 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurricuVLM: Towards Safe Autonomous Driving via Personalized Safety-Critical Curriculum Learning with Vision-Language Models
Paper and Code
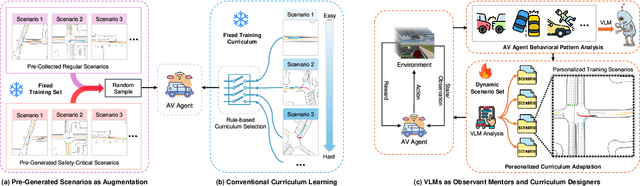
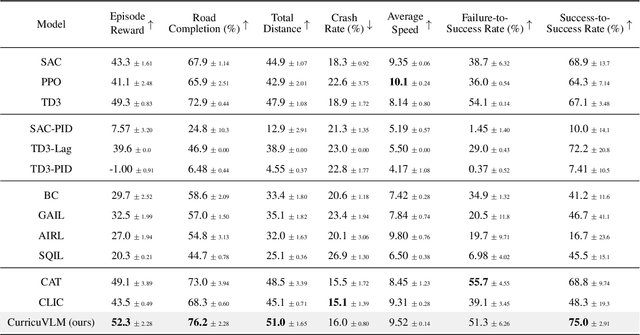
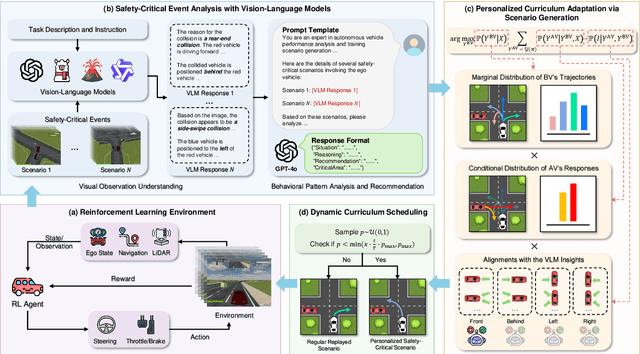
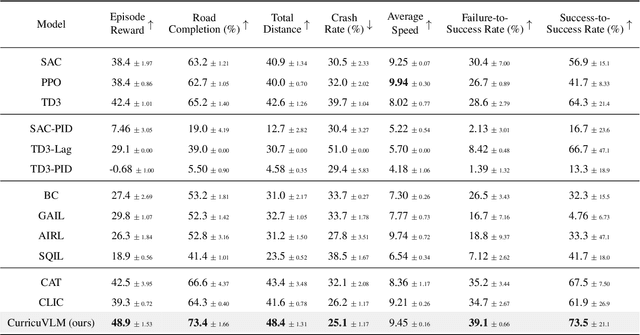
Ensuring safety in autonomous driving systems remains a critical challenge, particularly in handling rare but potentially catastrophic safety-critical scenarios. While existing research has explored generating safety-critical scenarios for autonomous vehicle (AV) testing, there is limited work on effectively incorporating these scenarios into policy learning to enhance safety. Furthermore, developing training curricula that adapt to an AV's evolving behavioral patterns and performance bottlenecks remains largely unexplored. To address these challenges, we propose CurricuVLM, a novel framework that leverages Vision-Language Models (VLMs) to enable personalized curriculum learning for autonomous driving agents. Our approach uniquely exploits VLMs' multimodal understanding capabilities to analyze agent behavior, identify performance weaknesses, and dynamically generate tailored training scenarios for curriculum adaptation. Through comprehensive analysis of unsafe driving situations with narrative descriptions, CurricuVLM performs in-depth reasoning to evaluate the AV's capabilities and identify critical behavioral patterns. The framework then synthesizes customized training scenarios targeting these identified limitations, enabling effective and personalized curriculum learning. Extensive experiments on the Waymo Open Motion Dataset show that CurricuVLM outperforms state-of-the-art baselines across both regular and safety-critical scenarios, achieving superior performance in terms of navigation success, driving efficiency, and safety metrics. Further analysis reveals that CurricuVLM serves as a general approach that can be integrated with various RL algorithms to enhance autonomous driving systems. The code and demo video are available at: https://zihaosheng.github.io/CurricuVLM/.