 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Industrial Anomaly Segmentation
Feb 03, 2026Industrial Anomaly Detection (IAD) is vital for manufacturing, yet traditional methods face significant challenges: unsupervised approaches yield rough localizations requiring manual thresholds, while supervised methods overfit due to scarce, imbalanced data. Both suffer from the "One Anomaly Class, One Model" limitation. To address this, we propose Referring Industrial Anomaly Segmentation (RIAS), a paradigm leveraging language to guide detection. RIAS generates precise masks from text descriptions without manual thresholds and uses universal prompts to detect diverse anomalies with a single model. We introduce the MVTec-Ref dataset to support this, designed with diverse referring expressions and focusing on anomaly patterns, notably with 95% small anomalies. We also propose the Dual Query Token with Mask Group Transformer (DQFormer) benchmark, enhanced by Language-Gated Multi-Level Aggregation (LMA) to improve multi-scale segmentation. Unlike traditional methods using redundant queries, DQFormer employs only "Anomaly" and "Background" tokens for efficient visual-textual integration. Experiments demonstrate RIAS's effectiveness in advancing IAD toward open-set capabilities. Code: https://github.com/swagger-coder/RIAS-MVTec-Ref.
Evolving, Not Training: Zero-Shot Reasoning Segmentation via Evolutionary Prompting
Dec 31, 2025Reasoning Segmentation requires models to interpret complex, context-dependent linguistic queries to achieve pixel-level localization. Current dominant approaches rely heavily on Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL). However, SFT suffers from catastrophic forgetting and domain dependency, while RL is often hindered by training instability and rigid reliance on predefined reward functions. Although recent training-free methods circumvent these training burdens, they are fundamentally limited by a static inference paradigm. These methods typically rely on a single-pass "generate-then-segment" chain, which suffers from insufficient reasoning depth and lacks the capability to self-correct linguistic hallucinations or spatial misinterpretations. In this paper, we challenge these limitations and propose EVOL-SAM3, a novel zero-shot framework that reformulates reasoning segmentation as an inference-time evolutionary search process. Instead of relying on a fixed prompt, EVOL-SAM3 maintains a population of prompt hypotheses and iteratively refines them through a "Generate-Evaluate-Evolve" loop. We introduce a Visual Arena to assess prompt fitness via reference-free pairwise tournaments, and a Semantic Mutation operator to inject diversity and correct semantic errors. Furthermore, a Heterogeneous Arena module integrates geometric priors with semantic reasoning to ensure robust final selection. Extensive experiments demonstrate that EVOL-SAM3 not only substantially outperforms static baselines but also significantly surpasses fully supervised state-of-the-art methods on the challenging ReasonSeg benchmark in a zero-shot setting. The code is available at https://github.com/AHideoKuzeA/Evol-SAM3.
Understanding What Is Not Said:Referring Remote Sensing Image Segmentation with Scarce Expressions
Oct 26, 2025Referring Remote Sensing Image Segmentation (RRSIS) aims to segment instances in remote sensing images according to referring expressions. Unlike Referring Image Segmentation on general images, acquiring high-quality referring expressions in the remote sensing domain is particularly challenging due to the prevalence of small, densely distributed objects and complex backgrounds. This paper introduces a new learning paradigm, Weakly Referring Expression Learning (WREL) for RRSIS, which leverages abundant class names as weakly referring expressions together with a small set of accurate ones to enable efficient training under limited annotation conditions. Furthermore, we provide a theoretical analysis showing that mixed-referring training yields a provable upper bound on the performance gap relative to training with fully annotated referring expressions, thereby establishing the validity of this new setting. We also propose LRB-WREL, which integrates a Learnable Reference Bank (LRB) to refine weakly referring expressions through sample-specific prompt embeddings that enrich coarse class-name inputs. Combined with a teacher-student optimization framework using dynamically scheduled EMA updates, LRB-WREL stabilizes training and enhances cross-modal generalization under noisy weakly referring supervision. Extensive experiments on our newly constructed benchmark with varying weakly referring data ratios validate both the theoretical insights and the practical effectiveness of WREL and LRB-WREL, demonstrating that they can approach or even surpass models trained with fully annotated referring expressions.
What You Perceive Is What You Conceive: A Cognition-Inspired Framework for Open Vocabulary Image Segmentation
May 26, 2025



