 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRG-SAN: Rule-Guided Spatial Awareness Network for End-to-End 3D Referring Expression Segmentation
Dec 03, 2024



3D Referring Expression Segmentation (3D-RES) aims to segment 3D objects by correlating referring expressions with point clouds. However, traditional approaches frequently encounter issues like over-segmentation or mis-segmentation, due to insufficient emphasis on spatial information of instances. In this paper, we introduce a Rule-Guided Spatial Awareness Network (RG-SAN) by utilizing solely the spatial information of the target instance for supervision. This approach enables the network to accurately depict the spatial relationships among all entities described in the text, thus enhancing the reasoning capabilities. The RG-SAN consists of the Text-driven Localization Module (TLM) and the Rule-guided Weak Supervision (RWS) strategy. The TLM initially locates all mentioned instances and iteratively refines their positional information. The RWS strategy, acknowledging that only target objects have supervised positional information, employs dependency tree rules to precisely guide the core instance's positioning. Extensive testing on the ScanRefer benchmark has shown that RG-SAN not only establishes new performance benchmarks, with an mIoU increase of 5.1 points, but also exhibits significant improvements in robustness when processing descriptions with spatial ambiguity. All codes are available at https://github.com/sosppxo/RG-SAN.
ERQ: Error Reduction for Post-Training Quantization of Vision Transformers
Jul 09, 2024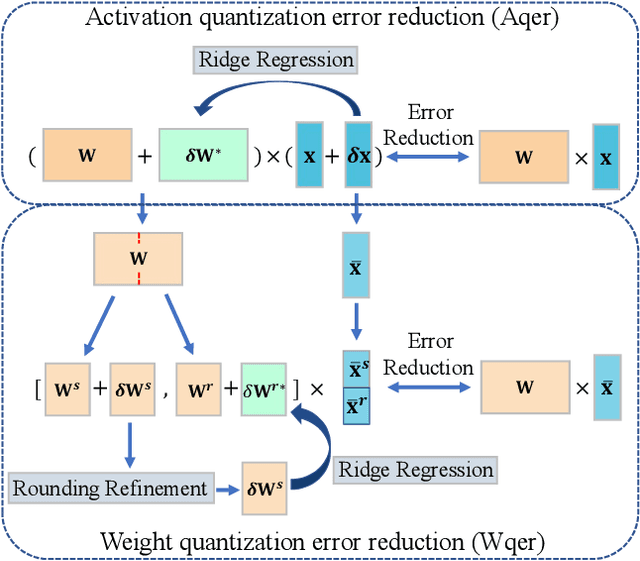

