 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Reconstruction of LiDAR Point Clouds under Jamming Attacks via Full-Waveform Representation and Simultaneous Laser Sensing
Apr 01, 2026LiDAR sensors are critical for autonomous driving perception, yet remain vulnerable to spoofing attacks. Jamming attacks inject high-frequency laser pulses that completely blind LiDAR sensors by overwhelming authentic returns with malicious signals. We discover that while point clouds become randomized, the underlying full-waveform data retains distinguishable signatures between attack and legitimate signals. In this work, we propose PULSAR-Net, capable of reconstructing authentic point clouds under jamming attacks by leveraging previously underutilized intermediate full-waveform representations and simultaneous laser sensing in modern LiDAR systems. PULSAR-Net adopts a novel U-Net architecture with axial spatial attention mechanisms specifically designed to identify attack-induced signals from authentic object returns in the full-waveform representation. To address the lack of full-waveform representations in existing LiDAR datasets under jamming attacks, we introduce a physics-aware dataset generation pipeline that synthesizes realistic full-waveform representations under jamming attacks. Despite being trained exclusively on synthetic data, PULSAR-Net achieves reconstruction rates of 92% and 73% for vehicles obscured by jamming attacks in real-world static and driving scenarios, respectively.
KVSlimmer: Theoretical Insights and Practical Optimizations for Asymmetric KV Merging
Mar 01, 2026The growing computational and memory demands of the Key-Value (KV) cache significantly limit the ability of Large Language Models (LLMs). While KV merging has emerged as a promising solution, existing methods that rely on empirical observations of KV asymmetry and gradient-based Hessian approximations lack a theoretical foundation and incur suboptimal compression and inference overhead. To bridge these gaps, we establish a theoretical framework that characterizes this asymmetry through the spectral energy distribution of projection weights, demonstrating that concentrated spectra in Query/Key weights induce feature homogeneity, whereas dispersed spectra in Value weights preserve heterogeneity. Then, we introduce KVSlimmer, an efficient algorithm that captures exact Hessian information through a mathematically exact formulation, and derives a closed-form solution utilizing only forward-pass variables, resulting in a gradient-free approach that is both memory- and time-efficient. Extensive experiments across various models and benchmarks demonstrate that KVSlimmer consistently outperforms SOTA methods. For instance, on Llama3.1-8B-Instruct, it improves the LongBench average score by 0.92 while reducing memory costs and latency by 29% and 28%, respectively.
D4C: Data-free Quantization for Contrastive Language-Image Pre-training Models
Nov 19, 2025Data-Free Quantization (DFQ) offers a practical solution for model compression without requiring access to real data, making it particularly attractive in privacy-sensitive scenarios. While DFQ has shown promise for unimodal models, its extension to Vision-Language Models such as Contrastive Language-Image Pre-training (CLIP) models remains underexplored. In this work, we reveal that directly applying existing DFQ techniques to CLIP results in substantial performance degradation due to two key limitations: insufficient semantic content and low intra-image diversity in synthesized samples. To tackle these challenges, we propose D4C, the first DFQ framework tailored for CLIP. D4C synthesizes semantically rich and structurally diverse pseudo images through three key components: (1) Prompt-Guided Semantic Injection aligns generated images with real-world semantics using text prompts; (2) Structural Contrastive Generation reproduces compositional structures of natural images by leveraging foreground-background contrastive synthesis; and (3) Perturbation-Aware Enhancement applies controlled perturbations to improve sample diversity and robustness. These components jointly empower D4C to synthesize images that are both semantically informative and structurally diverse, effectively bridging the performance gap of DFQ on CLIP. Extensive experiments validate the effectiveness of D4C, showing significant performance improvements on various bit-widths and models. For example, under the W4A8 setting with CLIP ResNet-50 and ViT-B/32, D4C achieves Top-1 accuracy improvement of 12.4% and 18.9% on CIFAR-10, 6.8% and 19.7% on CIFAR-100, and 1.4% and 5.7% on ImageNet-1K in zero-shot classification, respectively.
