 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
Intention Chain-of-Thought Prompting with Dynamic Routing for Code Generation
Dec 16, 2025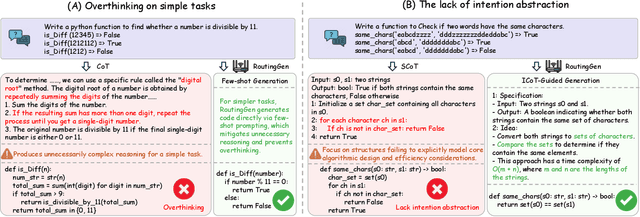
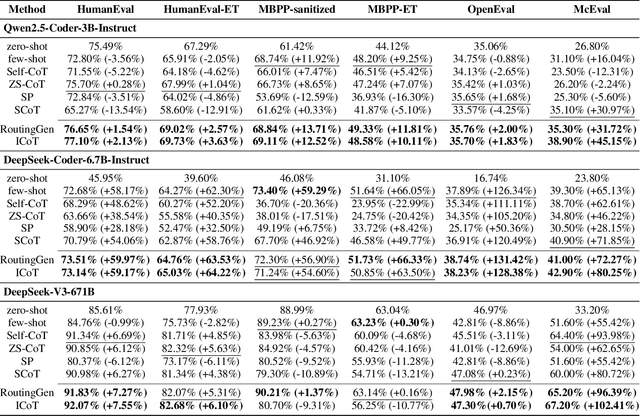
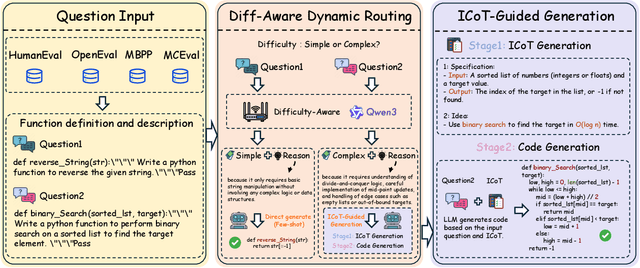
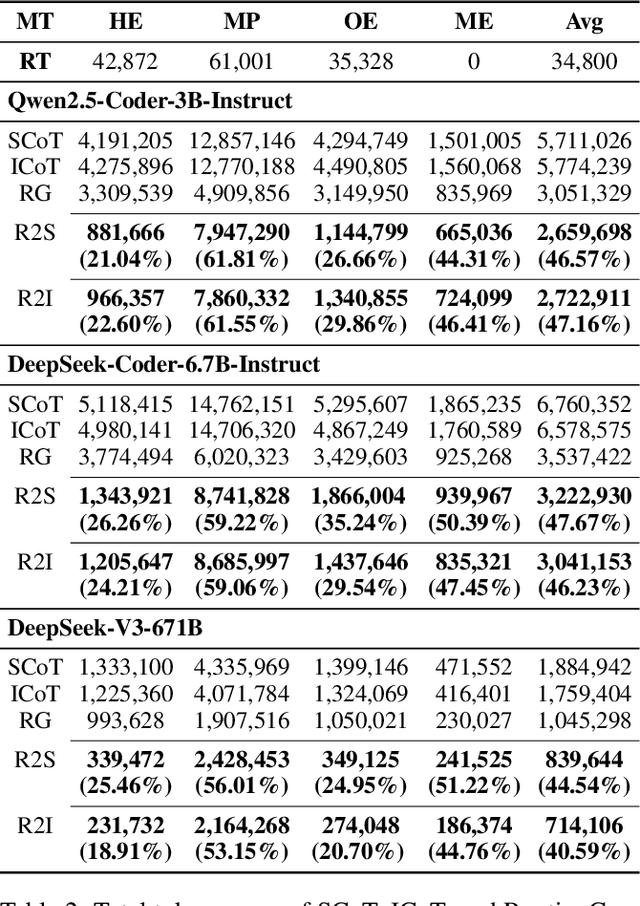
Large language models (LLMs) exhibit strong generative capabilities and have shown great potential in code generation. Existing chain-of-thought (CoT) prompting methods enhance model reasoning by eliciting intermediate steps, but suffer from two major limitations: First, their uniform application tends to induce overthinking on simple tasks. Second, they lack intention abstraction in code generation, such as explicitly modeling core algorithmic design and efficiency, leading models to focus on surface-level structures while neglecting the global problem objective. Inspired by the cognitive economy principle of engaging structured reasoning only when necessary to conserve cognitive resources, we propose RoutingGen, a novel difficulty-aware routing framework that dynamically adapts prompting strategies for code generation. For simple tasks, it adopts few-shot prompting; for more complex ones, it invokes a structured reasoning strategy, termed Intention Chain-of-Thought (ICoT), which we introduce to guide the model in capturing task intention, such as the core algorithmic logic and its time complexity. Experiments across three models and six standard code generation benchmarks show that RoutingGen achieves state-of-the-art performance in most settings, while reducing total token usage by 46.37% on average across settings. Furthermore, ICoT outperforms six existing prompting baselines on challenging benchmarks.