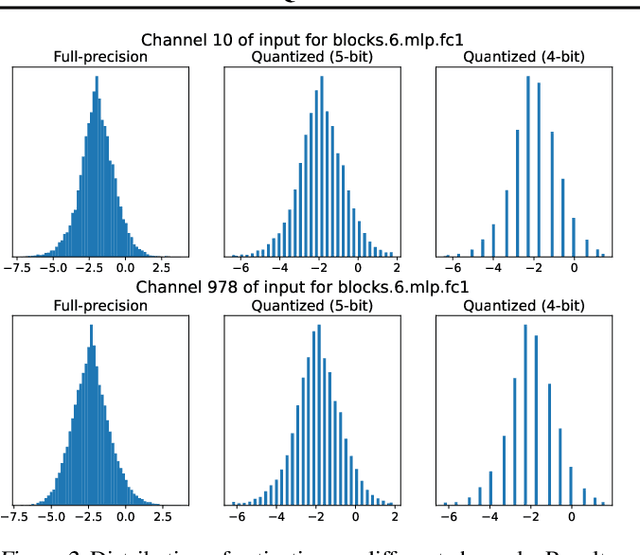
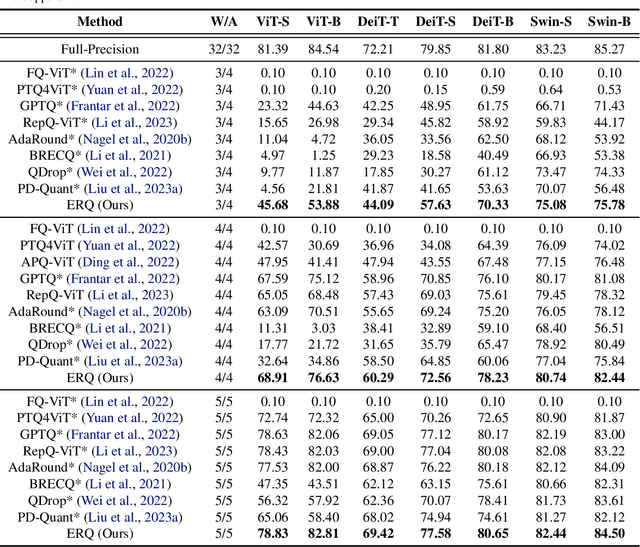
Post-training quantization (PTQ) for vision transformers (ViTs) has garnered significant attention due to its efficiency in compressing models. However, existing methods typically overlook the intricate interdependence between quantized weight and activation, leading to considerable quantization error. In this paper, we propose ERQ, a two-step PTQ approach meticulously crafted to sequentially reduce the quantization error arising from activation and weight quantization. ERQ first introduces Activation quantization error reduction (Aqer) that strategically formulates the minimization of activation quantization error as a Ridge Regression problem, tackling it by updating weights with full-precision. Subsequently, ERQ introduces Weight quantization error reduction (Wqer) that adopts an iterative approach to mitigate the quantization error induced by weight quantization. In each iteration, an empirically derived, efficient proxy is employed to refine the rounding directions of quantized weights, coupled with a Ridge Regression solver to curtail weight quantization error. Experimental results attest to the effectiveness of our approach. Notably, ERQ surpasses the state-of-the-art GPTQ by 22.36% in accuracy for W3A4 ViT-S.
HRSAM: Efficiently Segment Anything in High-Resolution Images
Jul 02, 2024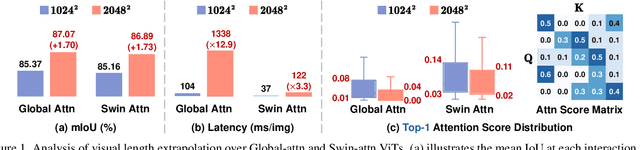
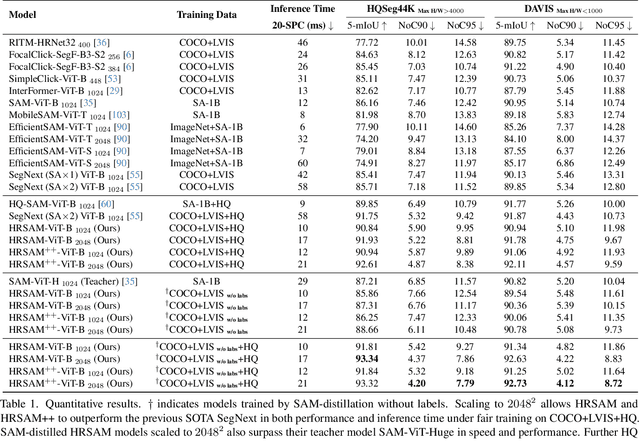