Test-Time Iterative Error Correction for Efficient Diffusion Models
Nov 09, 2025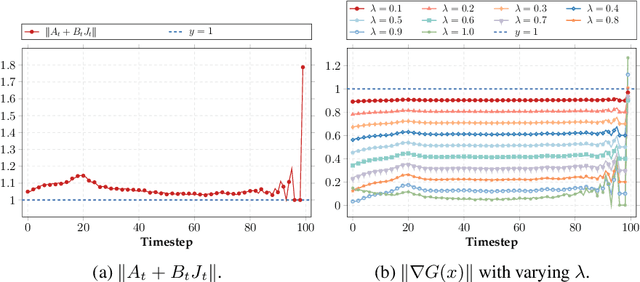

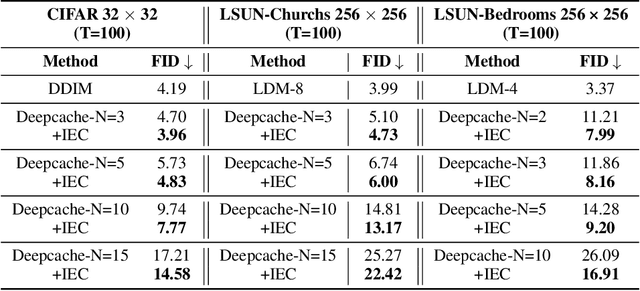
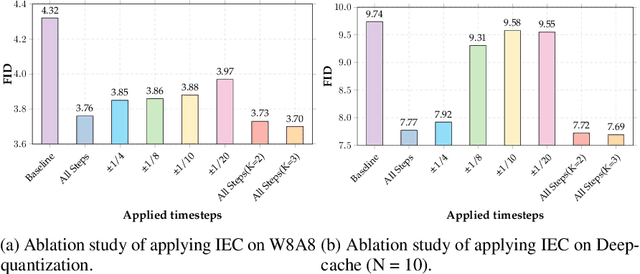
With the growing demand for high-quality image generation on resource-constrained devices, efficient diffusion models have received increasing attention. However, such models suffer from approximation errors introduced by efficiency techniques, which significantly degrade generation quality. Once deployed, these errors are difficult to correct, as modifying the model is typically infeasible in deployment environments. Through an analysis of error propagation across diffusion timesteps, we reveal that these approximation errors can accumulate exponentially, severely impairing output quality. Motivated by this insight, we propose Iterative Error Correction (IEC), a novel test-time method that mitigates inference-time errors by iteratively refining the model's output. IEC is theoretically proven to reduce error propagation from exponential to linear growth, without requiring any retraining or architectural changes. IEC can seamlessly integrate into the inference process of existing diffusion models, enabling a flexible trade-off between performance and efficiency. Extensive experiments show that IEC consistently improves generation quality across various datasets, efficiency techniques, and model architectures, establishing it as a practical and generalizable solution for test-time enhancement of efficient diffusion models.