Co-EPG: A Framework for Co-Evolution of Planning and Grounding in Autonomous GUI Agents
Nov 13, 2025Graphical User Interface (GUI) task automation constitutes a critical frontier in artificial intelligence research. While effective GUI agents synergistically integrate planning and grounding capabilities, current methodologies exhibit two fundamental limitations: (1) insufficient exploitation of cross-model synergies, and (2) over-reliance on synthetic data generation without sufficient utilization. To address these challenges, we propose Co-EPG, a self-iterative training framework for Co-Evolution of Planning and Grounding. Co-EPG establishes an iterative positive feedback loop: through this loop, the planning model explores superior strategies under grounding-based reward guidance via Group Relative Policy Optimization (GRPO), generating diverse data to optimize the grounding model. Concurrently, the optimized Grounding model provides more effective rewards for subsequent GRPO training of the planning model, fostering continuous improvement. Co-EPG thus enables iterative enhancement of agent capabilities through self-play optimization and training data distillation. On the Multimodal-Mind2Web and AndroidControl benchmarks, our framework outperforms existing state-of-the-art methods after just three iterations without requiring external data. The agent consistently improves with each iteration, demonstrating robust self-enhancement capabilities. This work establishes a novel training paradigm for GUI agents, shifting from isolated optimization to an integrated, self-driven co-evolution approach.
Importance-Aware Data Selection for Efficient LLM Instruction Tuning
Nov 10, 2025Instruction tuning plays a critical role in enhancing the performance and efficiency of Large Language Models (LLMs). Its success depends not only on the quality of the instruction data but also on the inherent capabilities of the LLM itself. Some studies suggest that even a small amount of high-quality data can achieve instruction fine-tuning results that are on par with, or even exceed, those from using a full-scale dataset. However, rather than focusing solely on calculating data quality scores to evaluate instruction data, there is a growing need to select high-quality data that maximally enhances the performance of instruction tuning for a given LLM. In this paper, we propose the Model Instruction Weakness Value (MIWV) as a novel metric to quantify the importance of instruction data in enhancing model's capabilities. The MIWV metric is derived from the discrepancies in the model's responses when using In-Context Learning (ICL), helping identify the most beneficial data for enhancing instruction tuning performance. Our experimental results demonstrate that selecting only the top 1\% of data based on MIWV can outperform training on the full dataset. Furthermore, this approach extends beyond existing research that focuses on data quality scoring for data selection, offering strong empirical evidence supporting the effectiveness of our proposed method.
Security Tensors as a Cross-Modal Bridge: Extending Text-Aligned Safety to Vision in LVLM
Jul 28, 2025Large visual-language models (LVLMs) integrate aligned large language models (LLMs) with visual modules to process multimodal inputs. However, the safety mechanisms developed for text-based LLMs do not naturally extend to visual modalities, leaving LVLMs vulnerable to harmful image inputs. To address this cross-modal safety gap, we introduce security tensors - trainable input vectors applied during inference through either the textual or visual modality. These tensors transfer textual safety alignment to visual processing without modifying the model's parameters. They are optimized using a curated dataset containing (i) malicious image-text pairs requiring rejection, (ii) contrastive benign pairs with text structurally similar to malicious queries, with the purpose of being contrastive examples to guide visual reliance, and (iii) general benign samples preserving model functionality. Experimental results demonstrate that both textual and visual security tensors significantly enhance LVLMs' ability to reject diverse harmful visual inputs while maintaining near-identical performance on benign tasks. Further internal analysis towards hidden-layer representations reveals that security tensors successfully activate the language module's textual "safety layers" in visual inputs, thereby effectively extending text-based safety to the visual modality.
Efficiently Building a Domain-Specific Large Language Model from Scratch: A Case Study of a Classical Chinese Large Language Model
May 17, 2025General-purpose large language models demonstrate notable capabilities in language comprehension and generation, achieving results that are comparable to, or even surpass, human performance in many language information processing tasks. Nevertheless, when general models are applied to some specific domains, e.g., Classical Chinese texts, their effectiveness is often unsatisfactory, and fine-tuning open-source foundational models similarly struggles to adequately incorporate domain-specific knowledge. To address this challenge, this study developed a large language model, AI Taiyan, specifically designed for understanding and generating Classical Chinese. Experiments show that with a reasonable model design, data processing, foundational training, and fine-tuning, satisfactory results can be achieved with only 1.8 billion parameters. In key tasks related to Classical Chinese information processing such as punctuation, identification of allusions, explanation of word meanings, and translation between ancient and modern Chinese, this model exhibits a clear advantage over both general-purpose large models and domain-specific traditional models, achieving levels close to or surpassing human baselines. This research provides a reference for the efficient construction of specialized domain-specific large language models. Furthermore, the paper discusses the application of this model in fields such as the collation of ancient texts, dictionary editing, and language research, combined with case studies.