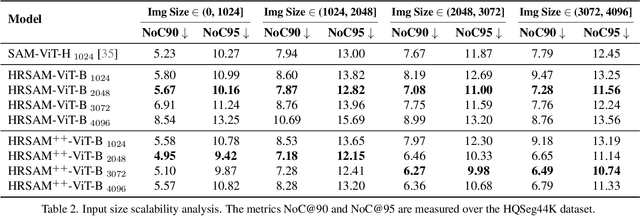
The Segment Anything Model (SAM) has significantly advanced interactive segmentation but struggles with high-resolution images crucial for high-precision segmentation. This is primarily due to the quadratic space complexity of SAM-implemented attention and the length extrapolation issue in common global attention. This study proposes HRSAM that integrates Flash Attention and incorporates Plain, Shifted and newly proposed Cycle-scan Window (PSCWin) attention to address these issues. The shifted window attention is redesigned with padding to maintain consistent window sizes, enabling effective length extrapolation. The cycle-scan window attention adopts the recently developed State Space Models (SSMs) to ensure global information exchange with minimal computational overhead. Such window-based attention allows HRSAM to perform effective attention computations on scaled input images while maintaining low latency. Moreover, we further propose HRSAM++ that additionally employs a multi-scale strategy to enhance HRSAM's performance. The experiments on the high-precision segmentation datasets HQSeg44K and DAVIS show that high-resolution inputs enable the SAM-distilled HRSAM models to outperform the teacher model while maintaining lower latency. Compared to the SOTAs, HRSAM achieves a 1.56 improvement in interactive segmentation's NoC95 metric with only 31% of the latency. HRSAM++ further enhances the performance, achieving a 1.63 improvement in NoC95 with just 38% of the latency.
FocSAM: Delving Deeply into Focused Objects in Segmenting Anything
May 29, 2024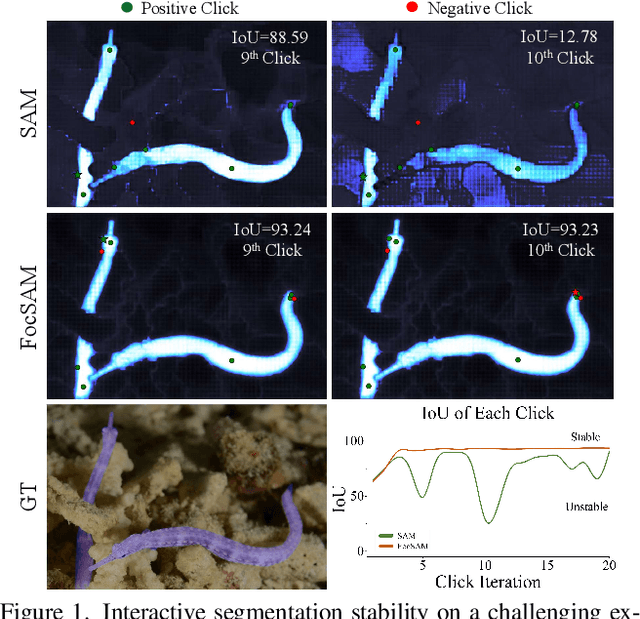
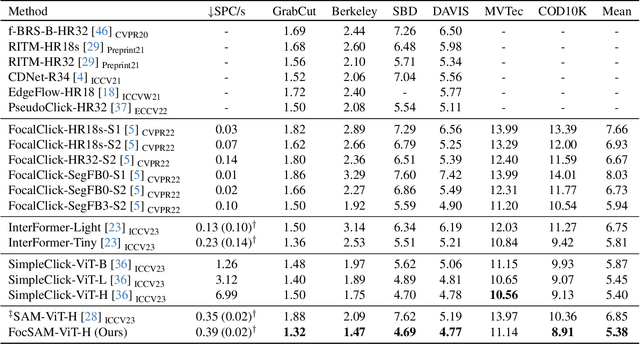
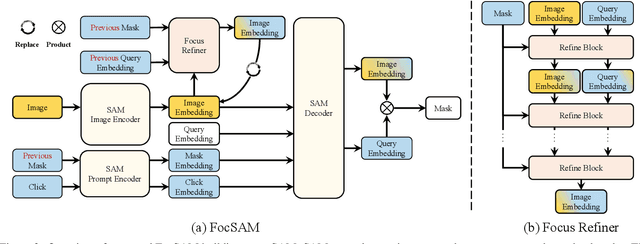

