 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAR3D: A Unified 3D-MLLM with Part-Aware Representation for Scene Understanding
Jun 04, 2026Recent advances in 3D multimodal large language models (3D-MLLMs) have enabled unified solutions for 3D scene understanding tasks, including visual question answering, captioning, and referring segmentation. However, existing 3D-MLLMs remain largely object-centric, limiting their ability to model fine-grained part structures that are essential for embodied interaction with 3D environments. In this work, we present PAR3D, a unified part-aware 3D-MLLM framework that enables models to understand, reason about, and ground both objects and their parts in 3D scenes. To enable training and evaluation of part-aware 3D scene understanding, we introduce ScenePart, a synthetic 3D scene dataset with part-level annotations and language instructions. We further develop Part-Aware 3D Representation Learning to enrich 3D visual representations with fine-grained part-level semantics, and propose Hierarchical Segmentation Query Generation to ground part targets via hierarchical object-part queries. Extensive experiments show that our method substantially improves part-level question answering and referring segmentation, while also achieving strong performance across object-level vision-language tasks.
Smart-Insertion-V: Photorealistic Video Insertion via a Closed-Loop Feedback Dual-Stream Framework
May 22, 2026Mask-free video object insertion has emerged as a challenging task, requiring harmonious integration of reference objects into source videos. However, existing methods struggle when references exhibit severe stylistic domain gaps with the source scene. To overcome this, we propose \textit{\textbf{Smart-Insertion-V}}, an end-to-end \textbf{Dual-Stream} framework that concurrently conducts video insertion and image style transfer. Within this framework, the image stream synchronously guides the video generation process, while a \textbf{Closed-loop Feedback} mechanism is further incorporated to ensure robust insertion. Inevitably, integrating these diverse conditioning signals results in feature entanglement and style leakage. To tackle this issue, we design \textbf{Dual-World-View RoPE} to distinguish different signals via spatial-temporal offsets without incurring heavy training overhead. Furthermore, to facilitate spatial grounding and stylistic adaptation, we introduce a \textbf{Decoupled Guidance Module} that leverages a Vision-Language Model for semantic reasoning while preserving original temporal guidance with native text encoder. To bridge data gap for harmonious reference insertion task, we propose a data curation pipeline and will release an \textbf{open-source dataset}. Experiments demonstrate that our method can insert objects into plausible positions while achieving the most harmonious results.
StereoVGGT: A Training-Free Visual Geometry Transformer for Stereo Vision
Mar 31, 2026Driven by the advancement of 3D devices, stereo vision tasks including stereo matching and stereo conversion have emerged as a critical research frontier. Contemporary stereo vision backbones typically rely on either monocular depth estimation (MDE) models or visual foundation models (VFMs). Crucially, these models are predominantly pretrained without explicit supervision of camera poses. Given that such geometric knowledge is indispensable for stereo vision, the absence of explicit spatial constraints constitutes a significant performance bottleneck for existing architectures. Recognizing that the Visual Geometry Grounded Transformer (VGGT) operates as a foundation model pretrained on extensive 3D priors, including camera poses, we investigate its potential as a robust backbone for stereo vision tasks. Nevertheless, empirical results indicate that its direct application to stereo vision yields suboptimal performance. We observe that VGGT suffers from a more significant degradation of geometric details during feature extraction. Such characteristics conflict with the requirements of binocular stereo vision, thereby constraining its efficacy for relative tasks. To bridge this gap, we propose StereoVGGT, a feature backbone specifically tailored for stereo vision. By leveraging the frozen VGGT and introducing a training-free feature adjustment pipeline, we mitigate geometric degradation and harness the latent camera calibration knowledge embedded within the model. StereoVGGT-based stereo matching network achieved the $1^{st}$ rank among all published methods on the KITTI benchmark, validating that StereoVGGT serves as a highly effective backbone for stereo vision.
