 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEA-Vision: A Multilingual Benchmark for Comprehensive Document and Scene Text Understanding in Southeast Asia
Mar 16, 2026Multilingual document and scene text understanding plays an important role in applications such as search, finance, and public services. However, most existing benchmarks focus on high-resource languages and fail to evaluate models in realistic multilingual environments. In Southeast Asia, the diversity of languages, complex writing systems, and highly varied document types make this challenge even greater. We introduce SEA-Vision, a benchmark that jointly evaluates Document Parsing and Text-Centric Visual Question Answering (TEC-VQA) across 11 Southeast Asian languages. SEA-Vision contains 15,234 document parsing pages from nine representative document types, annotated with hierarchical page-, block-, and line-level labels. It also provides 7,496 TEC-VQA question-answer pairs that probe text recognition, numerical calculation, comparative analysis, logical reasoning, and spatial understanding. To make such multilingual, multi-task annotation feasible, we design a hybrid pipeline for Document Parsing and TEC-VQA. It combines automated filtering and scoring with MLLM-assisted labeling and lightweight native-speaker verification, greatly reducing manual labeling while maintaining high quality. We evaluate several leading multimodal models and observe pronounced performance degradation on low-resource Southeast Asian languages, highlighting substantial remaining gaps in multilingual document and scene text understanding. We believe SEA-Vision will help drive global progress in document and scene text understanding.
KVSlimmer: Theoretical Insights and Practical Optimizations for Asymmetric KV Merging
Mar 01, 2026The growing computational and memory demands of the Key-Value (KV) cache significantly limit the ability of Large Language Models (LLMs). While KV merging has emerged as a promising solution, existing methods that rely on empirical observations of KV asymmetry and gradient-based Hessian approximations lack a theoretical foundation and incur suboptimal compression and inference overhead. To bridge these gaps, we establish a theoretical framework that characterizes this asymmetry through the spectral energy distribution of projection weights, demonstrating that concentrated spectra in Query/Key weights induce feature homogeneity, whereas dispersed spectra in Value weights preserve heterogeneity. Then, we introduce KVSlimmer, an efficient algorithm that captures exact Hessian information through a mathematically exact formulation, and derives a closed-form solution utilizing only forward-pass variables, resulting in a gradient-free approach that is both memory- and time-efficient. Extensive experiments across various models and benchmarks demonstrate that KVSlimmer consistently outperforms SOTA methods. For instance, on Llama3.1-8B-Instruct, it improves the LongBench average score by 0.92 while reducing memory costs and latency by 29% and 28%, respectively.
Discover, Segment, and Select: A Progressive Mechanism for Zero-shot Camouflaged Object Segmentation
Feb 23, 2026Current zero-shot Camouflaged Object Segmentation methods typically employ a two-stage pipeline (discover-then-segment): using MLLMs to obtain visual prompts, followed by SAM segmentation. However, relying solely on MLLMs for camouflaged object discovery often leads to inaccurate localization, false positives, and missed detections. To address these issues, we propose the \textbf{D}iscover-\textbf{S}egment-\textbf{S}elect (\textbf{DSS}) mechanism, a progressive framework designed to refine segmentation step by step. The proposed method contains a Feature-coherent Object Discovery (FOD) module that leverages visual features to generate diverse object proposals, a segmentation module that refines these proposals through SAM segmentation, and a Semantic-driven Mask Selection (SMS) module that employs MLLMs to evaluate and select the optimal segmentation mask from multiple candidates. Without requiring any training or supervision, DSS achieves state-of-the-art performance on multiple COS benchmarks, especially in multiple-instance scenes.
Referring Industrial Anomaly Segmentation
Feb 03, 2026Industrial Anomaly Detection (IAD) is vital for manufacturing, yet traditional methods face significant challenges: unsupervised approaches yield rough localizations requiring manual thresholds, while supervised methods overfit due to scarce, imbalanced data. Both suffer from the "One Anomaly Class, One Model" limitation. To address this, we propose Referring Industrial Anomaly Segmentation (RIAS), a paradigm leveraging language to guide detection. RIAS generates precise masks from text descriptions without manual thresholds and uses universal prompts to detect diverse anomalies with a single model. We introduce the MVTec-Ref dataset to support this, designed with diverse referring expressions and focusing on anomaly patterns, notably with 95% small anomalies. We also propose the Dual Query Token with Mask Group Transformer (DQFormer) benchmark, enhanced by Language-Gated Multi-Level Aggregation (LMA) to improve multi-scale segmentation. Unlike traditional methods using redundant queries, DQFormer employs only "Anomaly" and "Background" tokens for efficient visual-textual integration. Experiments demonstrate RIAS's effectiveness in advancing IAD toward open-set capabilities. Code: https://github.com/swagger-coder/RIAS-MVTec-Ref.