The Segment Anything Model (SAM) marks a notable milestone in segmentation models, highlighted by its robust zero-shot capabilities and ability to handle diverse prompts. SAM follows a pipeline that separates interactive segmentation into image preprocessing through a large encoder and interactive inference via a lightweight decoder, ensuring efficient real-time performance. However, SAM faces stability issues in challenging samples upon this pipeline. These issues arise from two main factors. Firstly, the image preprocessing disables SAM from dynamically using image-level zoom-in strategies to refocus on the target object during interaction. Secondly, the lightweight decoder struggles to sufficiently integrate interactive information with image embeddings. To address these two limitations, we propose FocSAM with a pipeline redesigned on two pivotal aspects. First, we propose Dynamic Window Multi-head Self-Attention (Dwin-MSA) to dynamically refocus SAM's image embeddings on the target object. Dwin-MSA localizes attention computations around the target object, enhancing object-related embeddings with minimal computational overhead. Second, we propose Pixel-wise Dynamic ReLU (P-DyReLU) to enable sufficient integration of interactive information from a few initial clicks that have significant impacts on the overall segmentation results. Experimentally, FocSAM augments SAM's interactive segmentation performance to match the existing state-of-the-art method in segmentation quality, requiring only about 5.6% of this method's inference time on CPUs.
InterFormer: Real-time Interactive Image Segmentation
Apr 06, 2023

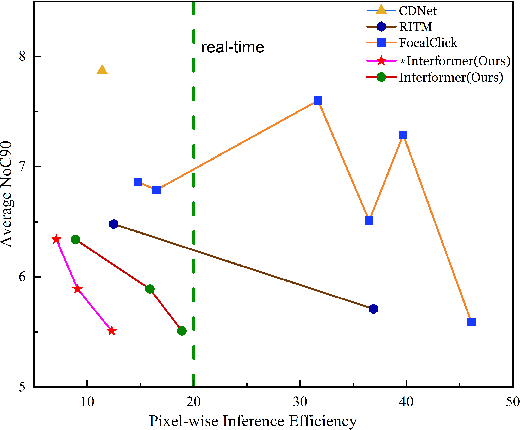

Interactive image segmentation enables annotators to efficiently perform pixel-level annotation for segmentation tasks. However, the existing interactive segmentation pipeline suffers from inefficient computations of interactive models because of the following two issues. First, annotators' later click is based on models' feedback of annotators' former click. This serial interaction is unable to utilize model's parallelism capabilities. Second, the model has to repeatedly process the image, the annotator's current click, and the model's feedback of the annotator's former clicks at each step of interaction, resulting in redundant computations. For efficient computation, we propose a method named InterFormer that follows a new pipeline to address these issues. InterFormer extracts and preprocesses the computationally time-consuming part i.e. image processing from the existing process. Specifically, InterFormer employs a large vision transformer (ViT) on high-performance devices to preprocess images in parallel, and then uses a lightweight module called interactive multi-head self attention (I-MSA) for interactive segmentation. Furthermore, the I-MSA module's deployment on low-power devices extends the practical application of interactive segmentation. The I-MSA module utilizes the preprocessed features to efficiently response to the annotator inputs in real-time. The experiments on several datasets demonstrate the effectiveness of InterFormer, which outperforms previous interactive segmentation models in terms of computational efficiency and segmentation quality, achieve real-time high-quality interactive segmentation on CPU-only devices.
An Internal Covariate Shift Bounding Algorithm for Deep Neural Networks by Unitizing Layers' Outputs
Jan 09, 2020

