 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHERMES: A Holistic End-to-End Risk-Aware Multimodal Embodied System with Vision-Language Models for Long-Tail Autonomous Driving
Feb 01, 2026End-to-end autonomous driving models increasingly benefit from large vision--language models for semantic understanding, yet ensuring safe and accurate operation under long-tail conditions remains challenging. These challenges are particularly prominent in long-tail mixed-traffic scenarios, where autonomous vehicles must interact with heterogeneous road users, including human-driven vehicles and vulnerable road users, under complex and uncertain conditions. This paper proposes HERMES, a holistic risk-aware end-to-end multimodal driving framework designed to inject explicit long-tail risk cues into trajectory planning. HERMES employs a foundation-model-assisted annotation pipeline to produce structured Long-Tail Scene Context and Long-Tail Planning Context, capturing hazard-centric cues together with maneuver intent and safety preference, and uses these signals to guide end-to-end planning. HERMES further introduces a Tri-Modal Driving Module that fuses multi-view perception, historical motion cues, and semantic guidance, ensuring risk-aware accurate trajectory planning under long-tail scenarios. Experiments on the real-world long-tail dataset demonstrate that HERMES consistently outperforms representative end-to-end and VLM-driven baselines under long-tail mixed-traffic scenarios. Ablation studies verify the complementary contributions of key components.
V2X-REALM: Vision-Language Model-Based Robust End-to-End Cooperative Autonomous Driving with Adaptive Long-Tail Modeling
Jun 26, 2025Ensuring robust planning and decision-making under rare, diverse, and visually degraded long-tail scenarios remains a fundamental challenge for autonomous driving in urban environments. This issue becomes more critical in cooperative settings, where vehicles and infrastructure jointly perceive and reason across complex environments. To address this challenge, we propose V2X-REALM, a vision-language model (VLM)-based framework with adaptive multimodal learning for robust cooperative autonomous driving under long-tail scenarios. V2X-REALM introduces three core innovations: (i) a prompt-driven long-tail scenario generation and evaluation pipeline that leverages foundation models to synthesize realistic long-tail conditions such as snow and fog across vehicle- and infrastructure-side views, enriching training diversity efficiently; (ii) a gated multi-scenario adaptive attention module that modulates the visual stream using scenario priors to recalibrate ambiguous or corrupted features; and (iii) a multi-task scenario-aware contrastive learning objective that improves multimodal alignment and promotes cross-scenario feature separability. Extensive experiments demonstrate that V2X-REALM significantly outperforms existing baselines in robustness, semantic reasoning, safety, and planning accuracy under complex, challenging driving conditions, advancing the scalability of end-to-end cooperative autonomous driving.