DriveVLM-RL: Neuroscience-Inspired Reinforcement Learning with Vision-Language Models for Safe and Deployable Autonomous Driving
Mar 18, 2026Ensuring safe decision-making in autonomous vehicles remains a fundamental challenge despite rapid advances in end-to-end learning approaches. Traditional reinforcement learning (RL) methods rely on manually engineered rewards or sparse collision signals, which fail to capture the rich contextual understanding required for safe driving and make unsafe exploration unavoidable in real-world settings. Recent vision-language models (VLMs) offer promising semantic understanding capabilities; however, their high inference latency and susceptibility to hallucination hinder direct application to real-time vehicle control. To address these limitations, this paper proposes DriveVLM-RL, a neuroscience-inspired framework that integrates VLMs into RL through a dual-pathway architecture for safe and deployable autonomous driving. The framework decomposes semantic reward learning into a Static Pathway for continuous spatial safety assessment using CLIP-based contrasting language goals, and a Dynamic Pathway for attention-gated multi-frame semantic risk reasoning using a lightweight detector and a large VLM. A hierarchical reward synthesis mechanism fuses semantic signals with vehicle states, while an asynchronous training pipeline decouples expensive VLM inference from environment interaction. All VLM components are used only during offline training and are removed at deployment, ensuring real-time feasibility. Experiments in the CARLA simulator show significant improvements in collision avoidance, task success, and generalization across diverse traffic scenarios, including strong robustness under settings without explicit collision penalties. These results demonstrate that DriveVLM-RL provides a practical paradigm for integrating foundation models into autonomous driving without compromising real-time feasibility. Demo video and code are available at: https://zilin-huang.github.io/DriveVLM-RL-website/
Found-RL: foundation model-enhanced reinforcement learning for autonomous driving
Feb 11, 2026Reinforcement Learning (RL) has emerged as a dominant paradigm for end-to-end autonomous driving (AD). However, RL suffers from sample inefficiency and a lack of semantic interpretability in complex scenarios. Foundation Models, particularly Vision-Language Models (VLMs), can mitigate this by offering rich, context-aware knowledge, yet their high inference latency hinders deployment in high-frequency RL training loops. To bridge this gap, we present Found-RL, a platform tailored to efficiently enhance RL for AD using foundation models. A core innovation is the asynchronous batch inference framework, which decouples heavy VLM reasoning from the simulation loop, effectively resolving latency bottlenecks to support real-time learning. We introduce diverse supervision mechanisms: Value-Margin Regularization (VMR) and Advantage-Weighted Action Guidance (AWAG) to effectively distill expert-like VLM action suggestions into the RL policy. Additionally, we adopt high-throughput CLIP for dense reward shaping. We address CLIP's dynamic blindness via Conditional Contrastive Action Alignment, which conditions prompts on discretized speed/command and yields a normalized, margin-based bonus from context-specific action-anchor scoring. Found-RL provides an end-to-end pipeline for fine-tuned VLM integration and shows that a lightweight RL model can achieve near-VLM performance compared with billion-parameter VLMs while sustaining real-time inference (approx. 500 FPS). Code, data, and models will be publicly available at https://github.com/ys-qu/found-rl.
XSpecMesh: Quality-Preserving Auto-Regressive Mesh Generation Acceleration via Multi-Head Speculative Decoding
Jul 31, 2025Current auto-regressive models can generate high-quality, topologically precise meshes; however, they necessitate thousands-or even tens of thousands-of next-token predictions during inference, resulting in substantial latency. We introduce XSpecMesh, a quality-preserving acceleration method for auto-regressive mesh generation models. XSpecMesh employs a lightweight, multi-head speculative decoding scheme to predict multiple tokens in parallel within a single forward pass, thereby accelerating inference. We further propose a verification and resampling strategy: the backbone model verifies each predicted token and resamples any tokens that do not meet the quality criteria. In addition, we propose a distillation strategy that trains the lightweight decoding heads by distilling from the backbone model, encouraging their prediction distributions to align and improving the success rate of speculative predictions. Extensive experiments demonstrate that our method achieves a 1.7x speedup without sacrificing generation quality. Our code will be released.
