 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMigGPT: Harnessing Large Language Models for Automated Migration of Out-of-Tree Linux Kernel Patches Across Versions
Apr 13, 2025Out-of-tree kernel patches are essential for adapting the Linux kernel to new hardware or enabling specific functionalities. Maintaining and updating these patches across different kernel versions demands significant effort from experienced engineers. Large language models (LLMs) have shown remarkable progress across various domains, suggesting their potential for automating out-of-tree kernel patch migration. However, our findings reveal that LLMs, while promising, struggle with incomplete code context understanding and inaccurate migration point identification. In this work, we propose MigGPT, a framework that employs a novel code fingerprint structure to retain code snippet information and incorporates three meticulously designed modules to improve the migration accuracy and efficiency of out-of-tree kernel patches. Furthermore, we establish a robust benchmark using real-world out-of-tree kernel patch projects to evaluate LLM capabilities. Evaluations show that MigGPT significantly outperforms the direct application of vanilla LLMs, achieving an average completion rate of 72.59% (50.74% improvement) for migration tasks.
Characterizing and Understanding HGNN Training on GPUs
Jul 16, 2024Owing to their remarkable representation capabilities for heterogeneous graph data, Heterogeneous Graph Neural Networks (HGNNs) have been widely adopted in many critical real-world domains such as recommendation systems and medical analysis. Prior to their practical application, identifying the optimal HGNN model parameters tailored to specific tasks through extensive training is a time-consuming and costly process. To enhance the efficiency of HGNN training, it is essential to characterize and analyze the execution semantics and patterns within the training process to identify performance bottlenecks. In this study, we conduct an in-depth quantification and analysis of two mainstream HGNN training scenarios, including single-GPU and multi-GPU distributed training. Based on the characterization results, we disclose the performance bottlenecks and their underlying causes in different HGNN training scenarios and provide optimization guidelines from both software and hardware perspectives.
Tackling Variabilities in Autonomous Driving
Apr 21, 2021
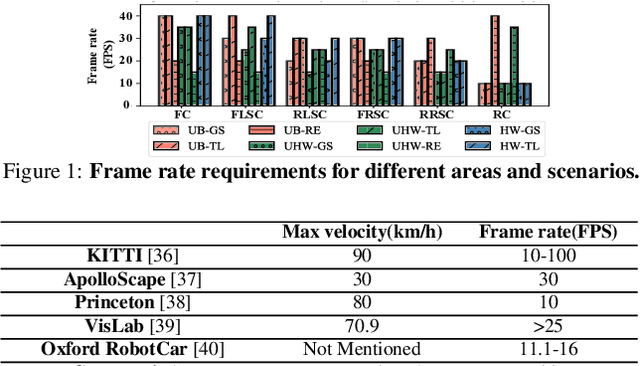


The state-of-the-art driving automation system demands extreme computational resources to meet rigorous accuracy and latency requirements. Though emerging driving automation computing platforms are based on ASIC to provide better performance and power guarantee, building such an accelerator-based computing platform for driving automation still present challenges. First, the workloads mix and performance requirements exposed to driving automation system present significant variability. Second, with more cameras/sensors integrated in a future fully autonomous driving vehicle, a heterogeneous multi-accelerator architecture substrate is needed that requires a design space exploration for a new form of parallelism. In this work, we aim to extensively explore the above system design challenges and these challenges motivate us to propose a comprehensive framework that synergistically handles the heterogeneous hardware accelerator design principles, system design criteria, and task scheduling mechanism. Specifically, we propose a novel heterogeneous multi-core AI accelerator (HMAI) to provide the hardware substrate for the driving automation tasks with variability. We also define system design criteria to better utilize hardware resources and achieve increased throughput while satisfying the performance and energy restrictions. Finally, we propose a deep reinforcement learning (RL)-based task scheduling mechanism FlexAI, to resolve task mapping issue. Experimental results show that with FlexAI scheduling, basically 100% tasks in each driving route can be processed by HMAI within their required period to ensure safety, and FlexAI can also maximally reduce the breaking distance up to 96% as compared to typical heuristics and guided random-search-based algorithms.