 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeAP: Learnable Adaptive Permutation for Feature Selection in Heterogeneous and Sparse Recommender Systems
May 31, 2026Modern industrial recommender systems rely on thousands of heterogeneous features -- ranging from low-dimensional scalars (e.g., statistical value) to high-dimensional embeddings (e.g., user-id embeddings, MLP representations) -- to achieve high-precision predictions. Given the immense computational costs associated with training, efficient feature selection is critical. However, existing methods encounter three primary bottlenecks: (1) they typically assume uniform feature dimensions or require costly mapping to a fixed size; (2) they struggle with extreme sparsity, where the majority of features (e.g., 99%+) remain at default values; and (3) traditional permutation-based approaches are computationally prohibitive in large-scale settings. To address these challenges, we propose LeAP (Learnable Adaptive Permutation), a novel, model-agnostic plug-in module for feature selection. LeAP transforms the inefficient random permutation process into a learnable mechanism, significantly accelerating the evaluation of feature importance. In addition, we introduce an adaptive regularization strategy tailored for heterogeneous dimensions and extreme sparsity, enabling superior feature importance ranking results across asymmetric input spaces. Experiments on four public recommendation datasets demonstrate that LeAP achieves state-of-the-art performance. Furthermore, LeAP has been deployed in a large-scale industrial search ranking model with over a billion daily requests and a 2TB model parameter scale. In this real-world scenario involving 12,000+ total feature dimensions, LeAP successfully identified and removed over 3,600 redundant dimensions without performance degradation, which is 2 to 10 times the ability of compared baseline methods.
Data-Efficient On-Policy Distillation for Automatic Speech Recognition
May 27, 2026Building competitive automatic speech recognition (ASR) models usually requires large-scale au- dio supervision, which makes reproduction and specialization expensive. We study Ark-ASR, a 0.6B- parameter audio-conditioned language model trained with 100k hours of speech, and examine whether a strong Qwen-ASR teacher can transfer additional recognition capability through on-policy distillation. Across Mandarin and English ASR benchmarks, the proposed training recipe consistently improves over supervised fine-tuning alone and outperforms the same-scale Qwen3-ASR-0.6B baseline on four of five evaluation sets. This is achieved with only 100k hours of speech, compared with the 20M hours of super- vised audio reported for the Qwen3-Omni AuT encoder. The larger Qwen3-ASR-1.7B remains stronger, but the results show that teacher-guided on-policy training can substantially close the gap for compact ASR models under a much smaller audio budget. A support-overlap diagnostic further suggests that the teacher-data stage improves local student-teacher compatibility, matching recent analyses of when on-policy distillation is effective.
Tiny-Engram: Trigger-Indexed Concept Tables for Generative Vision
May 19, 2026Current personalization methods for generative vision models typically encode new concepts through continuous adapters or weight updates, yet provide limited control over whether and when a concept should be retrieved. In this work, we introduce Tiny-Engram, a compact trigger-indexed concept table that gives visual memories an explicit lexical address and activation boundary inside frozen image and video generators. Tiny-Engram parameterizes each concept as a small set of memory entries indexed by registered n-gram matches, which modulate text-encoder hidden states only within the matched trigger region. Outside this lexical support, the conditioning pathway is identical to that of the frozen base model. Across both single-encoder latent diffusion and multi-encoder diffusion-transformer backbones, this formulation binds a rare trigger phrase to a target identity while preserving compositional control from the surrounding prompt. We further evaluate the same table-based memory in a text-conditioned video generation setting, where the trigger path reliably alters the generated subject but fine-grained identity persistence across held-out video prompts remains limited. Taken together, these results suggest that small, explicitly addressed concept tables are a practical route to modular visual personalization, with strongest evidence in image generation. For video diffusion, the remaining gap points to a broader requirement: temporally stable identity likely depends on tighter coupling between text-side memory and the evolving visual state, motivating future work on memory injection beyond the text-conditioning interface.
Active-SAOOD: Active Sparsely Annotated Oriented Object Detection in Remote Sensing Images
May 11, 2026Reducing the annotation cost of oriented object detection in remote sensing remains a major challenge. Recently, sparse annotation has gained attention for effectively reducing annotation redundancy in densely remote sensing scenes. However, (1) the sparse data reliance on class-dependent sampling, and (2) the lack of in-depth investigation into the characteristics of sparse samples hinders its further development. This paper proposes an active learning-based sparsely annotated oriented object detection (SAOOD) method, termed Active-SAOOD. Based on a model state observation module, Active-SAOOD actively selects the most valuable sparse samples at the instance level that are best suited to the current model state, by jointly considering orientation, classification, and localization uncertainty, as well as inter- and intra-class diversity. This design enables SAOOD to operate stably under completely randomly initialized sparse annotations and extends its applicability to broader real-world. Experiments on multiple datasets demonstrate that Active-SAOOD significantly improves both performance and stability of existing SAOOD methods under various random sparse annotation. In particular, with only 1\% annotated ratios, it achieves a 9\% performance gain over the baseline, further enhancing the practical value of SAOOD in remote sensing. The code will be public.
