 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivateLoRA For Efficient Privacy Preserving LLM
Paper and Code


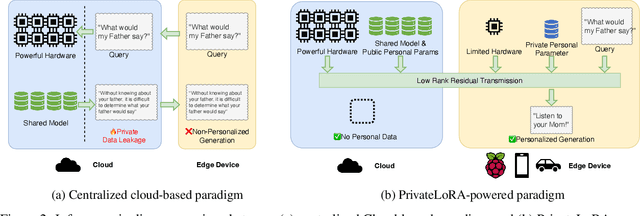

End users face a choice between privacy and efficiency in current Large Language Model (LLM) service paradigms. In cloud-based paradigms, users are forced to compromise data locality for generation quality and processing speed. Conversely, edge device paradigms maintain data locality but fail to deliver satisfactory performance. In this work, we propose a novel LLM service paradigm that distributes privacy-sensitive computation on edge devices and shared computation in the cloud. Only activations are transmitted between the central cloud and edge devices to ensure data locality. Our core innovation, PrivateLoRA, addresses the challenging communication overhead by exploiting the low rank of residual activations, achieving over 95% communication reduction. Consequently, PrivateLoRA effectively maintains data locality and is extremely resource efficient. Under standard 5G networks, PrivateLoRA achieves throughput over 300% of device-only solutions for 7B models and over 80% of an A100 GPU for 33B models. PrivateLoRA also provides tuning performance comparable to LoRA for advanced personalization. Our approach democratizes access to state-of-the-art generative AI for edge devices, paving the way for more tailored LLM experiences for the general public. To our knowledge, our proposed framework is the first efficient and privacy-preserving LLM solution in the literature.