 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tensor Compiler for Processing-In-Memory Architectures
Nov 19, 2025Processing-In-Memory (PIM) devices integrated with high-performance Host processors (e.g., GPUs) can accelerate memory-intensive kernels in Machine Learning (ML) models, including Large Language Models (LLMs), by leveraging high memory bandwidth at PIM cores. However, Host processors and PIM cores require different data layouts: Hosts need consecutive elements distributed across DRAM banks, while PIM cores need them within local banks. This necessitates data rearrangements in ML kernel execution that pose significant performance and programmability challenges, further exacerbated by the need to support diverse PIM backends. Current compilation approaches lack systematic optimization for diverse ML kernels across multiple PIM backends and may largely ignore data rearrangements during compute code optimization. We demonstrate that data rearrangements and compute code optimization are interdependent, and need to be jointly optimized during the tuning process. To address this, we design DCC, the first data-centric ML compiler for PIM systems that jointly co-optimizes data rearrangements and compute code in a unified tuning process. DCC integrates a multi-layer PIM abstraction that enables various data distribution and processing strategies on different PIM backends. DCC enables effective co-optimization by mapping data partitioning strategies to compute loop partitions, applying PIM-specific code optimizations and leveraging a fast and accurate performance prediction model to select optimal configurations. Our evaluations in various individual ML kernels demonstrate that DCC achieves up to 7.68x speedup (2.7x average) on HBM-PIM and up to 13.17x speedup (5.75x average) on AttAcc PIM backend over GPU-only execution. In end-to-end LLM inference, DCC on AttAcc accelerates GPT-3 and LLaMA-2 by up to 7.71x (4.88x average) over GPU.
Mist: Efficient Distributed Training of Large Language Models via Memory-Parallelism Co-Optimization
Mar 24, 2025Various parallelism, such as data, tensor, and pipeline parallelism, along with memory optimizations like activation checkpointing, redundancy elimination, and offloading, have been proposed to accelerate distributed training for Large Language Models. To find the best combination of these techniques, automatic distributed training systems are proposed. However, existing systems only tune a subset of optimizations, due to the lack of overlap awareness, inability to navigate the vast search space, and ignoring the inter-microbatch imbalance, leading to sub-optimal performance. To address these shortcomings, we propose Mist, a memory, overlap, and imbalance-aware automatic distributed training system that comprehensively co-optimizes all memory footprint reduction techniques alongside parallelism. Mist is based on three key ideas: (1) fine-grained overlap-centric scheduling, orchestrating optimizations in an overlapped manner, (2) symbolic-based performance analysis that predicts runtime and memory usage using symbolic expressions for fast tuning, and (3) imbalance-aware hierarchical tuning, decoupling the process into an inter-stage imbalance and overlap aware Mixed Integer Linear Programming problem and an intra-stage Dual-Objective Constrained Optimization problem, and connecting them through Pareto frontier sampling. Our evaluation results show that Mist achieves an average of 1.28$\times$ (up to 1.73$\times$) and 1.27$\times$ (up to 2.04$\times$) speedup compared to state-of-the-art manual system Megatron-LM and state-of-the-art automatic system Aceso, respectively.
Seesaw: High-throughput LLM Inference via Model Re-sharding
Mar 09, 2025To improve the efficiency of distributed large language model (LLM) inference, various parallelization strategies, such as tensor and pipeline parallelism, have been proposed. However, the distinct computational characteristics inherent in the two stages of LLM inference-prefilling and decoding-render a single static parallelization strategy insufficient for the effective optimization of both stages. In this work, we present Seesaw, an LLM inference engine optimized for throughput-oriented tasks. The key idea behind Seesaw is dynamic model re-sharding, a technique that facilitates the dynamic reconfiguration of parallelization strategies across stages, thereby maximizing throughput at both phases. To mitigate re-sharding overhead and optimize computational efficiency, we employ tiered KV cache buffering and transition-minimizing scheduling. These approaches work synergistically to reduce the overhead caused by frequent stage transitions while ensuring maximum batching efficiency. Our evaluation demonstrates that Seesaw achieves a throughput increase of up to 1.78x (1.36x on average) compared to vLLM, the most widely used state-of-the-art LLM inference engine.