VL-SAFE: Vision-Language Guided Safety-Aware Reinforcement Learning with World Models for Autonomous Driving
May 22, 2025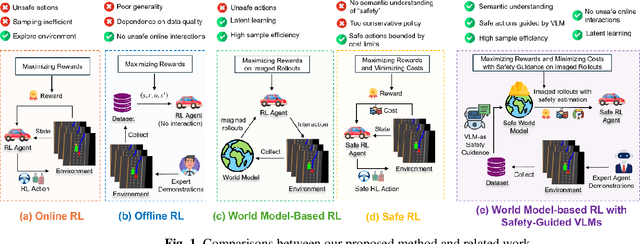
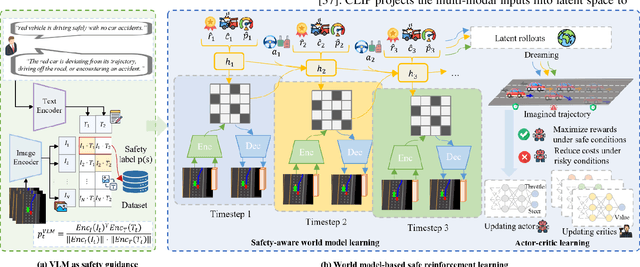
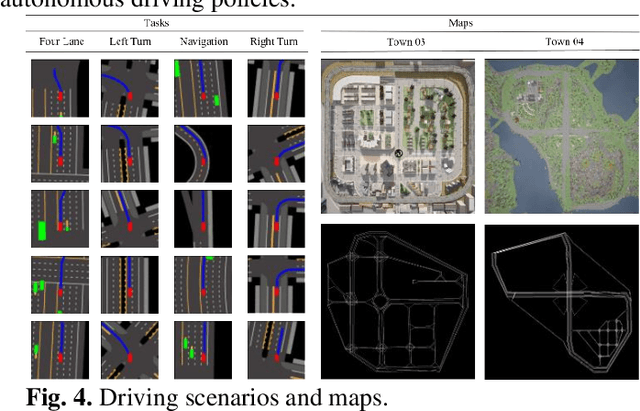
Reinforcement learning (RL)-based autonomous driving policy learning faces critical limitations such as low sample efficiency and poor generalization; its reliance on online interactions and trial-and-error learning is especially unacceptable in safety-critical scenarios. Existing methods including safe RL often fail to capture the true semantic meaning of "safety" in complex driving contexts, leading to either overly conservative driving behavior or constraint violations. To address these challenges, we propose VL-SAFE, a world model-based safe RL framework with Vision-Language model (VLM)-as-safety-guidance paradigm, designed for offline safe policy learning. Specifically, we construct offline datasets containing data collected by expert agents and labeled with safety scores derived from VLMs. A world model is trained to generate imagined rollouts together with safety estimations, allowing the agent to perform safe planning without interacting with the real environment. Based on these imagined trajectories and safety evaluations, actor-critic learning is conducted under VLM-based safety guidance to optimize the driving policy more safely and efficiently. Extensive evaluations demonstrate that VL-SAFE achieves superior sample efficiency, generalization, safety, and overall performance compared to existing baselines. To the best of our knowledge, this is the first work that introduces a VLM-guided world model-based approach for safe autonomous driving. The demo video and code can be accessed at: https://ys-qu.github.io/vlsafe-website/
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
Sky-Drive: A Distributed Multi-Agent Simulation Platform for Socially-Aware and Human-AI Collaborative Future Transportation
Apr 25, 2025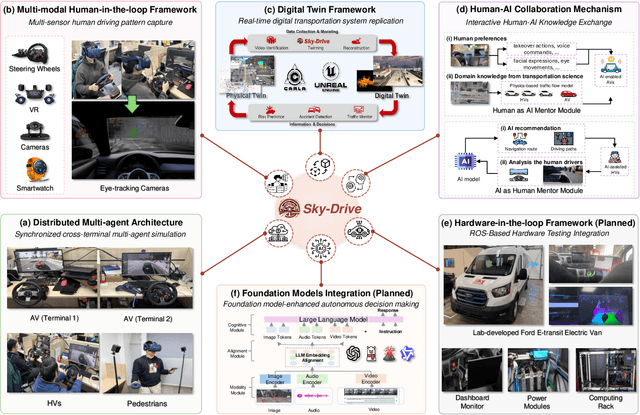
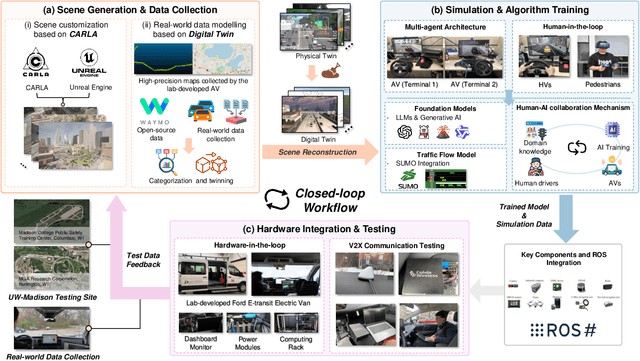
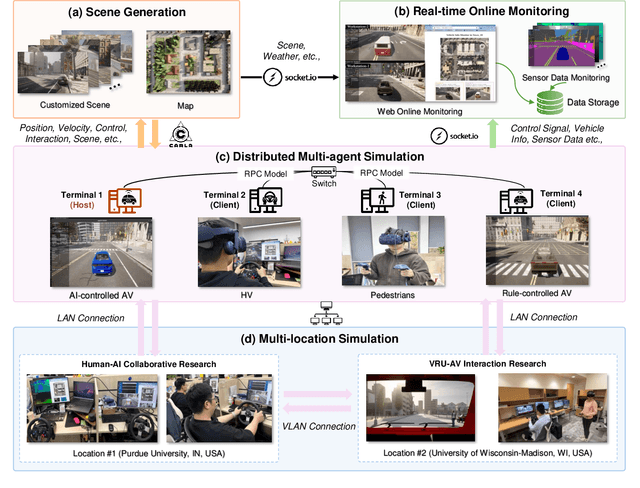
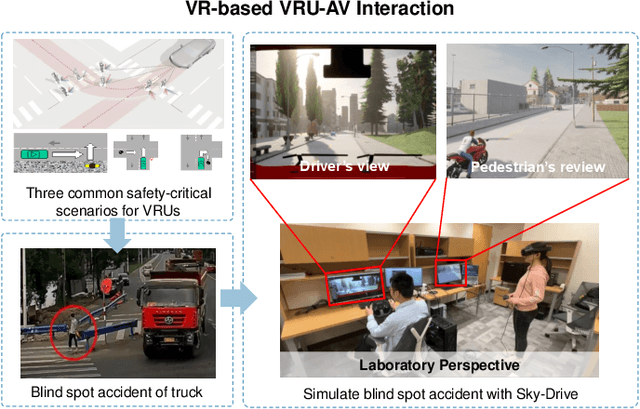
Recent advances in autonomous system simulation platforms have significantly enhanced the safe and scalable testing of driving policies. However, existing simulators do not yet fully meet the needs of future transportation research, particularly in modeling socially-aware driving agents and enabling effective human-AI collaboration. This paper introduces Sky-Drive, a novel distributed multi-agent simulation platform that addresses these limitations through four key