DeOcc-1-to-3: 3D De-Occlusion from a Single Image via Self-Supervised Multi-View Diffusion
Jun 26, 2025Reconstructing 3D objects from a single image is a long-standing challenge, especially under real-world occlusions. While recent diffusion-based view synthesis models can generate consistent novel views from a single RGB image, they generally assume fully visible inputs and fail when parts of the object are occluded. This leads to inconsistent views and degraded 3D reconstruction quality. To overcome this limitation, we propose an end-to-end framework for occlusion-aware multi-view generation. Our method directly synthesizes six structurally consistent novel views from a single partially occluded image, enabling downstream 3D reconstruction without requiring prior inpainting or manual annotations. We construct a self-supervised training pipeline using the Pix2Gestalt dataset, leveraging occluded-unoccluded image pairs and pseudo-ground-truth views to teach the model structure-aware completion and view consistency. Without modifying the original architecture, we fully fine-tune the view synthesis model to jointly learn completion and multi-view generation. Additionally, we introduce the first benchmark for occlusion-aware reconstruction, encompassing diverse occlusion levels, object categories, and mask patterns. This benchmark provides a standardized protocol for evaluating future methods under partial occlusions. Our code is available at https://github.com/Quyans/DeOcc123.
VL-SAFE: Vision-Language Guided Safety-Aware Reinforcement Learning with World Models for Autonomous Driving
May 22, 2025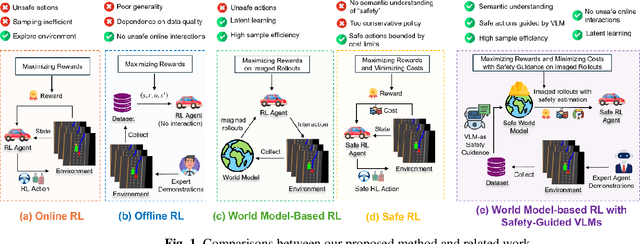
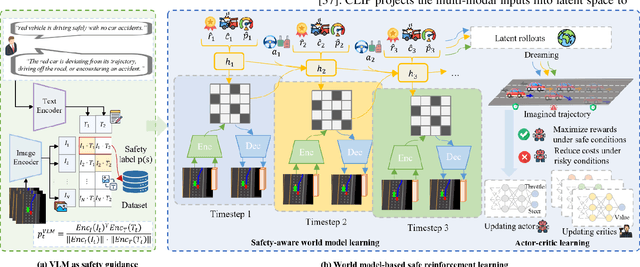
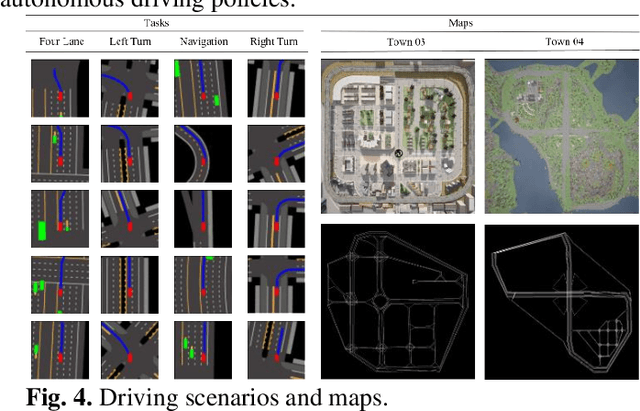
Reinforcement learning (RL)-based autonomous driving policy learning faces critical limitations such as low sample efficiency and poor generalization; its reliance on online interactions and trial-and-error learning is especially unacceptable in safety-critical scenarios. Existing methods including safe RL often fail to capture the true semantic meaning of "safety" in complex driving contexts, leading to either overly conservative driving behavior or constraint violations. To address these challenges, we propose VL-SAFE, a world model-based safe RL framework with Vision-Language model (VLM)-as-safety-guidance paradigm, designed for offline safe policy learning. Specifically, we construct offline datasets containing data collected by expert agents and labeled with safety scores derived from VLMs. A world model is trained to generate imagined rollouts