PAPI: Exploiting Dynamic Parallelism in Large Language Model Decoding with a Processing-In-Memory-Enabled Computing System
Feb 21, 2025Large language models (LLMs) are widely used for natural language understanding and text generation. An LLM model relies on a time-consuming step called LLM decoding to generate output tokens. Several prior works focus on improving the performance of LLM decoding using parallelism techniques, such as batching and speculative decoding. State-of-the-art LLM decoding has both compute-bound and memory-bound kernels. Some prior works statically identify and map these different kernels to a heterogeneous architecture consisting of both processing-in-memory (PIM) units and computation-centric accelerators. We observe that characteristics of LLM decoding kernels (e.g., whether or not a kernel is memory-bound) can change dynamically due to parameter changes to meet user and/or system demands, making (1) static kernel mapping to PIM units and computation-centric accelerators suboptimal, and (2) one-size-fits-all approach of designing PIM units inefficient due to a large degree of heterogeneity even in memory-bound kernels. In this paper, we aim to accelerate LLM decoding while considering the dynamically changing characteristics of the kernels involved. We propose PAPI (PArallel Decoding with PIM), a PIM-enabled heterogeneous architecture that exploits dynamic scheduling of compute-bound or memory-bound kernels to suitable hardware units. PAPI has two key mechanisms: (1) online kernel characterization to dynamically schedule kernels to the most suitable hardware units at runtime and (2) a PIM-enabled heterogeneous computing system that harmoniously orchestrates both computation-centric processing units and hybrid PIM units with different computing capabilities. Our experimental results on three broadly-used LLMs show that PAPI achieves 1.8$\times$ and 11.1$\times$ speedups over a state-of-the-art heterogeneous LLM accelerator and a state-of-the-art PIM-only LLM accelerator, respectively.
Low-Bitwidth Floating Point Quantization for Efficient High-Quality Diffusion Models
Aug 13, 2024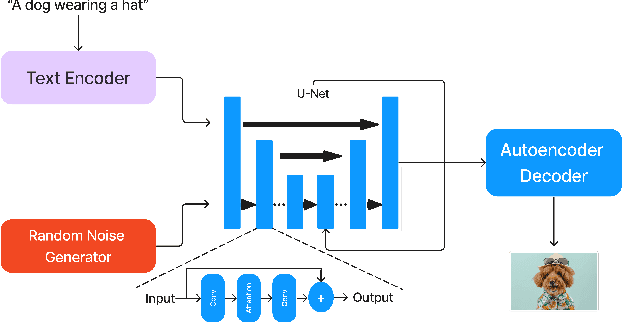
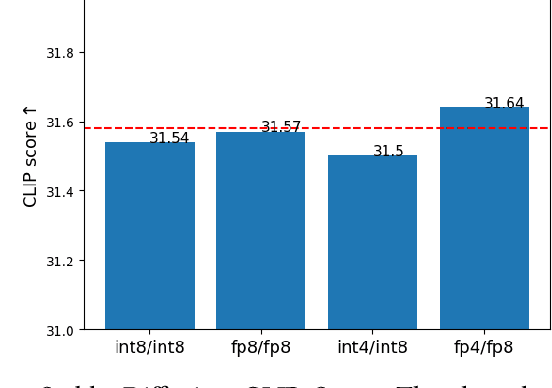
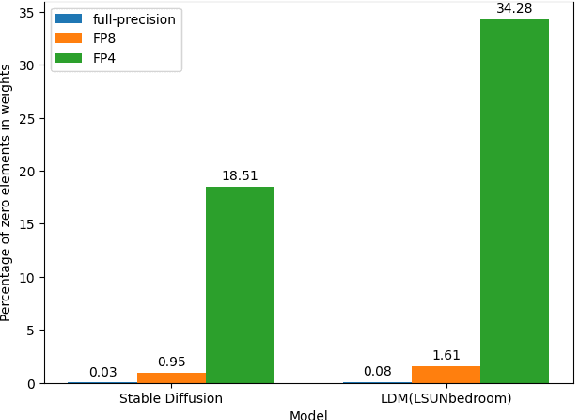