SCOUT: Semi-supervised Camouflaged Object Detection by Utilizing Text and Adaptive Data Selection
Aug 25, 2025

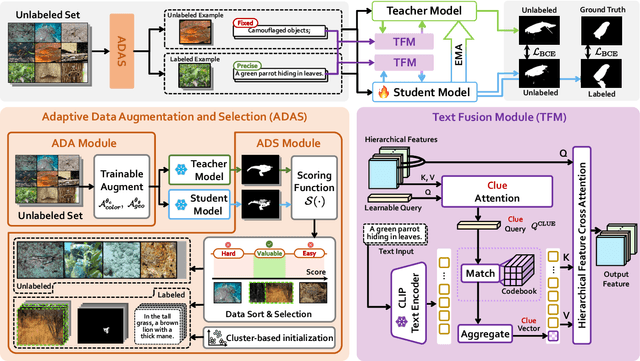

The difficulty of pixel-level annotation has significantly hindered the development of the Camouflaged Object Detection (COD) field. To save on annotation costs, previous works leverage the semi-supervised COD framework that relies on a small number of labeled data and a large volume of unlabeled data. We argue that there is still significant room for improvement in the effective utilization of unlabeled data. To this end, we introduce a Semi-supervised Camouflaged Object Detection by Utilizing Text and Adaptive Data Selection (SCOUT). It includes an Adaptive Data Augment and Selection (ADAS) module and a Text Fusion Module (TFM). The ADSA module selects valuable data for annotation through an adversarial augment and sampling strategy. The TFM module further leverages the selected valuable data by combining camouflage-related knowledge and text-visual interaction. To adapt to this work, we build a new dataset, namely RefTextCOD. Extensive experiments show that the proposed method surpasses previous semi-supervised methods in the COD field and achieves state-of-the-art performance. Our code will be released at https://github.com/Heartfirey/SCOUT.
XSpecMesh: Quality-Preserving Auto-Regressive Mesh Generation Acceleration via Multi-Head Speculative Decoding
Jul 31, 2025Current auto-regressive models can generate high-quality, topologically precise meshes; however, they necessitate thousands-or even tens of thousands-of next-token predictions during inference, resulting in substantial latency. We introduce XSpecMesh, a quality-preserving acceleration method for auto-regressive mesh generation models. XSpecMesh employs a lightweight, multi-head speculative decoding scheme to predict multiple tokens in parallel within a single forward pass, thereby accelerating inference. We further propose a verification and resampling strategy: the backbone model verifies each predicted token and resamples any tokens that do not meet the quality criteria. In addition, we propose a distillation strategy that trains the lightweight decoding heads by distilling from the backbone model, encouraging their prediction distributions to align and improving the success rate of speculative predictions. Extensive experiments demonstrate that our method achieves a 1.7x speedup without sacrificing generation quality. Our code will be released.
UCOD-DPL: Unsupervised Camouflaged Object Detection via Dynamic Pseudo-label Learning
Jun 08, 2025Unsupervised Camoflaged Object Detection (UCOD) has gained attention since it doesn't need to rely on extensive pixel-level labels. Existing UCOD methods typically generate pseudo-labels using fixed strategies and train 1 x1 convolutional layers as a simple decoder, leading to low performance compared to fully-supervised methods. We emphasize two drawbacks in these approaches: 1). The model is prone to fitting incorrect knowledge due to the pseudo-label containing substantial noise. 2). The simple decoder fails to capture and learn the semantic features of camouflaged objects, especially for small-sized objects, due to the low-resolution pseudo-labels and severe confusion between foreground and background pixels. To this end, we propose a UCOD method with a teacher-student framework via Dynamic Pseudo-label Learning called UCOD-DPL, which contains an Adaptive Pseudo-label Module (APM), a Dual-Branch Adversarial (DBA) decoder, and a Look-Twice mechanism. The APM module adaptively combines pseudo-labels generated by fixed strategies and the teacher model to prevent the model from overfitting incorrect knowledge while preserving the ability for self-correction; the DBA decoder takes adversarial learning of different segmentation objectives, guides the model to overcome the foreground-background confusion of camouflaged objects, and the Look-Twice mechanism mimics the human tendency to zoom in on camouflaged objects and performs secondary refinement on small-sized objects. Extensive experiments show that our method demonstrates outstanding performance, even surpassing some existing fully supervised methods. The code is available now.
What You Perceive Is What You Conceive: A Cognition-Inspired Framework for Open Vocabulary Image Segmentation
May 26, 2025



Open vocabulary image segmentation tackles the challenge of recognizing dynamically adjustable, predefined novel categories at inference time by leveraging vision-language alignment. However, existing paradigms typically perform class-agnostic region segmentation followed by category matching, which deviates from the human visual system's process of recognizing objects based on semantic concepts, leading to poor alignment between region segmentation and target concepts. To bridge this gap, we propose a novel Cognition-Inspired Framework for open vocabulary image segmentation that emulates the human visual recognition process: first forming a conceptual understanding of an object, then perceiving its spatial extent. The framework consists of three core components: (1) A Generative Vision-Language Model (G-VLM) that mimics human cognition by generating object concepts to provide semantic guidance for region segmentation. (2) A Concept-Aware Visual Enhancer Module that fuses textual concept features with global visual representations, enabling adaptive visual perception based on target concepts. (3) A Cognition-Inspired Decoder that integrates local instance features with G-VLM-provided semantic cues, allowing selective classification over a subset of relevant categories. Extensive experiments demonstrate that our framework achieves significant improvements, reaching $27.2$ PQ, $17.0$ mAP, and $35.3$ mIoU on A-150. It further attains $56.2$, $28.2$, $15.4$, $59.2$, $18.7$, and $95.8$ mIoU on Cityscapes, Mapillary Vistas, A-847, PC-59, PC-459, and PAS-20, respectively. In addition, our framework supports vocabulary-free segmentation, offering enhanced flexibility in recognizing unseen categories. Code will be public.