together with safety estimations, allowing the agent to perform safe planning without interacting with the real environment. Based on these imagined trajectories and safety evaluations, actor-critic learning is conducted under VLM-based safety guidance to optimize the driving policy more safely and efficiently. Extensive evaluations demonstrate that VL-SAFE achieves superior sample efficiency, generalization, safety, and overall performance compared to existing baselines. To the best of our knowledge, this is the first work that introduces a VLM-guided world model-based approach for safe autonomous driving. The demo video and code can be accessed at: https://ys-qu.github.io/vlsafe-website/
SynergyAmodal: Deocclude Anything with Text Control
Apr 28, 2025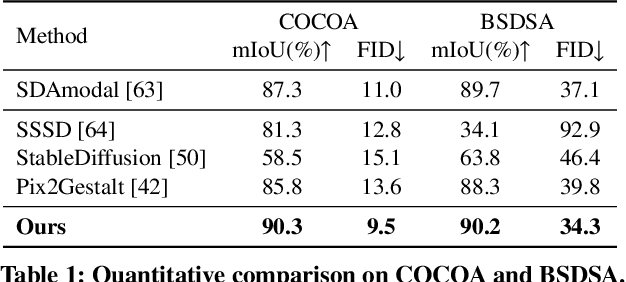

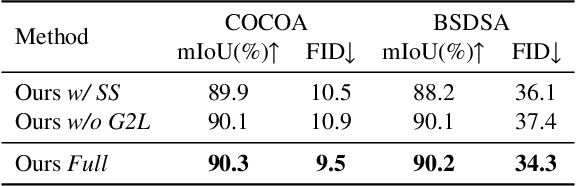
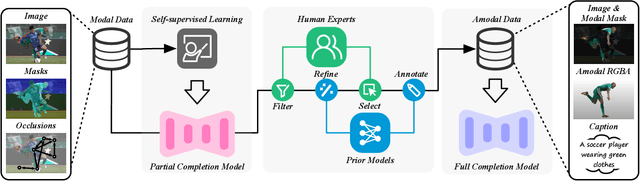
Image deocclusion (or amodal completion) aims to recover the invisible regions (\ie, shape and appearance) of occluded instances in images. Despite recent advances, the scarcity of high-quality data that balances diversity, plausibility, and fidelity remains a major obstacle. To address this challenge, we identify three critical elements: leveraging in-the-wild image data for diversity, incorporating human expertise for plausibility, and utilizing generative priors for fidelity. We propose SynergyAmodal, a novel framework for co-synthesizing in-the-wild amodal datasets with comprehensive shape and appearance annotations, which integrates these elements through a tripartite data-human-model collaboration. First, we design an occlusion-grounded self-supervised learning algorithm to harness the diversity of in-the-wild image data, fine-tuning an inpainting diffusion model into a partial completion diffusion model. Second, we establish a co-synthesis pipeline to iteratively filter, refine, select, and annotate the initial deocclusion results of the partial completion diffusion model, ensuring plausibility and fidelity through human expert guidance and prior model constraints. This pipeline generates a high-quality paired amodal dataset with extensive category and scale diversity, comprising approximately 16K pairs. Finally, we train a full completion diffusion model on the synthesized dataset, incorporating text prompts as conditioning signals. Extensive experiments demonstrate the effectiveness of our framework in achieving zero-shot generalization and textual controllability. Our code, dataset, and models will be made publicly available at https://github.com/imlixinyang/SynergyAmodal.