Semantics Prompting Data-Free Quantization for Low-Bit Vision Transformers
Dec 21, 2024Data-free quantization (DFQ), which facilitates model quantization without real data to address increasing concerns about data security, has garnered significant attention within the model compression community. Recently, the unique architecture of vision transformers (ViTs) has driven the development of specialized DFQ techniques. However, we observe that the synthetic images from existing methods suffer from the deficient semantics issue compared to real images, thereby compromising performance. Motivated by this, we propose SPDFQ, a Semantics Prompting Data-Free Quantization method for ViTs. First, SPDFQ incorporates Attention Priors Alignment (APA), which uses randomly generated attention priors to enhance the semantics of synthetic images. Second, SPDFQ introduces Multi-Semantic Reinforcement (MSR), which utilizes localized patch optimization to prompt efficient parameterization and diverse semantics in synthetic images. Finally, SPDFQ employs Softlabel Learning (SL), where soft learning targets are adapted to encourage more complex semantics and accommodate images augmented by MSR. Experimental results demonstrate that SPDFQ significantly outperforms existing methods. For instance, SPDFQ achieves a 15.52% increase in top-1 accuracy on ImageNet for W4A4 ViT-B
ERQ: Error Reduction for Post-Training Quantization of Vision Transformers
Jul 09, 2024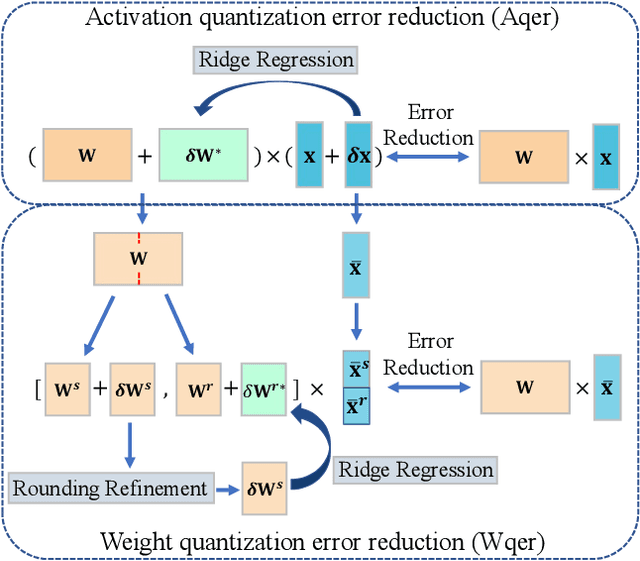

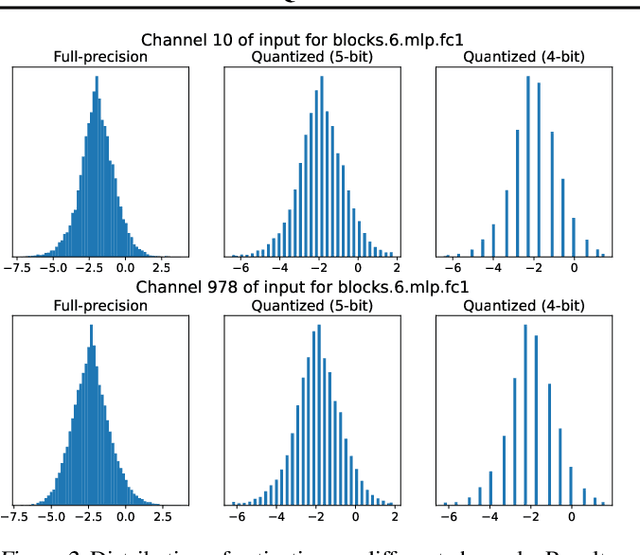
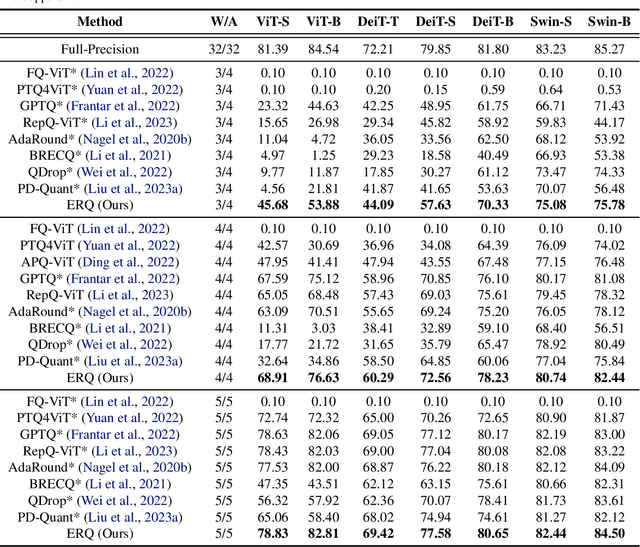
Post-training quantization (PTQ) for vision transformers (ViTs) has garnered significant attention due to its efficiency in compressing models. However, existing methods typically overlook the intricate interdependence between quantized weight and activation, leading to considerable quantization error. In this paper, we propose ERQ, a two-step PTQ approach meticulously crafted to sequentially reduce the quantization error arising from activation and weight quantization. ERQ first introduces Activation quantization error reduction (Aqer) that strategically formulates the minimization of activation quantization error as a Ridge Regression problem, tackling it by updating weights with full-precision. Subsequently, ERQ introduces Weight quantization error reduction (Wqer) that adopts an iterative approach to mitigate the quantization error induced by weight quantization. In each iteration, an empirically derived, efficient proxy is employed to refine the rounding directions of quantized weights, coupled with a Ridge Regression solver to curtail weight quantization error. Experimental results attest to the effectiveness of our approach. Notably, ERQ surpasses the state-of-the-art GPTQ by 22.36% in accuracy for W3A4 ViT-S.