Towards Privacy-Preserving LLM Inference via Collaborative Obfuscation (Technical Report)
Mar 02, 2026The rapid development of large language models (LLMs) has driven the widespread adoption of cloud-based LLM inference services, while also bringing prominent privacy risks associated with the transmission and processing of private data in remote inference. For privacy-preserving LLM inference technologies to be practically applied in industrial scenarios, three core requirements must be satisfied simultaneously: (1) Accuracy and efficiency losses should be minimized to mitigate degradation in service experience. (2) The inference process can be run on large-scale clusters consist of heterogeneous legacy xPUs. (3) Compatibility with existing LLM infrastructures should be ensured to reuse their engineering optimizations. To the best of our knowledge, none of the existing privacy-preserving LLM inference methods satisfy all the above constraints while delivering meaningful privacy guarantees. In this paper, we propose AloePri, the first privacy-preserving LLM inference method for industrial applications. AloePri protects both the input and output data by covariant obfuscation, which jointly transforms data and model parameters to achieve better accuracy and privacy. We carefully design the transformation for each model component to ensure inference accuracy and data privacy while keeping full compatibility with existing infrastructures of Language Model as a Service. AloePri has been integrated into an industrial system for the evaluation of mainstream LLMs. The evaluation on Deepseek-V3.1-Terminus model (671B parameters) demonstrates that AloePri causes accuracy loss of 0.0%~3.5% and exhibits efficiency equivalent to that of plaintext inference. Meanwhile, AloePri successfully resists state-of-the-art attacks, with less than 5\% of tokens recovered. To the best of our knowledge, AloePri is the first method to exhibit practical applicability to large-scale models in real-world systems.
Enhancing Open-Vocabulary Object Detection through Multi-Level Fine-Grained Visual-Language Alignment
Jan 31, 2026Traditional object detection systems are typically constrained to predefined categories, limiting their applicability in dynamic environments. In contrast, open-vocabulary object detection (OVD) enables the identification of objects from novel classes not present in the training set. Recent advances in visual-language modeling have led to significant progress of OVD. However, prior works face challenges in either adapting the single-scale image backbone from CLIP to the detection framework or ensuring robust visual-language alignment. We propose Visual-Language Detection (VLDet), a novel framework that revamps feature pyramid for fine-grained visual-language alignment, leading to improved OVD performance. With the VL-PUB module, VLDet effectively exploits the visual-language knowledge from CLIP and adapts the backbone for object detection through feature pyramid. In addition, we introduce the SigRPN block, which incorporates a sigmoid-based anchor-text contrastive alignment loss to improve detection of novel categories. Through extensive experiments, our approach achieves 58.7 AP for novel classes on COCO2017 and 24.8 AP on LVIS, surpassing all state-of-the-art methods and achieving significant improvements of 27.6% and 6.9%, respectively. Furthermore, VLDet also demonstrates superior zero-shot performance on closed-set object detection.
Unifying Speech Recognition, Synthesis and Conversion with Autoregressive Transformers
Jan 15, 2026Traditional speech systems typically rely on separate, task-specific models for text-to-speech (TTS), automatic speech recognition (ASR), and voice conversion (VC), resulting in fragmented pipelines that limit scalability, efficiency, and cross-task generalization. In this paper, we present General-Purpose Audio (GPA), a unified audio foundation model that integrates multiple core speech tasks within a single large language model (LLM) architecture. GPA operates on a shared discrete audio token space and supports instruction-driven task induction, enabling a single autoregressive model to flexibly perform TTS, ASR, and VC without architectural modifications. This unified design combines a fully autoregressive formulation over discrete speech tokens, joint multi-task training across speech domains, and a scalable inference pipeline that achieves high concurrency and throughput. The resulting model family supports efficient multi-scale deployment, including a lightweight 0.3B-parameter variant optimized for edge and resource-constrained environments. Together, these design choices demonstrate that a unified autoregressive architecture can achieve competitive performance across diverse speech tasks while remaining viable for low-latency, practical deployment.