Decision Making in Urban Traffic: A Game Theoretic Approach for Autonomous Vehicles Adhering to Traffic Rules
May 15, 2025One of the primary challenges in urban autonomous vehicle decision-making and planning lies in effectively managing intricate interactions with diverse traffic participants characterized by unpredictable movement patterns. Additionally, interpreting and adhering to traffic regulations within rapidly evolving traffic scenarios pose significant hurdles. This paper proposed a rule-based autonomous vehicle decision-making and planning framework which extracts right-of-way from traffic rules to generate behavioural parameters, integrating them to effectively adhere to and navigate through traffic regulations. The framework considers the strong interaction between traffic participants mathematically by formulating the decision-making and planning problem into a differential game. By finding the Nash equilibrium of the problem, the autonomous vehicle is able to find optimal decisions. The proposed framework was tested under simulation as well as full-size vehicle platform, the results show that the ego vehicle is able to safely interact with surrounding traffic participants while adhering to traffic rules.
Semantics Prompting Data-Free Quantization for Low-Bit Vision Transformers
Dec 21, 2024Data-free quantization (DFQ), which facilitates model quantization without real data to address increasing concerns about data security, has garnered significant attention within the model compression community. Recently, the unique architecture of vision transformers (ViTs) has driven the development of specialized DFQ techniques. However, we observe that the synthetic images from existing methods suffer from the deficient semantics issue compared to real images, thereby compromising performance. Motivated by this, we propose SPDFQ, a Semantics Prompting Data-Free Quantization method for ViTs. First, SPDFQ incorporates Attention Priors Alignment (APA), which uses randomly generated attention priors to enhance the semantics of synthetic images. Second, SPDFQ introduces Multi-Semantic Reinforcement (MSR), which utilizes localized patch optimization to prompt efficient parameterization and diverse semantics in synthetic images. Finally, SPDFQ employs Softlabel Learning (SL), where soft learning targets are adapted to encourage more complex semantics and accommodate images augmented by MSR. Experimental results demonstrate that SPDFQ significantly outperforms existing methods. For instance, SPDFQ achieves a 15.52% increase in top-1 accuracy on ImageNet for W4A4 ViT-B
On Shaping Gain of Multidimensional Constellation in Linear and Nonlinear Optical Fiber Channel
Dec 19, 2024



Utilizing the multi-dimensional (MD) space for constellation shaping has been proven to be an effective approach for achieving shaping gains. Despite there exists a variety of MD modulation formats tailored for specific optical transmission scenarios, there remains a notable absence of a dependable comparison method for efficiently and promptly re-evaluating their performance in arbitrary transmission systems. In this paper, we introduce an analytical nonlinear interference (NLI) power model-based shaping gain estimation method to enable a fast performance evaluation of various MD modulation formats in coherent dual-polarization (DP) optical transmission system. In order to extend the applicability of this method to a broader set of modulation formats, we extend the established NLI model to take the 4D joint distribution into account and thus able to analyze the complex interactions of non-iid signaling in DP systems. With the help of the NLI model, we conduct a comprehensive analysis of the state-of-the-art modulation formats and investigate their actual shaping gains in two types of optical fiber communication scenarios (multi-span and single-span). The numerical simulation shows that for arbitrary modulation formats, the NLI power and relative shaping gains in terms of signal-to-noise ratio can be more accurately estimated by capturing the statistics of MD symbols. Furthermore, the proposed method further validates the effectiveness of the reported NLI-tolerant modulation format in the literature, which reveals that the linear shaping gains and modulation-dependent NLI should be jointly considered for nonlinearity mitigation.
Chanel-Orderer: A Channel-Ordering Predictor for Tri-Channel Natural Images
Nov 20, 2024



This paper shows a proof-of-concept that, given a typical 3-channel images but in a randomly permuted channel order, a model (termed as Chanel-Orderer) with ad-hoc inductive biases in terms of both architecture and loss functions can accurately predict the channel ordering and knows how to make it right. Specifically, Chanel-Orderer learns to score each of the three channels with the priors of object semantics and uses the resulting scores to predict the channel ordering. This brings up benefits into a typical scenario where an \texttt{RGB} image is often mis-displayed in the \texttt{BGR} format and needs to be corrected into the right order. Furthermore, as a byproduct, the resulting model Chanel-Orderer is able to tell whether a given image is a near-gray-scale image (near-monochromatic) or not (polychromatic). Our research suggests that Chanel-Orderer mimics human visual coloring of our physical natural world.