UIO-LLMs: Unbiased Incremental Optimization for Long-Context LLMs
Jun 26, 2024Managing long texts is challenging for large language models (LLMs) due to limited context window sizes. This study introduces UIO-LLMs, an unbiased incremental optimization approach for memory-enhanced transformers under long-context settings. We initially conceptualize the process as a streamlined encoder-decoder framework where the weights-shared encoder and decoder respectively encapsulate a context segment into memories and leverage these memories to predict outputs of the subsequent segment. Subsequently, by treating our memory-enhanced transformers as fully-connected recurrent neural networks (RNNs), we refine the training process using the Truncated Backpropagation Through Time (TBPTT) algorithm, which incorporates innovative incremental optimization techniques. These techniques not only diminish time complexity but also address the bias in gradient computation through an unbiased optimization process. UIO-LLMs successfully handle long context, such as extending the context window of Llama2-7b-chat from 4K to 100K tokens with minimal 2% additional parameters, while keeping the inference cost nearly linear as context length increases.
Learning Image Demoireing from Unpaired Real Data
Jan 05, 2024



This paper focuses on addressing the issue of image demoireing. Unlike the large volume of existing studies that rely on learning from paired real data, we attempt to learn a demoireing model from unpaired real data, i.e., moire images associated with irrelevant clean images. The proposed method, referred to as Unpaired Demoireing (UnDeM), synthesizes pseudo moire images from unpaired datasets, generating pairs with clean images for training demoireing models. To achieve this, we divide real moire images into patches and group them in compliance with their moire complexity. We introduce a novel moire generation framework to synthesize moire images with diverse moire features, resembling real moire patches, and details akin to real moire-free images. Additionally, we introduce an adaptive denoise method to eliminate the low-quality pseudo moire images that adversely impact the learning of demoireing models. We conduct extensive experiments on the commonly-used FHDMi and UHDM datasets. Results manifest that our UnDeM performs better than existing methods when using existing demoireing models such as MBCNN and ESDNet-L. Code: https://github.com/zysxmu/UnDeM
I&S-ViT: An Inclusive & Stable Method for Pushing the Limit of Post-Training ViTs Quantization
Nov 16, 2023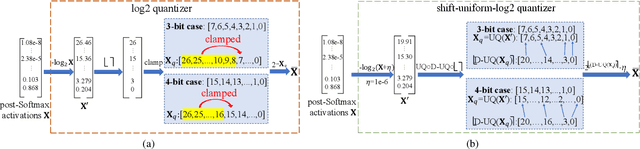
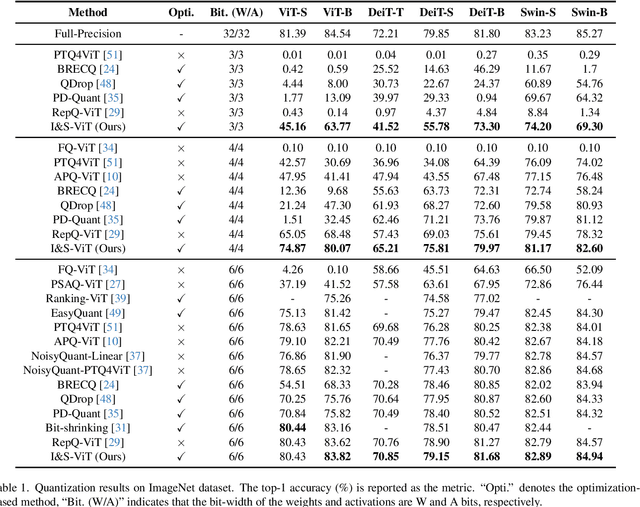
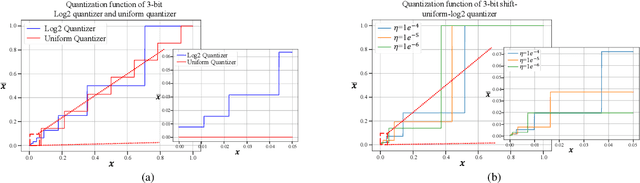
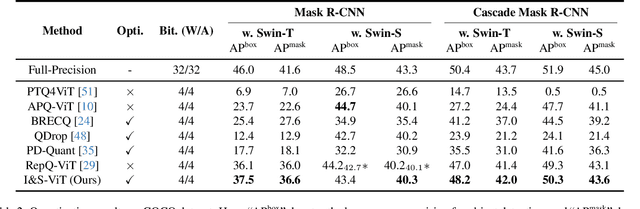