Open vocabulary image segmentation tackles the challenge of recognizing dynamically adjustable, predefined novel categories at inference time by leveraging vision-language alignment. However, existing paradigms typically perform class-agnostic region segmentation followed by category matching, which deviates from the human visual system's process of recognizing objects based on semantic concepts, leading to poor alignment between region segmentation and target concepts. To bridge this gap, we propose a novel Cognition-Inspired Framework for open vocabulary image segmentation that emulates the human visual recognition process: first forming a conceptual understanding of an object, then perceiving its spatial extent. The framework consists of three core components: (1) A Generative Vision-Language Model (G-VLM) that mimics human cognition by generating object concepts to provide semantic guidance for region segmentation. (2) A Concept-Aware Visual Enhancer Module that fuses textual concept features with global visual representations, enabling adaptive visual perception based on target concepts. (3) A Cognition-Inspired Decoder that integrates local instance features with G-VLM-provided semantic cues, allowing selective classification over a subset of relevant categories. Extensive experiments demonstrate that our framework achieves significant improvements, reaching $27.2$ PQ, $17.0$ mAP, and $35.3$ mIoU on A-150. It further attains $56.2$, $28.2$, $15.4$, $59.2$, $18.7$, and $95.8$ mIoU on Cityscapes, Mapillary Vistas, A-847, PC-59, PC-459, and PAS-20, respectively. In addition, our framework supports vocabulary-free segmentation, offering enhanced flexibility in recognizing unseen categories. Code will be public.
Pseudo-Label Quality Decoupling and Correction for Semi-Supervised Instance Segmentation
May 16, 2025Semi-Supervised Instance Segmentation (SSIS) involves classifying and grouping image pixels into distinct object instances using limited labeled data. This learning paradigm usually faces a significant challenge of unstable performance caused by noisy pseudo-labels of instance categories and pixel masks. We find that the prevalent practice of filtering instance pseudo-labels assessing both class and mask quality with a single score threshold, frequently leads to compromises in the trade-off between the qualities of class and mask labels. In this paper, we introduce a novel Pseudo-Label Quality Decoupling and Correction (PL-DC) framework for SSIS to tackle the above challenges. Firstly, at the instance level, a decoupled dual-threshold filtering mechanism is designed to decouple class and mask quality estimations for instance-level pseudo-labels, thereby independently controlling pixel classifying and grouping qualities. Secondly, at the category level, we introduce a dynamic instance category correction module to dynamically correct the pseudo-labels of instance categories, effectively alleviating category confusion. Lastly, we introduce a pixel-level mask uncertainty-aware mechanism at the pixel level to re-weight the mask loss for different pixels, thereby reducing the impact of noise introduced by pixel-level mask pseudo-labels. Extensive experiments on the COCO and Cityscapes datasets demonstrate that the proposed PL-DC achieves significant performance improvements, setting new state-of-the-art results for SSIS. Notably, our PL-DC shows substantial gains even with minimal labeled data, achieving an improvement of +11.6 mAP with just 1% COCO labeled data and +15.5 mAP with 5% Cityscapes labeled data. The code will be public.
S$^2$Teacher: Step-by-step Teacher for Sparsely Annotated Oriented Object Detection
Apr 15, 2025



Although fully-supervised oriented object detection has made significant progress in multimodal remote sensing image understanding, it comes at the cost of labor-intensive annotation. Recent studies have explored weakly and semi-supervised learning to alleviate this burden. However, these methods overlook the difficulties posed by dense annotations in complex remote sensing scenes. In this paper, we introduce a novel setting called sparsely annotated oriented object detection (SAOOD), which only labels partial instances, and propose a solution to address its challenges. Specifically, we focus on two key issues in the setting: (1) sparse labeling leading to overfitting on limited foreground representations, and (2) unlabeled objects (false negatives) confusing feature learning. To this end, we propose the S$^2$Teacher, a novel method that progressively mines pseudo-labels for unlabeled objects, from easy to hard, to enhance foreground representations. Additionally, it reweights the loss of unlabeled objects to mitigate their impact during training. Extensive experiments demonstrate that S$^2$Teacher not only significantly improves detector performance across different sparse annotation levels but also achieves near-fully-supervised performance on the DOTA dataset with only 10% annotation instances, effectively balancing detection accuracy with annotation efficiency. The code will be public.
AnomalyPainter: Vision-Language-Diffusion Synergy for Zero-Shot Realistic and Diverse Industrial Anomaly Synthesis
Mar 11, 2025While existing anomaly synthesis methods have made remarkable progress, achieving both realism and diversity in synthesis remains a major obstacle. To address this, we propose AnomalyPainter, a zero-shot framework that breaks the diversity-realism trade-off dilemma through synergizing Vision Language Large Model (VLLM), Latent Diffusion Model (LDM), and our newly introduced texture library Tex-9K. Tex-9K is a professional texture library containing 75 categories and 8,792 texture assets crafted for diverse anomaly synthesis. Leveraging VLLM's general knowledge, reasonable anomaly text descriptions are generated for each industrial object and matched with relevant diverse textures from Tex-9K. These textures then guide the LDM via ControlNet to paint on normal images. Furthermore, we introduce Texture-Aware Latent Init to stabilize the natural-image-trained ControlNet for industrial images. Extensive experiments show that AnomalyPainter outperforms existing methods in realism, diversity, and generalization, achieving superior downstream performance.
Exploring Semantic Consistency and Style Diversity for Domain Generalized Semantic Segmentation
Dec 16, 2024