Diffusion models are emerging models that generate images by iteratively denoising random Gaussian noise using deep neural networks. These models typically exhibit high computational and memory demands, necessitating effective post-training quantization for high-performance inference. Recent works propose low-bitwidth (e.g., 8-bit or 4-bit) quantization for diffusion models, however 4-bit integer quantization typically results in low-quality images. We observe that on several widely used hardware platforms, there is little or no difference in compute capability between floating-point and integer arithmetic operations of the same bitwidth (e.g., 8-bit or 4-bit). Therefore, we propose an effective floating-point quantization method for diffusion models that provides better image quality compared to integer quantization methods. We employ a floating-point quantization method that was effective for other processing tasks, specifically computer vision and natural language tasks, and tailor it for diffusion models by integrating weight rounding learning during the mapping of the full-precision values to the quantized values in the quantization process. We comprehensively study integer and floating-point quantization methods in state-of-the-art diffusion models. Our floating-point quantization method not only generates higher-quality images than that of integer quantization methods, but also shows no noticeable degradation compared to full-precision models (32-bit floating-point), when both weights and activations are quantized to 8-bit floating-point values, while has minimal degradation with 4-bit weights and 8-bit activations.
Proteus: Preserving Model Confidentiality during Graph Optimizations
Apr 18, 2024
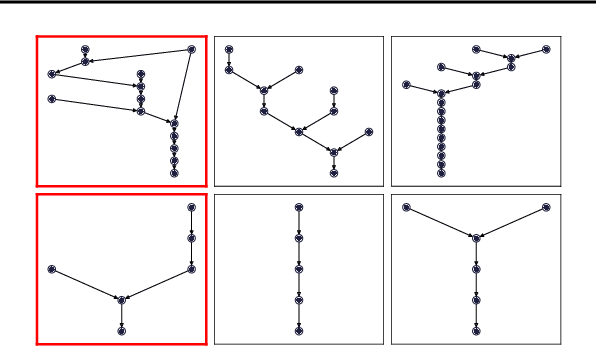
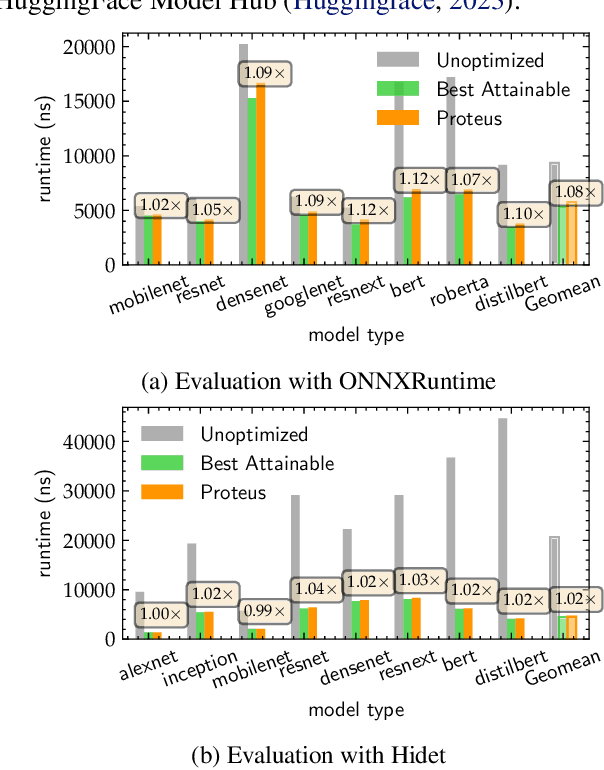
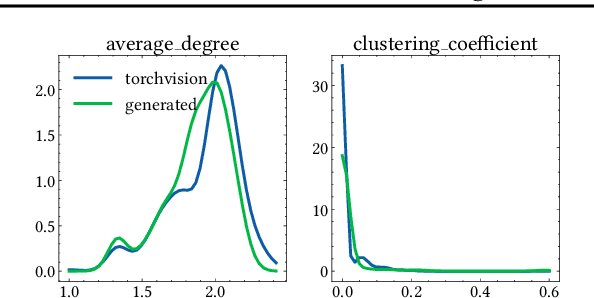
Deep learning (DL) models have revolutionized numerous domains, yet optimizing them for computational efficiency remains a challenging endeavor. Development of new DL models typically involves two parties: the model developers and performance optimizers. The collaboration between the parties often necessitates the model developers exposing the model architecture and computational graph to the optimizers. However, this exposure is undesirable since the model architecture is an important intellectual property, and its innovations require significant investments and expertise. During the exchange, the model is also vulnerable to adversarial attacks via model stealing. This paper presents Proteus, a novel mechanism that enables model optimization by an independent