 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterFormer: Real-time Interactive Image Segmentation
Paper and Code


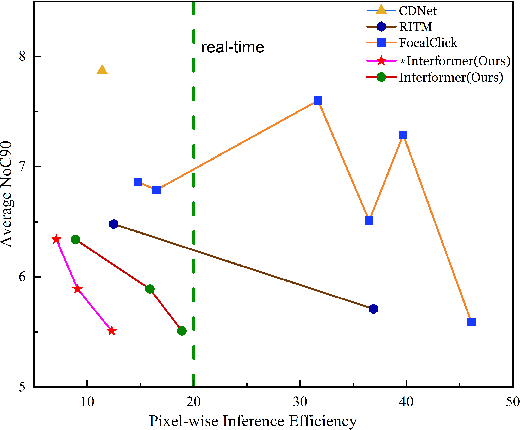

Interactive image segmentation enables annotators to efficiently perform pixel-level annotation for segmentation tasks. However, the existing interactive segmentation pipeline suffers from inefficient computations of interactive models because of the following two issues. First, annotators' later click is based on models' feedback of annotators' former click. This serial interaction is unable to utilize model's parallelism capabilities. Second, the model has to repeatedly process the image, the annotator's current click, and the model's feedback of the annotator's former clicks at each step of interaction, resulting in redundant computations. For efficient computation, we propose a method named InterFormer that follows a new pipeline to address these issues. InterFormer extracts and preprocesses the computationally time-consuming part i.e. image processing from the existing process. Specifically, InterFormer employs a large vision transformer (ViT) on high-performance devices to preprocess images in parallel, and then uses a lightweight module called interactive multi-head self attention (I-MSA) for interactive segmentation. Furthermore, the I-MSA module's deployment on low-power devices extends the practical application of interactive segmentation. The I-MSA module utilizes the preprocessed features to efficiently response to the annotator inputs in real-time. The experiments on several datasets demonstrate the effectiveness of InterFormer, which outperforms previous interactive segmentation models in terms of computational efficiency and segmentation quality, achieve real-time high-quality interactive segmentation on CPU-only devices.