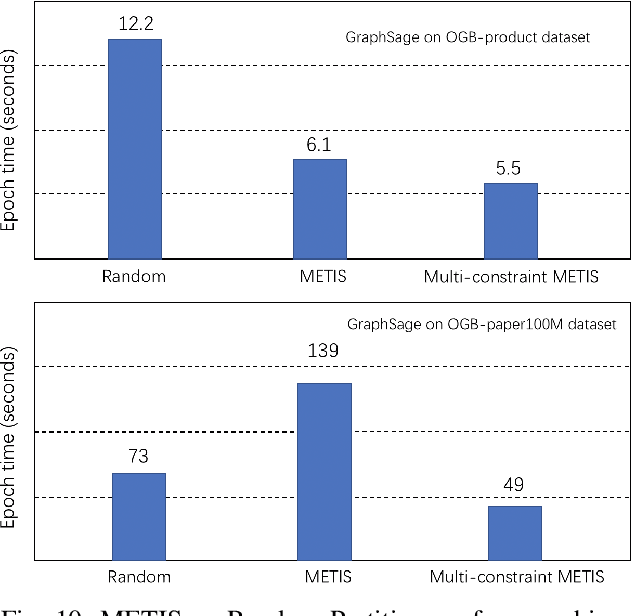
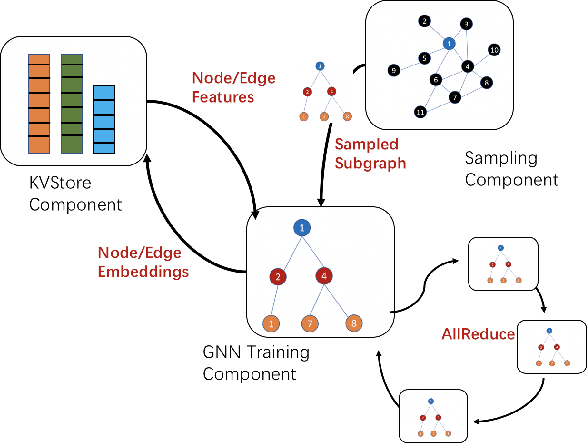
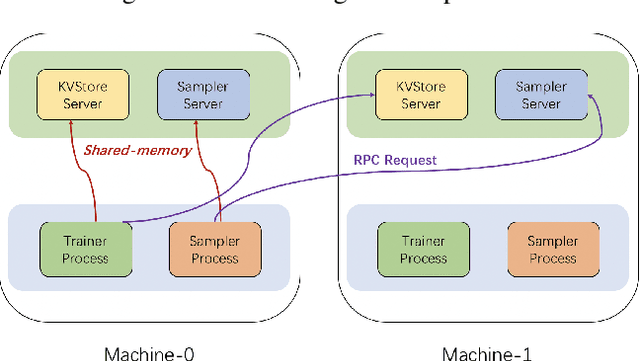
Graph neural networks (GNN) have shown great success in learning from graph-structured data. They are widely used in various applications, such as recommendation, fraud detection, and search. In these domains, the graphs are typically large, containing hundreds of millions of nodes and several billions of edges. To tackle this challenge, we develop DistDGL, a system for training GNNs in a mini-batch fashion on a cluster of machines. DistDGL is based on the Deep Graph Library (DGL), a popular GNN development framework. DistDGL distributes the graph and its associated data (initial features and embeddings) across the machines and uses this distribution to derive a computational decomposition by following an owner-compute rule. DistDGL follows a synchronous training approach and allows ego-networks forming the mini-batches to include non-local nodes. To minimize the overheads associated with distributed computations, DistDGL uses a high-quality and light-weight min-cut graph partitioning algorithm along with multiple balancing constraints. This allows it to reduce communication overheads and statically balance the computations. It further reduces the communication by replicating halo nodes and by using sparse embedding updates. The combination of these design choices allows DistDGL to train high-quality models while achieving high parallel efficiency and memory scalability. We demonstrate our optimizations on both inductive and transductive GNN models. Our results show that DistDGL achieves linear speedup without compromising model accuracy and requires only 13 seconds to complete a training epoch for a graph with 100 million nodes and 3 billion edges on a cluster with 16 machines.