 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
EffiReason-Bench: A Unified Benchmark for Evaluating and Advancing Efficient Reasoning in Large Language Models
Nov 13, 2025



Large language models (LLMs) with Chain-of-Thought (CoT) prompting achieve strong reasoning but often produce unnecessarily long explanations, increasing cost and sometimes reducing accuracy. Fair comparison of efficiency-oriented approaches is hindered by fragmented evaluation practices. We introduce EffiReason-Bench, a unified benchmark for rigorous cross-paradigm evaluation of efficient reasoning methods across three categories: Reasoning Blueprints, Dynamic Execution, and Post-hoc Refinement. To enable step-by-step evaluation, we construct verified CoT annotations for CommonsenseQA and LogiQA via a pipeline that enforces standardized reasoning structures, comprehensive option-wise analysis, and human verification. We evaluate 7 methods across 6 open-source LLMs (1B-70B) on 4 datasets spanning mathematics, commonsense, and logic, and propose the E3-Score, a principled metric inspired by economic trade-off modeling that provides smooth, stable evaluation without discontinuities or heavy reliance on heuristics. Experiments show that no single method universally dominates; optimal strategies depend on backbone scale, task complexity, and architecture.
DPQuant: Efficient and Differentially-Private Model Training via Dynamic Quantization Scheduling
Sep 03, 2025Differentially-Private SGD (DP-SGD) is a powerful technique to protect user privacy when using sensitive data to train neural networks. During training, converting model weights and activations into low-precision formats, i.e., quantization, can drastically reduce training times, energy consumption, and cost, and is thus a widely used technique. In this work, we demonstrate that quantization causes significantly higher accuracy degradation in DP-SGD compared to regular SGD. We observe that this is caused by noise injection in DP-SGD, which amplifies quantization variance, leading to disproportionately large accuracy degradation. To address this challenge, we present QPQuant, a dynamic quantization framework that adaptively selects a changing subset of layers to quantize at each epoch. Our method combines two key ideas that effectively reduce quantization variance: (i) probabilistic sampling of the layers that rotates which layers are quantized every epoch, and (ii) loss-aware layer prioritization, which uses a differentially private loss sensitivity estimator to identify layers that can be quantized with minimal impact on model quality. This estimator consumes a negligible fraction of the overall privacy budget, preserving DP guarantees. Empirical evaluations on ResNet18, ResNet50, and DenseNet121 across a range of datasets demonstrate that DPQuant consistently outperforms static quantization baselines, achieving near Pareto-optimal accuracy-compute trade-offs and up to 2.21x theoretical throughput improvements on low-precision hardware, with less than 2% drop in validation accuracy.
Unveiling Instruction-Specific Neurons & Experts: An Analytical Framework for LLM's Instruction-Following Capabilities
May 27, 2025The finetuning of Large Language Models (LLMs) has significantly advanced their instruction-following capabilities, yet the underlying computational mechanisms driving these improvements remain poorly understood. This study systematically examines how fine-tuning reconfigures LLM computations by isolating and analyzing instruction-specific sparse components, i.e., neurons in dense models and both neurons and experts in Mixture-of-Experts (MoE) architectures. In particular, we introduce HexaInst, a carefully curated and balanced instructional dataset spanning six distinct categories, and propose SPARCOM, a novel analytical framework comprising three key contributions: (1) a method for identifying these sparse components, (2) an evaluation of their functional generality and uniqueness, and (3) a systematic comparison of their alterations. Through experiments, we demonstrate functional generality, uniqueness, and the critical role of these components in instruction execution. By elucidating the relationship between fine-tuning-induced adaptations and sparse computational substrates, this work provides deeper insights into how LLMs internalize instruction-following behavior for the trustworthy LLM community.
Do BERT-Like Bidirectional Models Still Perform Better on Text Classification in the Era of LLMs?
May 23, 2025The rapid adoption of LLMs has overshadowed the potential advantages of traditional BERT-like models in text classification. This study challenges the prevailing "LLM-centric" trend by systematically comparing three category methods, i.e., BERT-like models fine-tuning, LLM internal state utilization, and zero-shot inference across six high-difficulty datasets. Our findings reveal that BERT-like models often outperform LLMs. We further categorize datasets into three types, perform PCA and probing experiments, and identify task-specific model strengths: BERT-like models excel in pattern-driven tasks, while LLMs dominate those requiring deep semantics or world knowledge. Based on this, we propose TaMAS, a fine-grained task selection strategy, advocating for a nuanced, task-driven approach over a one-size-fits-all reliance on LLMs.
PhysicsArena: The First Multimodal Physics Reasoning Benchmark Exploring Variable, Process, and Solution Dimensions
May 21, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in diverse reasoning tasks, yet their application to complex physics reasoning remains underexplored. Physics reasoning presents unique challenges, requiring grounding in physical conditions and the interpretation of multimodal information. Current physics benchmarks are limited, often focusing on text-only inputs or solely on problem-solving, thereby overlooking the critical intermediate steps of variable identification and process formulation. To address these limitations, we introduce PhysicsArena, the first multimodal physics reasoning benchmark designed to holistically evaluate MLLMs across three critical dimensions: variable identification, physical process formulation, and solution derivation. PhysicsArena aims to provide a comprehensive platform for assessing and advancing the multimodal physics reasoning abilities of MLLMs.