Domain Generalized Semantic Segmentation (DGSS) seeks to utilize source domain data exclusively to enhance the generalization of semantic segmentation across unknown target domains. Prevailing studies predominantly concentrate on feature normalization and domain randomization, these approaches exhibit significant limitations. Feature normalization-based methods tend to confuse semantic features in the process of constraining the feature space distribution, resulting in classification misjudgment. Domain randomization-based methods frequently incorporate domain-irrelevant noise due to the uncontrollability of style transformations, resulting in segmentation ambiguity. To address these challenges, we introduce a novel framework, named SCSD for Semantic Consistency prediction and Style Diversity generalization. It comprises three pivotal components: Firstly, a Semantic Query Booster is designed to enhance the semantic awareness and discrimination capabilities of object queries in the mask decoder, enabling cross-domain semantic consistency prediction. Secondly, we develop a Text-Driven Style Transform module that utilizes domain difference text embeddings to controllably guide the style transformation of image features, thereby increasing inter-domain style diversity. Lastly, to prevent the collapse of similar domain feature spaces, we introduce a Style Synergy Optimization mechanism that fortifies the separation of inter-domain features and the aggregation of intra-domain features by synergistically weighting style contrastive loss and style aggregation loss. Extensive experiments demonstrate that the proposed SCSD significantly outperforms existing state-of-theart methods. Notably, SCSD trained on GTAV achieved an average of 49.11 mIoU on the four unseen domain datasets, surpassing the previous state-of-the-art method by +4.08 mIoU. Code is available at https://github.com/nhw649/SCSD.
EOV-Seg: Efficient Open-Vocabulary Panoptic Segmentation
Dec 11, 2024



Open-vocabulary panoptic segmentation aims to segment and classify everything in diverse scenes across an unbounded vocabulary. Existing methods typically employ two-stage or single-stage framework. The two-stage framework involves cropping the image multiple times using masks generated by a mask generator, followed by feature extraction, while the single-stage framework relies on a heavyweight mask decoder to make up for the lack of spatial position information through self-attention and cross-attention in multiple stacked Transformer blocks. Both methods incur substantial computational overhead, thereby hindering the efficiency of model inference. To fill the gap in efficiency, we propose EOV-Seg, a novel single-stage, shared, efficient, and spatial-aware framework designed for open-vocabulary panoptic segmentation. Specifically, EOV-Seg innovates in two aspects. First, a Vocabulary-Aware Selection (VAS) module is proposed to improve the semantic comprehension of visual aggregated features and alleviate the feature interaction burden on the mask decoder. Second, we introduce a Two-way Dynamic Embedding Experts (TDEE), which efficiently utilizes the spatial awareness capabilities of ViT-based CLIP backbone. To the best of our knowledge, EOV-Seg is the first open-vocabulary panoptic segmentation framework towards efficiency, which runs faster and achieves competitive performance compared with state-of-the-art methods. Specifically, with COCO training only, EOV-Seg achieves 24.2 PQ, 31.6 mIoU, and 12.7 FPS on the ADE20K dataset for panoptic and semantic segmentation tasks and the inference time of EOV-Seg is 4-21 times faster than state-of-the-art methods. Especially, equipped with ResNet-50 backbone, EOV-Seg runs 25 FPS with only 71M parameters on a single RTX 3090 GPU. Code is available at \url{https://github.com/nhw649/EOV-Seg}.
HUWSOD: Holistic Self-training for Unified Weakly Supervised Object Detection
Jun 27, 2024

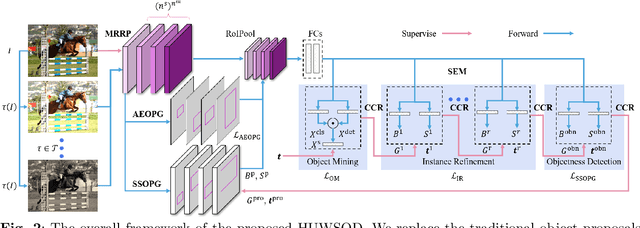

Most WSOD methods rely on traditional object proposals to generate candidate regions and are confronted with unstable training, which easily gets stuck in a poor local optimum. In this paper, we introduce a unified, high-capacity weakly supervised object detection (WSOD) network called HUWSOD, which utilizes a comprehensive self-training framework without needing external modules or additional supervision. HUWSOD innovatively incorporates a self-supervised proposal generator and an autoencoder proposal generator with a multi-rate resampling pyramid to replace traditional object proposals, enabling end-to-end WSOD training and inference. Additionally, we implement a holistic self-training scheme that refines detection scores and coordinates through step-wise entropy minimization and consistency-constraint regularization, ensuring consistent predictions across stochastic augmentations of the same image. Extensive experiments on PASCAL VOC and MS COCO demonstrate that HUWSOD competes with state-of-the-art WSOD methods, eliminating the need for offline proposals and additional data. The peak performance of HUWSOD approaches that of fully-supervised Faster R-CNN. Our findings also indicate that randomly initialized boxes, although significantly different from well-designed offline object proposals, are effective for WSOD training.