party while preserving the confidentiality of the model architecture. Proteus obfuscates the protected model by partitioning its computational graph into subgraphs and concealing each subgraph within a large pool of generated realistic subgraphs that cannot be easily distinguished from the original. We evaluate Proteus on a range of DNNs, demonstrating its efficacy in preserving confidentiality without compromising performance optimization opportunities. Proteus effectively hides the model as one alternative among up to $10^{32}$ possible model architectures, and is resilient against attacks with a learning-based adversary. We also demonstrate that heuristic based and manual approaches are ineffective in identifying the protected model. To our knowledge, Proteus is the first work that tackles the challenge of model confidentiality during performance optimization. Proteus will be open-sourced for direct use and experimentation, with easy integration with compilers such as ONNXRuntime.
Accelerating Graph Neural Networks on Real Processing-In-Memory Systems
Feb 26, 2024



Graph Neural Networks (GNNs) are emerging ML models to analyze graph-structure data. Graph Neural Network (GNN) execution involves both compute-intensive and memory-intensive kernels, the latter dominates the total time, being significantly bottlenecked by data movement between memory and processors. Processing-In-Memory (PIM) systems can alleviate this data movement bottleneck by placing simple processors near or inside to memory arrays. In this work, we introduce PyGim, an efficient ML framework that accelerates GNNs on real PIM systems. We propose intelligent parallelization techniques for memory-intensive kernels of GNNs tailored for real PIM systems, and develop handy Python API for them. We provide hybrid GNN execution, in which the compute-intensive and memory-intensive kernels are executed in processor-centric and memory-centric computing systems, respectively, to match their algorithmic nature. We extensively evaluate PyGim on a real-world PIM system with 1992 PIM cores using emerging GNN models, and demonstrate that it outperforms its state-of-the-art CPU counterpart on Intel Xeon by on average 3.04x, and achieves higher resource utilization than CPU and GPU systems. Our work provides useful recommendations for software, system and hardware designers. PyGim will be open-sourced to enable the widespread use of PIM systems in GNNs.