innovations: (a) a distributed architecture for synchronized simulation across multiple terminals; (b) a multi-modal human-in-the-loop framework integrating diverse sensors to collect rich behavioral data; (c) a human-AI collaboration mechanism supporting continuous and adaptive knowledge exchange; and (d) a digital twin (DT) framework for constructing high-fidelity virtual replicas of real-world transportation environments. Sky-Drive supports diverse applications such as autonomous vehicle (AV)-vulnerable road user (VRU) interaction modeling, human-in-the-loop training, socially-aware reinforcement learning, personalized driving policy, and customized scenario generation. Future extensions will incorporate foundation models for context-aware decision support and hardware-in-the-loop (HIL) testing for real-world validation. By bridging scenario generation, data collection, algorithm training, and hardware integration, Sky-Drive has the potential to become a foundational platform for the next generation of socially-aware and human-centered autonomous transportation research. The demo video and code are available at:https://sky-lab-uw.github.io/Sky-Drive-website/
FASIONAD++ : Integrating High-Level Instruction and Information Bottleneck in FAt-Slow fusION Systems for Enhanced Safety in Autonomous Driving with Adaptive Feedback
Mar 11, 2025



Ensuring safe, comfortable, and efficient planning is crucial for autonomous driving systems. While end-to-end models trained on large datasets perform well in standard driving scenarios, they struggle with complex low-frequency events. Recent Large Language Models (LLMs) and Vision Language Models (VLMs) advancements offer enhanced reasoning but suffer from computational inefficiency. Inspired by the dual-process cognitive model "Thinking, Fast and Slow", we propose $\textbf{FASIONAD}$ -- a novel dual-system framework that synergizes a fast end-to-end planner with a VLM-based reasoning module. The fast system leverages end-to-end learning to achieve real-time trajectory generation in common scenarios, while the slow system activates through uncertainty estimation to perform contextual analysis and complex scenario resolution. Our architecture introduces three key innovations: (1) A dynamic switching mechanism enabling slow system intervention based on real-time uncertainty assessment; (2) An information bottleneck with high-level plan feedback that optimizes the slow system's guidance capability; (3) A bidirectional knowledge exchange where visual prompts enhance the slow system's reasoning while its feedback refines the fast planner's decision-making. To strengthen VLM reasoning, we develop a question-answering mechanism coupled with reward-instruct training strategy. In open-loop experiments, FASIONAD achieves a $6.7\%$ reduction in average $L2$ trajectory error and $28.1\%$ lower collision rate.