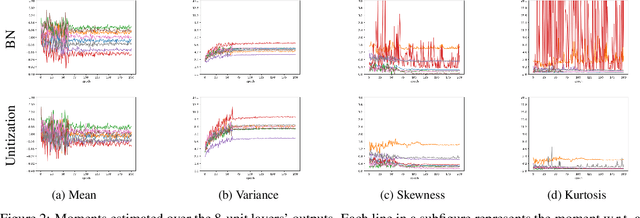

Batch Normalization (BN) techniques have been proposed to reduce the so-called Internal Covariate Shift (ICS) by attempting to keep the distributions of layer outputs unchanged. Experiments have shown their effectiveness on training deep neural networks. However, since only the first two moments are controlled in these BN techniques, it seems that a weak constraint is imposed on layer distributions and furthermore whether such constraint can reduce ICS is unknown. Thus this paper proposes a measure for ICS by using the Earth Mover (EM) distance and then derives the upper and lower bounds for the measure to provide a theoretical analysis of BN. The upper bound has shown that BN techniques can control ICS only for the outputs with low dimensions and small noise whereas their control is NOT effective in other cases. This paper also proves that such control is just a bounding of ICS rather than a reduction of ICS. Meanwhile, the analysis shows that the high-order moments and noise, which BN cannot control, have great impact on the lower bound. Based on such analysis, this paper furthermore proposes an algorithm that unitizes the outputs with an adjustable parameter to further bound ICS in order to cope with the problems of BN. The upper bound for the proposed unitization is noise-free and only dominated by the parameter. Thus, the parameter can be trained to tune the bound and further to control ICS. Besides, the unitization is embedded into the framework of BN to reduce the information loss. The experiments show that this proposed algorithm outperforms existing BN techniques on CIFAR-10, CIFAR-100 and ImageNet datasets.
Enhancement Mask for Hippocampus Detection and Segmentation
Feb 12, 2019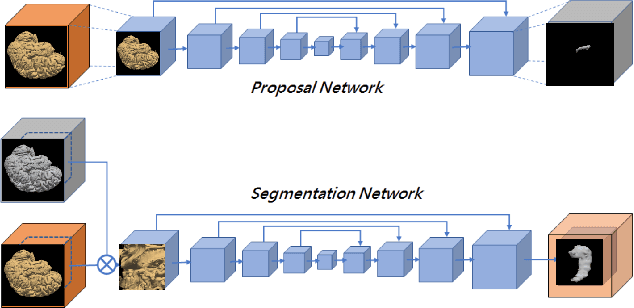

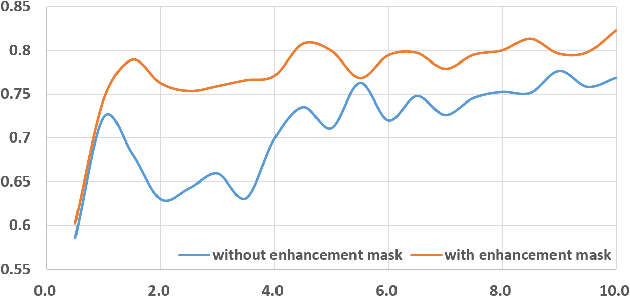
Detection and segmentation of the hippocampal structures in volumetric brain images is a challenging problem in the area of medical imaging. In this paper, we propose a two-stage 3D fully convolutional neural network that efficiently detects and segments the hippocampal structures. In particular, our approach first localizes the hippocampus from the whole volumetric image while obtaining a proposal for a rough segmentation. After localization, we apply the proposal as an enhancement mask to extract the fine structure of the hippocampus. The proposed method has been evaluated on a public dataset and compares with state-of-the-art approaches. Results indicate the effectiveness of the proposed method, which yields mean Dice Similarity Coefficients (i.e. DSC) of $0.897$ and $0.900$ for the left and right hippocampus, respectively. Furthermore, extensive experiments manifest that the proposed enhancement mask layer has remarkable benefits for accelerating training process and obtaining more accurate segmentation results.
* This paper has been published in the proceedings of IEEE International Conference on Information and Automation 2018