Pseudo-Label Quality Decoupling and Correction for Semi-Supervised Instance Segmentation
May 16, 2025Semi-Supervised Instance Segmentation (SSIS) involves classifying and grouping image pixels into distinct object instances using limited labeled data. This learning paradigm usually faces a significant challenge of unstable performance caused by noisy pseudo-labels of instance categories and pixel masks. We find that the prevalent practice of filtering instance pseudo-labels assessing both class and mask quality with a single score threshold, frequently leads to compromises in the trade-off between the qualities of class and mask labels. In this paper, we introduce a novel Pseudo-Label Quality Decoupling and Correction (PL-DC) framework for SSIS to tackle the above challenges. Firstly, at the instance level, a decoupled dual-threshold filtering mechanism is designed to decouple class and mask quality estimations for instance-level pseudo-labels, thereby independently controlling pixel classifying and grouping qualities. Secondly, at the category level, we introduce a dynamic instance category correction module to dynamically correct the pseudo-labels of instance categories, effectively alleviating category confusion. Lastly, we introduce a pixel-level mask uncertainty-aware mechanism at the pixel level to re-weight the mask loss for different pixels, thereby reducing the impact of noise introduced by pixel-level mask pseudo-labels. Extensive experiments on the COCO and Cityscapes datasets demonstrate that the proposed PL-DC achieves significant performance improvements, setting new state-of-the-art results for SSIS. Notably, our PL-DC shows substantial gains even with minimal labeled data, achieving an improvement of +11.6 mAP with just 1% COCO labeled data and +15.5 mAP with 5% Cityscapes labeled data. The code will be public.
SynergyAmodal: Deocclude Anything with Text Control
Apr 28, 2025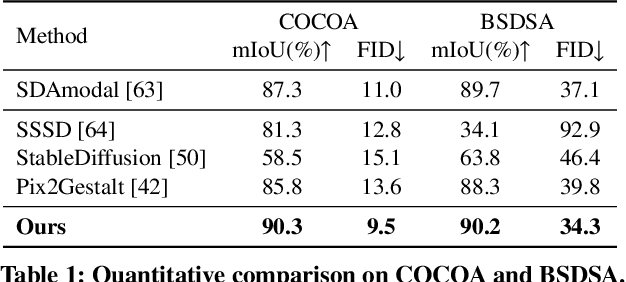

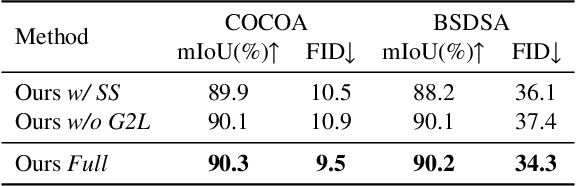
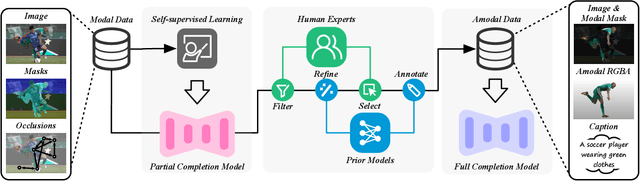
Image deocclusion (or amodal completion) aims to recover the invisible regions (\ie, shape and appearance) of occluded instances in images. Despite recent advances, the scarcity of high-quality data that balances diversity, plausibility, and fidelity remains a major obstacle. To address this challenge, we identify three critical elements: leveraging in-the-wild image data for diversity, incorporating human expertise for plausibility, and utilizing generative priors for fidelity. We propose SynergyAmodal, a novel framework for co-synthesizing in-the-wild amodal datasets with comprehensive shape and appearance annotations, which integrates these elements through a tripartite data-human-model collaboration. First, we design an occlusion-grounded self-supervised learning algorithm to harness the diversity of in-the-wild image data, fine-tuning an inpainting diffusion model into a partial completion diffusion model. Second, we establish a co-synthesis pipeline to iteratively filter, refine, select, and annotate the initial deocclusion results of the partial completion diffusion model, ensuring plausibility and fidelity through human expert guidance and prior model constraints. This pipeline generates a high-quality paired amodal dataset with extensive category and scale diversity, comprising approximately 16K pairs. Finally, we train a full completion diffusion model on the synthesized dataset, incorporating text prompts as conditioning signals. Extensive experiments demonstrate the effectiveness of our framework in achieving zero-shot generalization and textual controllability. Our code, dataset, and models will be made publicly available at https://github.com/imlixinyang/SynergyAmodal.