CoheMark: A Novel Sentence-Level Watermark for Enhanced Text Quality
Apr 24, 2025Watermarking technology is a method used to trace the usage of content generated by large language models. Sentence-level watermarking aids in preserving the semantic integrity within individual sentences while maintaining greater robustness. However, many existing sentence-level watermarking techniques depend on arbitrary segmentation or generation processes to embed watermarks, which can limit the availability of appropriate sentences. This limitation, in turn, compromises the quality of the generated response. To address the challenge of balancing high text quality with robust watermark detection, we propose CoheMark, an advanced sentence-level watermarking technique that exploits the cohesive relationships between sentences for better logical fluency. The core methodology of CoheMark involves selecting sentences through trained fuzzy c-means clustering and applying specific next sentence selection criteria. Experimental evaluations demonstrate that CoheMark achieves strong watermark strength while exerting minimal impact on text quality.
APPL: A Prompt Programming Language for Harmonious Integration of Programs and Large Language Model Prompts
Jun 19, 2024Large Language Models (LLMs) have become increasingly capable of handling diverse tasks with the aid of well-crafted prompts and integration of external tools, but as task complexity rises, the workflow involving LLMs can be complicated and thus challenging to implement and maintain. To address this challenge, we propose APPL, A Prompt Programming Language that acts as a bridge between computer programs and LLMs, allowing seamless embedding of prompts into Python functions, and vice versa. APPL provides an intuitive and Python-native syntax, an efficient parallelized runtime with asynchronous semantics, and a tracing module supporting effective failure diagnosis and replaying without extra costs. We demonstrate that APPL programs are intuitive, concise, and efficient through three representative scenarios: Chain-of-Thought with self-consistency (CoT-SC), ReAct tool use agent, and multi-agent chat. Experiments on three parallelizable workflows further show that APPL can effectively parallelize independent LLM calls, with a significant speedup ratio that almost matches the estimation.
Proteus: Preserving Model Confidentiality during Graph Optimizations
Apr 18, 2024
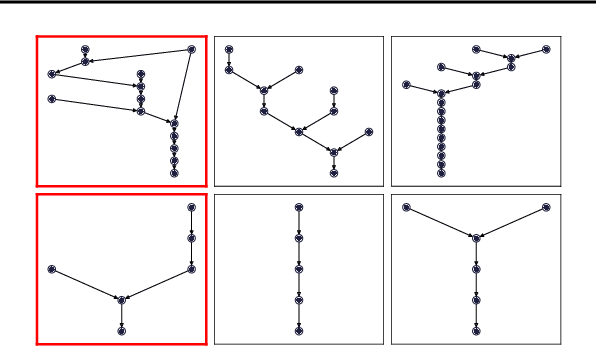
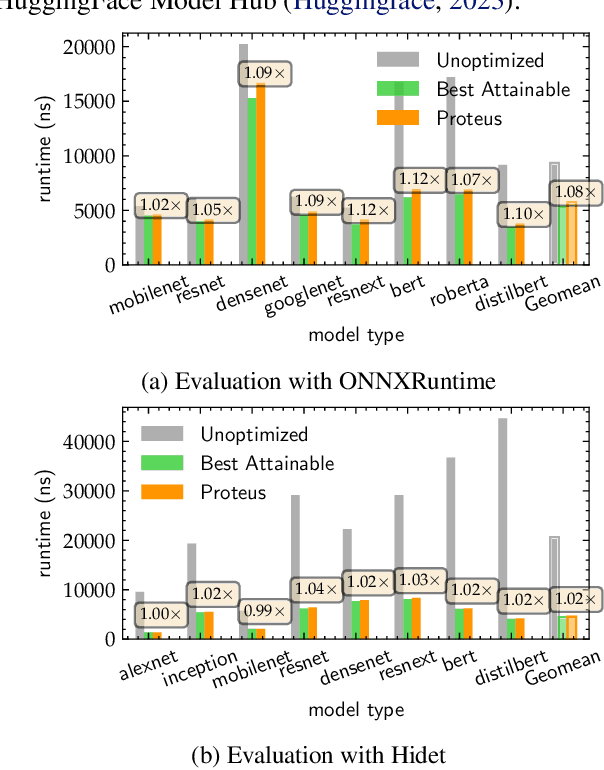
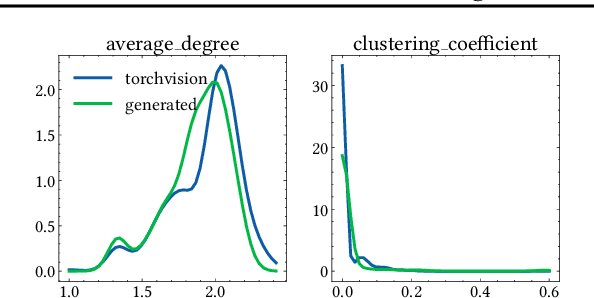
Deep learning (DL) models have revolutionized numerous domains, yet optimizing them for computational efficiency remains a challenging endeavor. Development of new DL models typically involves two parties: the model developers and performance optimizers. The collaboration between the parties often necessitates the model developers exposing the model architecture and computational graph to the optimizers. However, this exposure is undesirable since the model architecture is an important intellectual property, and its innovations require significant investments and expertise. During the exchange, the model is also vulnerable to adversarial attacks via model stealing. This paper presents Proteus, a novel mechanism that enables model optimization by an independent party while preserving the confidentiality of the model architecture. Proteus obfuscates the protected model by partitioning its computational graph into subgraphs and concealing each subgraph within a large pool of generated realistic subgraphs that cannot be easily distinguished from the original. We evaluate Proteus on a range of DNNs, demonstrating its efficacy in preserving confidentiality without compromising performance optimization opportunities. Proteus effectively hides the model as one alternative among up to $10^{32}$ possible model architectures, and is resilient against attacks with a learning-based adversary. We also demonstrate that heuristic based and manual approaches are ineffective in identifying the protected model. To our knowledge, Proteus is the first work that tackles the challenge of model confidentiality during performance optimization. Proteus will be open-sourced for direct use and experimentation, with easy integration with compilers such as ONNXRuntime.