Sky-Drive: A Distributed Multi-Agent Simulation Platform for Socially-Aware and Human-AI Collaborative Future Transportation
Apr 25, 2025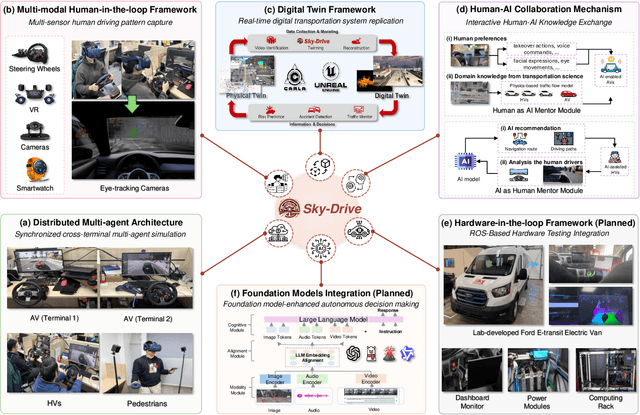
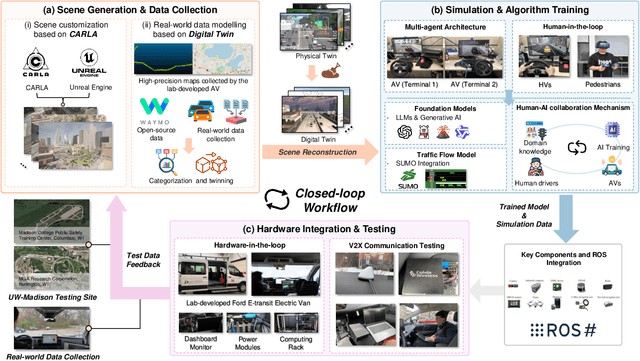
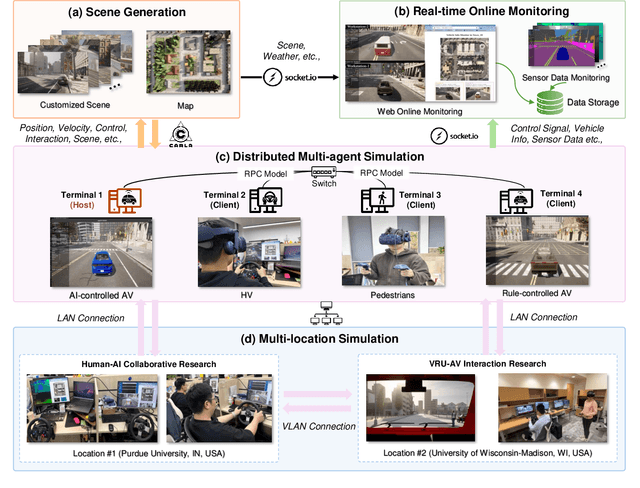
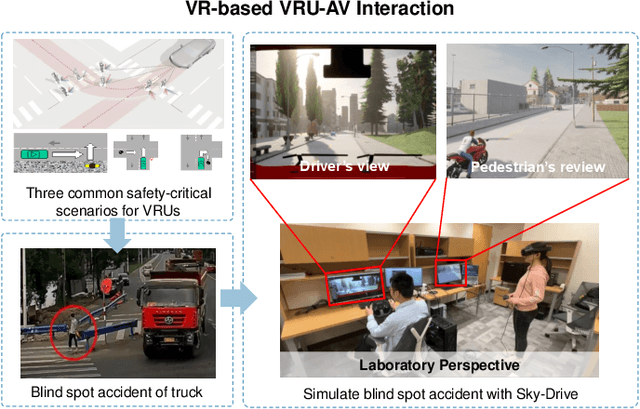
Recent advances in autonomous system simulation platforms have significantly enhanced the safe and scalable testing of driving policies. However, existing simulators do not yet fully meet the needs of future transportation research, particularly in modeling socially-aware driving agents and enabling effective human-AI collaboration. This paper introduces Sky-Drive, a novel distributed multi-agent simulation platform that addresses these limitations through four key innovations: (a) a distributed architecture for synchronized simulation across multiple terminals; (b) a multi-modal human-in-the-loop framework integrating diverse sensors to collect rich behavioral data; (c) a human-AI collaboration mechanism supporting continuous and adaptive knowledge exchange; and (d) a digital twin (DT) framework for constructing high-fidelity virtual replicas of real-world transportation environments. Sky-Drive supports diverse applications such as autonomous vehicle (AV)-vulnerable road user (VRU) interaction modeling, human-in-the-loop training, socially-aware reinforcement learning, personalized driving policy, and customized scenario generation. Future extensions will incorporate foundation models for context-aware decision support and hardware-in-the-loop (HIL) testing for real-world validation. By bridging scenario generation, data collection, algorithm training, and hardware integration, Sky-Drive has the potential to become a foundational platform for the next generation of socially-aware and human-centered autonomous transportation research. The demo video and code are available at:https://sky-lab-uw.github.io/Sky-Drive-website/