The Synergy of Speculative Decoding and Batching in Serving Large Language Models
Oct 28, 2023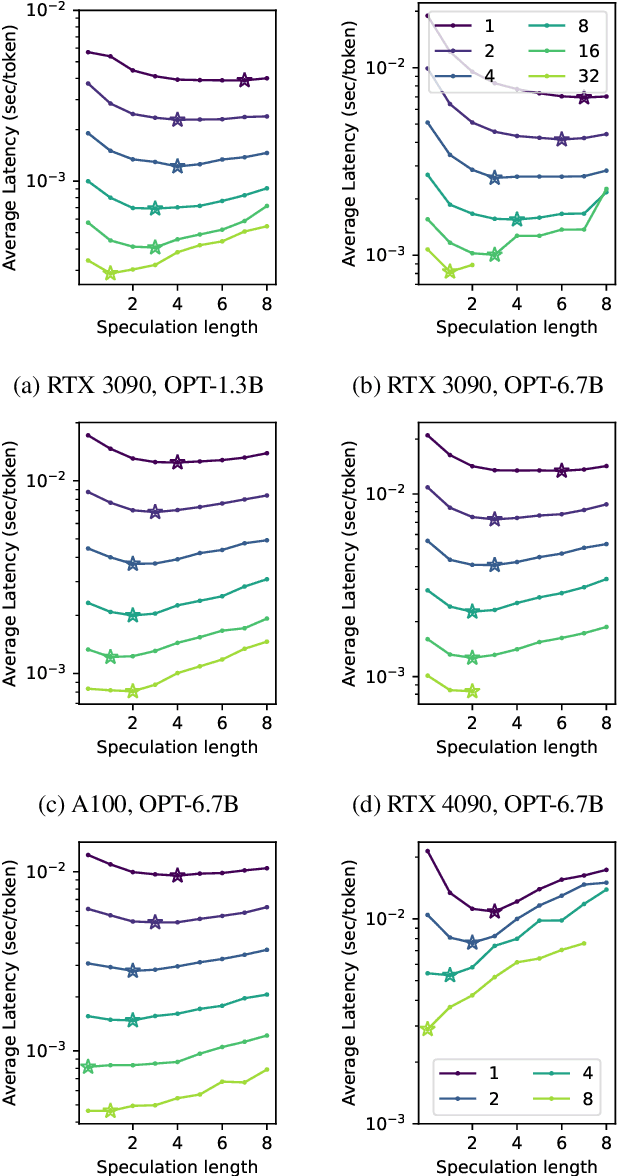
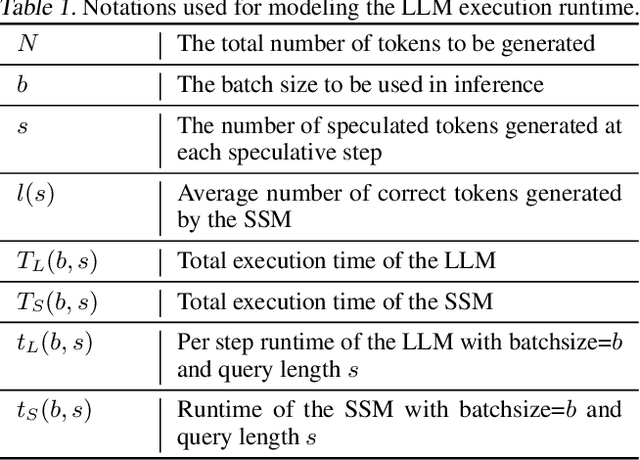
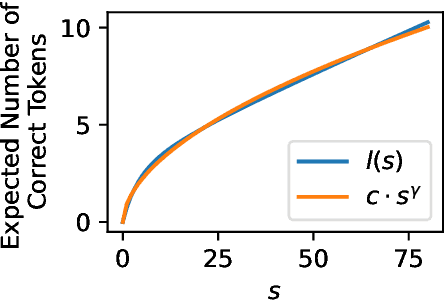
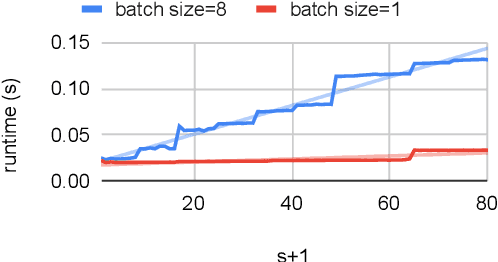
Large Language Models (LLMs) like GPT are state-of-the-art text generation models that provide significant assistance in daily routines. However, LLM execution is inherently sequential, since they only produce one token at a time, thus incurring low hardware utilization on modern GPUs. Batching and speculative decoding are two techniques to improve GPU hardware utilization in LLM inference. To study their synergy, we implement a prototype implementation and perform an extensive characterization analysis on various LLM models and GPU architectures. We observe that the optimal speculation length depends on the batch size used. We analyze the key observation and build a quantitative model to explain it. Based on our analysis, we propose a new adaptive speculative decoding strategy that chooses the optimal speculation length for different batch sizes. Our evaluations show that our proposed method can achieve equal or better performance than the state-of-the-art speculation decoding schemes with fixed speculation length.