CurricuVLM: Towards Safe Autonomous Driving via Personalized Safety-Critical Curriculum Learning with Vision-Language Models
Feb 21, 2025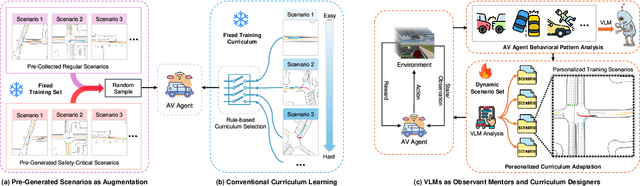
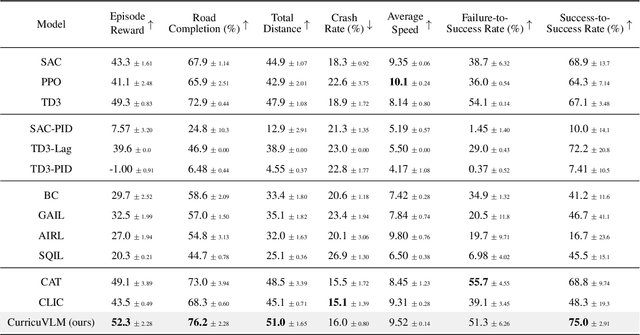
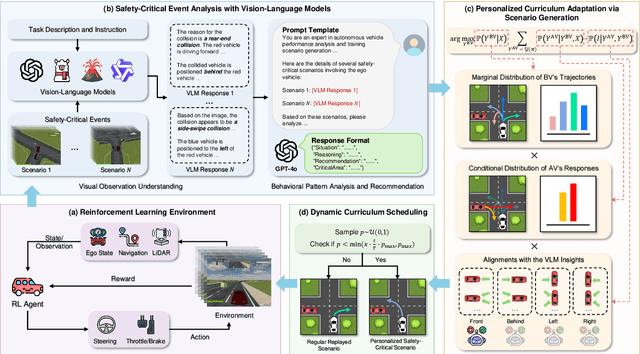
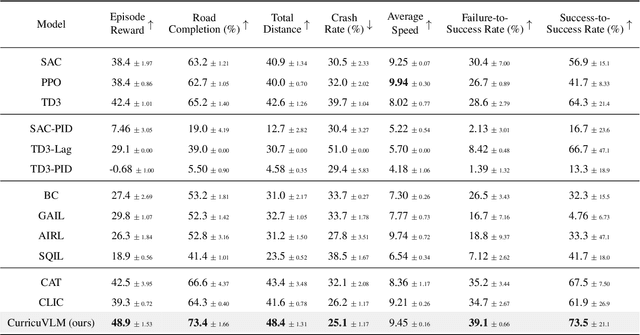
Ensuring safety in autonomous driving systems remains a critical challenge, particularly in handling rare but potentially catastrophic safety-critical scenarios. While existing research has explored generating safety-critical scenarios for autonomous vehicle (AV) testing, there is limited work on effectively incorporating these scenarios into policy learning to enhance safety. Furthermore, developing training curricula that adapt to an AV's evolving behavioral patterns and performance bottlenecks remains largely unexplored. To address these challenges, we propose CurricuVLM, a novel framework that leverages Vision-Language Models (VLMs) to enable personalized curriculum learning for autonomous driving agents. Our approach uniquely exploits VLMs' multimodal understanding capabilities to analyze agent behavior, identify performance weaknesses, and dynamically generate tailored training scenarios for curriculum adaptation. Through comprehensive analysis of unsafe driving situations with narrative descriptions, CurricuVLM performs in-depth reasoning to evaluate the AV's capabilities and identify critical behavioral patterns. The framework then synthesizes customized training scenarios targeting these identified limitations, enabling effective and personalized curriculum learning. Extensive experiments on the Waymo Open Motion Dataset show that CurricuVLM outperforms state-of-the-art baselines across both regular and safety-critical scenarios, achieving superior performance in terms of navigation success, driving efficiency, and safety metrics. Further analysis reveals that CurricuVLM serves as a general approach that can be integrated with various RL algorithms to enhance autonomous driving systems. The code and demo video are available at: https://zihaosheng.github.io/CurricuVLM/.
VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving
Dec 20, 2024



In recent years, reinforcement learning (RL)-based methods for learning driving policies have gained increasing attention in the autonomous driving community and have achieved remarkable progress in various driving scenarios. However, traditional RL approaches rely on manually engineered rewards, which require extensive human effort and often lack generalizability. To address these limitations, we propose \textbf{VLM-RL}, a unified framework that integrates pre-trained Vision-Language Models (VLMs) with RL to generate reward signals using image observation and natural language goals. The core of VLM-RL is the contrasting language goal (CLG)-as-reward paradigm, which uses positive and negative language goals to generate semantic rewards. We further introduce a hierarchical reward synthesis approach that combines CLG-based semantic rewards with vehicle state information, improving reward stability and offering a more comprehensive reward signal. Additionally, a batch-processing technique is employed to optimize computational efficiency during training. Extensive experiments in the CARLA simulator demonstrate that VLM-RL outperforms state-of-the-art baselines, achieving a 10.5\% reduction in collision rate, a 104.6\% increase in route completion rate, and robust generalization to unseen driving scenarios. Furthermore, VLM-RL can seamlessly integrate almost any standard RL algorithms, potentially revolutionizing the existing RL paradigm that relies on manual reward engineering and enabling continuous performance improvements. The demo video and code can be accessed at: https://zilin-huang.github.io/VLM-RL-website.
FollowGen: A Scaled Noise Conditional Diffusion Model for Car-Following Trajectory Prediction
Nov 23, 2024



Vehicle trajectory prediction is crucial for advancing autonomous driving and advanced driver assistance systems (ADAS). Although deep learning-based approaches - especially those utilizing transformer-based and generative models - have markedly improved prediction accuracy by capturing complex, non-linear patterns in vehicle dynamics and traffic interactions, they frequently overlook detailed car-following behaviors and the inter-vehicle interactions critical for real-world driving applications, particularly in fully autonomous or mixed traffic scenarios. To address the issue, this study introduces a scaled noise conditional diffusion model for car-following trajectory prediction, which integrates detailed inter-vehicular interactions and car-following dynamics into a generative framework, improving both the accuracy and plausibility of predicted trajectories. The model utilizes a novel pipeline to capture historical vehicle dynamics by scaling noise with encoded historical features within the diffusion process. Particularly, it employs a cross-attention-based transformer architecture to model intricate inter-vehicle dependencies, effectively guiding the denoising process and enhancing prediction accuracy. Experimental results on diverse real-world driving scenarios demonstrate the state-of-the-art performance and robustness of the proposed method.
Towards 3D Semantic Scene Completion for Autonomous Driving: A Meta-Learning Framework Empowered by Deformable Large-Kernel Attention and Mamba Model
Nov 06, 2024Semantic scene completion (SSC) is essential for achieving comprehensive perception in autonomous driving systems. However, existing SSC methods often overlook the high deployment costs in real-world applications. Traditional architectures, such as 3D Convolutional Neural Networks (3D CNNs) and self-attention mechanisms, face challenges in efficiently capturing long-range dependencies within 3D voxel grids, limiting their effectiveness. To address these issues, we introduce MetaSSC, a novel meta-learning-based framework for SSC that leverages deformable convolution, large-kernel attention, and the Mamba (D-LKA-M) model. Our approach begins with a voxel-based semantic segmentation (SS) pretraining task, aimed at exploring the semantics and geometry of incomplete regions while acquiring transferable meta-knowledge. Using simulated cooperative perception datasets, we supervise the perception training of a single vehicle using aggregated sensor data from multiple nearby connected autonomous vehicles (CAVs), generating richer and more comprehensive labels. This meta-knowledge is then adapted to the target domain through a dual-phase training strategy that does not add extra model parameters, enabling efficient deployment. To further enhance the model's capability in capturing long-sequence relationships within 3D voxel grids, we integrate Mamba blocks with deformable convolution and large-kernel attention into the backbone network. Extensive experiments demonstrate that MetaSSC achieves state-of-the-art performance, significantly outperforming competing models while also reducing deployment costs.