Albeit the scalable performance of vision transformers (ViTs), the dense computational costs (training & inference) undermine their position in industrial applications. Post-training quantization (PTQ), tuning ViTs with a tiny dataset and running in a low-bit format, well addresses the cost issue but unluckily bears more performance drops in lower-bit cases. In this paper, we introduce I&S-ViT, a novel method that regulates the PTQ of ViTs in an inclusive and stable fashion. I&S-ViT first identifies two issues in the PTQ of ViTs: (1) Quantization inefficiency in the prevalent log2 quantizer for post-Softmax activations; (2) Rugged and magnified loss landscape in coarse-grained quantization granularity for post-LayerNorm activations. Then, I&S-ViT addresses these issues by introducing: (1) A novel shift-uniform-log2 quantizer (SULQ) that incorporates a shift mechanism followed by uniform quantization to achieve both an inclusive domain representation and accurate distribution approximation; (2) A three-stage smooth optimization strategy (SOS) that amalgamates the strengths of channel-wise and layer-wise quantization to enable stable learning. Comprehensive evaluations across diverse vision tasks validate I&S-ViT' superiority over existing PTQ of ViTs methods, particularly in low-bit scenarios. For instance, I&S-ViT elevates the performance of 3-bit ViT-B by an impressive 50.68%.
Spatial Re-parameterization for N:M Sparsity
Jun 09, 2023This paper presents a Spatial Re-parameterization (SpRe) method for the N:M sparsity in CNNs. SpRe is stemmed from an observation regarding the restricted variety in spatial sparsity present in N:M sparsity compared with unstructured sparsity. Particularly, N:M sparsity exhibits a fixed sparsity rate within the spatial domains due to its distinctive pattern that mandates N non-zero components among M successive weights in the input channel dimension of convolution filters. On the contrary, we observe that unstructured sparsity displays a substantial divergence in sparsity across the spatial domains, which we experimentally verified to be very crucial for its robust performance retention compared with N:M sparsity. Therefore, SpRe employs the spatial-sparsity distribution of unstructured sparsity to assign an extra branch in conjunction with the original N:M branch at training time, which allows the N:M sparse network to sustain a similar distribution of spatial sparsity with unstructured sparsity. During inference, the extra branch can be further re-parameterized into the main N:M branch, without exerting any distortion on the sparse pattern or additional computation costs. SpRe has achieved a commendable feat by matching the performance of N:M sparsity methods with state-of-the-art unstructured sparsity methods across various benchmarks. Code and models are anonymously available at \url{https://github.com/zyxxmu/SpRe}.