Traceable Drug Recommendation over Medical Knowledge Graphs
Oct 31, 2025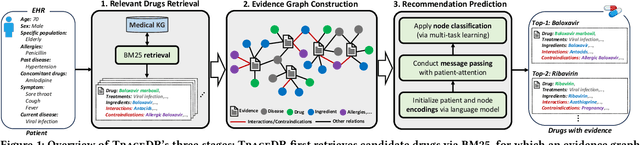
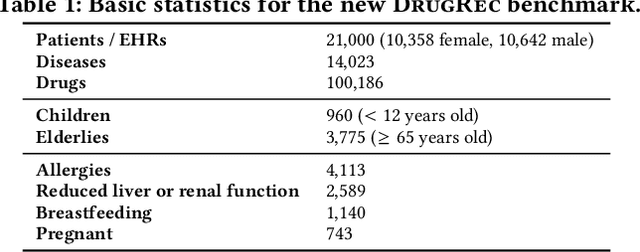
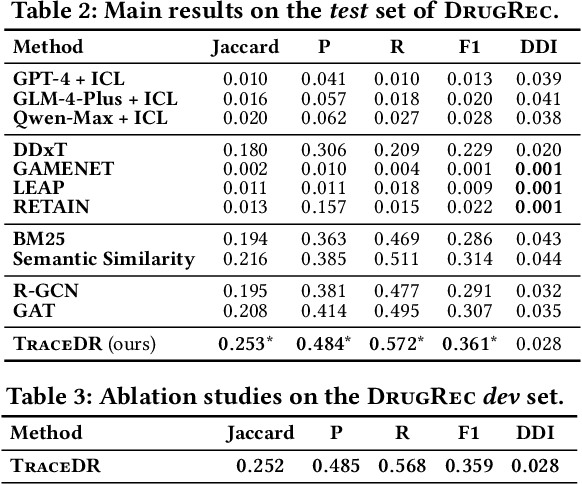

Drug recommendation (DR) systems aim to support healthcare professionals in selecting appropriate medications based on patients' medical conditions. State-of-the-art approaches utilize deep learning techniques for improving DR, but fall short in providing any insights on the derivation process of recommendations -- a critical limitation in such high-stake applications. We propose TraceDR, a novel DR system operating over a medical knowledge graph (MKG), which ensures access to large-scale and high-quality information. TraceDR simultaneously predicts drug recommendations and related evidence within a multi-task learning framework, enabling traceability of medication recommendations. For covering a more diverse set of diseases and drugs than existing works, we devise a framework for automatically constructing patient health records and release DrugRec, a new large-scale testbed for DR.
S$^2$Teacher: Step-by-step Teacher for Sparsely Annotated Oriented Object Detection
Apr 15, 2025



Although fully-supervised oriented object detection has made significant progress in multimodal remote sensing image understanding, it comes at the cost of labor-intensive annotation. Recent studies have explored weakly and semi-supervised learning to alleviate this burden. However, these methods overlook the difficulties posed by dense annotations in complex remote sensing scenes. In this paper, we introduce a novel setting called sparsely annotated oriented object detection (SAOOD), which only labels partial instances, and propose a solution to address its challenges. Specifically, we focus on two key issues in the setting: (1) sparse labeling leading to overfitting on limited foreground representations, and (2) unlabeled objects (false negatives) confusing feature learning. To this end, we propose the S$^2$Teacher, a novel method that progressively mines pseudo-labels for unlabeled objects, from easy to hard, to enhance foreground representations. Additionally, it reweights the loss of unlabeled objects to mitigate their impact during training. Extensive experiments demonstrate that S$^2$Teacher not only significantly improves detector performance across different sparse annotation levels but also achieves near-fully-supervised performance on the DOTA dataset with only 10% annotation instances, effectively balancing detection accuracy with annotation efficiency. The code will be public.
RDG-GS: Relative Depth Guidance with Gaussian Splatting for Real-time Sparse-View 3D Rendering
Jan 19, 2025Efficiently synthesizing novel views from sparse inputs while maintaining accuracy remains a critical challenge in 3D reconstruction. While advanced techniques like radiance fields and 3D Gaussian Splatting achieve rendering quality and impressive efficiency with dense view inputs, they suffer from significant geometric reconstruction errors when applied to sparse input views. Moreover, although recent methods leverage monocular depth estimation to enhance geometric learning, their dependence on single-view estimated depth often leads to view inconsistency issues across different viewpoints. Consequently, this reliance on absolute depth can introduce inaccuracies in geometric information, ultimately compromising the quality of scene reconstruction with Gaussian splats. In this paper, we present RDG-GS, a novel sparse-view 3D rendering framework with Relative Depth Guidance based on 3D Gaussian Splatting. The core innovation lies in utilizing relative depth guidance to refine the Gaussian field, steering it towards view-consistent spatial geometric representations, thereby enabling the reconstruction of accurate geometric structures and capturing intricate textures. First, we devise refined depth priors to rectify the coarse estimated depth and insert global and fine-grained scene information to regular Gaussians. Building on this, to address spatial geometric inaccuracies from absolute depth, we propose relative depth guidance by optimizing the similarity between spatially correlated patches of depth and images. Additionally, we also directly deal with the sparse areas challenging to converge by the adaptive sampling for quick densification. Across extensive experiments on Mip-NeRF360, LLFF, DTU, and Blender, RDG-GS demonstrates state-of-the-art rendering quality and efficiency, making a significant advancement for real-world application.