 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAPI: Exploiting Dynamic Parallelism in Large Language Model Decoding with a Processing-In-Memory-Enabled Computing System
Feb 21, 2025Large language models (LLMs) are widely used for natural language understanding and text generation. An LLM model relies on a time-consuming step called LLM decoding to generate output tokens. Several prior works focus on improving the performance of LLM decoding using parallelism techniques, such as batching and speculative decoding. State-of-the-art LLM decoding has both compute-bound and memory-bound kernels. Some prior works statically identify and map these different kernels to a heterogeneous architecture consisting of both processing-in-memory (PIM) units and computation-centric accelerators. We observe that characteristics of LLM decoding kernels (e.g., whether or not a kernel is memory-bound) can change dynamically due to parameter changes to meet user and/or system demands, making (1) static kernel mapping to PIM units and computation-centric accelerators suboptimal, and (2) one-size-fits-all approach of designing PIM units inefficient due to a large degree of heterogeneity even in memory-bound kernels. In this paper, we aim to accelerate LLM decoding while considering the dynamically changing characteristics of the kernels involved. We propose PAPI (PArallel Decoding with PIM), a PIM-enabled heterogeneous architecture that exploits dynamic scheduling of compute-bound or memory-bound kernels to suitable hardware units. PAPI has two key mechanisms: (1) online kernel characterization to dynamically schedule kernels to the most suitable hardware units at runtime and (2) a PIM-enabled heterogeneous computing system that harmoniously orchestrates both computation-centric processing units and hybrid PIM units with different computing capabilities. Our experimental results on three broadly-used LLMs show that PAPI achieves 1.8$\times$ and 11.1$\times$ speedups over a state-of-the-art heterogeneous LLM accelerator and a state-of-the-art PIM-only LLM accelerator, respectively.
NEON: Enabling Efficient Support for Nonlinear Operations in Resistive RAM-based Neural Network Accelerators
Nov 10, 2022Resistive Random-Access Memory (RRAM) is well-suited to accelerate neural network (NN) workloads as RRAM-based Processing-in-Memory (PIM) architectures natively support highly-parallel multiply-accumulate (MAC) operations that form the backbone of most NN workloads. Unfortunately, NN workloads such as transformers require support for non-MAC operations (e.g., softmax) that RRAM cannot provide natively. Consequently, state-of-the-art works either integrate additional digital logic circuits to support the non-MAC operations or offload the non-MAC operations to CPU/GPU, resulting in significant performance and energy efficiency overheads due to data movement. In this work, we propose NEON, a novel compiler optimization to enable the end-to-end execution of the NN workload in RRAM. The key idea of NEON is to transform each non-MAC operation into a lightweight yet highly-accurate neural network. Utilizing neural networks to approximate the non-MAC operations provides two advantages: 1) We can exploit the key strength of RRAM, i.e., highly-parallel MAC operation, to flexibly and efficiently execute non-MAC operations in memory. 2) We can simplify RRAM's microarchitecture by eliminating the additional digital logic circuits while reducing the data movement overheads. Acceleration of the non-MAC operations in memory enables NEON to achieve a 2.28x speedup compared to an idealized digital logic-based RRAM. We analyze the trade-offs associated with the transformation and demonstrate feasible use cases for NEON across different substrates.
Tackling Variabilities in Autonomous Driving
Apr 21, 2021
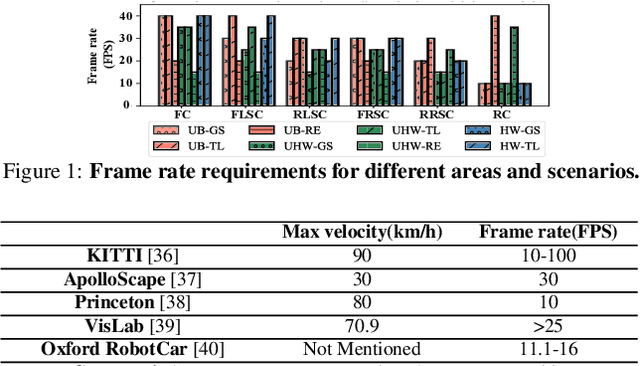


The state-of-the-art driving automation system demands extreme computational resources to meet rigorous accuracy and latency requirements. Though emerging driving automation computing platforms are based on ASIC to provide better performance and power guarantee, building such an accelerator-based computing platform for driving automation still present challenges. First, the workloads mix and performance requirements exposed to driving automation system present significant variability. Second, with more cameras/sensors integrated in a future fully autonomous driving vehicle, a heterogeneous multi-accelerator architecture substrate is needed that requires a design space exploration for a new form of parallelism. In this work, we aim to extensively explore the above system design challenges and these challenges motivate us to propose a comprehensive framework that synergistically handles the heterogeneous hardware accelerator design principles, system design criteria, and task scheduling mechanism. Specifically, we propose a novel heterogeneous multi-core AI accelerator (HMAI) to provide the hardware substrate for the driving automation tasks with variability. We also define system design criteria to better utilize hardware resources and achieve increased throughput while satisfying the performance and energy restrictions. Finally, we propose a deep reinforcement learning (RL)-based task scheduling mechanism FlexAI, to resolve task mapping issue. Experimental results show that with FlexAI scheduling, basically 100% tasks in each driving route can be processed by HMAI within their required period to ensure safety, and FlexAI can also maximally reduce the breaking distance up to 96% as compared to typical heuristics and guided random-search-based algorithms.