 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploreVLA: Dense World Modeling and Exploration for End-to-End Autonomous Driving
Apr 03, 2026End-to-end autonomous driving models based on Vision-Language-Action (VLA) architectures have shown promising results by learning driving policies through behavior cloning on expert demonstrations. However, imitation learning inherently limits the model to replicating observed behaviors without exploring diverse driving strategies, leaving it brittle in novel or out-of-distribution scenarios. Reinforcement learning (RL) offers a natural remedy by enabling policy exploration beyond the expert distribution. Yet VLA models, typically trained on offline datasets, lack directly observable state transitions, necessitating a learned world model to anticipate action consequences. In this work, we propose a unified understanding-and-generation framework that leverages world modeling to simultaneously enable meaningful exploration and provide dense supervision. Specifically, we augment trajectory prediction with future RGB and depth image generation as dense world modeling objectives, requiring the model to learn fine-grained visual and geometric representations that substantially enrich the planning backbone. Beyond serving as a supervisory signal, the world model further acts as a source of intrinsic reward for policy exploration: its image prediction uncertainty naturally measures a trajectory's novelty relative to the training distribution, where high uncertainty indicates out-of-distribution scenarios that, if safe, represent valuable learning opportunities. We incorporate this exploration signal into a safety-gated reward and optimize the policy via Group Relative Policy Optimization (GRPO). Experiments on the NAVSIM and nuScenes benchmarks demonstrate the effectiveness of our approach, achieving a state-of-the-art PDMS score of 93.7 and an EPDMS of 88.8 on NAVSIM. The code and demo will be publicly available at https://zihaosheng.github.io/ExploreVLA/.
Sim2Real-AD: A Modular Sim-to-Real Framework for Deploying VLM-Guided Reinforcement Learning in Real-World Autonomous Driving
Apr 03, 2026Deploying reinforcement learning policies trained in simulation to real autonomous vehicles remains a fundamental challenge, particularly for VLM-guided RL frameworks whose policies are typically learned with simulator-native observations and simulator-coupled action semantics that are unavailable on physical platforms. This paper presents Sim2Real-AD, a modular framework for zero-shot sim-to-real transfer of CARLA-trained VLM-guided RL policies to full-scale vehicles without any real-world RL training data. The framework decomposes the transfer problem into four components: a Geometric Observation Bridge (GOB) that converts monocular front-view images into simulator-compatible bird's-eye-view (BEV) observations, a Physics-Aware Action Mapping (PAM) that translates policy outputs into platform-agnostic physical commands, a Two-Phase Progressive Training (TPT) strategy that stabilizes adaptation by separating action-space and observation-space transfer, and a Real-time Deployment Pipeline (RDP) that integrates perception, policy inference, control conversion, and safety monitoring for closed-loop execution. Simulation experiments show that the framework preserves the relative performance ordering of representative RL algorithms across different reward paradigms and validate the contribution of each module. Zero-shot deployment on a full-scale Ford E-Transit achieves success rates of 90%, 80%, and 75% in car-following, obstacle avoidance, and stop-sign interaction scenarios, respectively. To the best of our knowledge, this study is among the first to demonstrate zero-shot closed-loop deployment of a CARLA-trained VLM-guided RL policy on a full-scale real vehicle without any real-world RL training data. The demo video and code are available at: https://zilin-huang.github.io/Sim2Real-AD-website/.
DriveVLM-RL: Neuroscience-Inspired Reinforcement Learning with Vision-Language Models for Safe and Deployable Autonomous Driving
Mar 18, 2026Ensuring safe decision-making in autonomous vehicles remains a fundamental challenge despite rapid advances in end-to-end learning approaches. Traditional reinforcement learning (RL) methods rely on manually engineered rewards or sparse collision signals, which fail to capture the rich contextual understanding required for safe driving and make unsafe exploration unavoidable in real-world settings. Recent vision-language models (VLMs) offer promising semantic understanding capabilities; however, their high inference latency and susceptibility to hallucination hinder direct application to real-time vehicle control. To address these limitations, this paper proposes DriveVLM-RL, a neuroscience-inspired framework that integrates VLMs into RL through a dual-pathway architecture for safe and deployable autonomous driving. The framework decomposes semantic reward learning into a Static Pathway for continuous spatial safety assessment using CLIP-based contrasting language goals, and a Dynamic Pathway for attention-gated multi-frame semantic risk reasoning using a lightweight detector and a large VLM. A hierarchical reward synthesis mechanism fuses semantic signals with vehicle states, while an asynchronous training pipeline decouples expensive VLM inference from environment interaction. All VLM components are used only during offline training and are removed at deployment, ensuring real-time feasibility. Experiments in the CARLA simulator show significant improvements in collision avoidance, task success, and generalization across diverse traffic scenarios, including strong robustness under settings without explicit collision penalties. These results demonstrate that DriveVLM-RL provides a practical paradigm for integrating foundation models into autonomous driving without compromising real-time feasibility. Demo video and code are available at: https://zilin-huang.github.io/DriveVLM-RL-website/
Found-RL: foundation model-enhanced reinforcement learning for autonomous driving
Feb 11, 2026Reinforcement Learning (RL) has emerged as a dominant paradigm for end-to-end autonomous driving (AD). However, RL suffers from sample inefficiency and a lack of semantic interpretability in complex scenarios. Foundation Models, particularly Vision-Language Models (VLMs), can mitigate this by offering rich, context-aware knowledge, yet their high inference latency hinders deployment in high-frequency RL training loops. To bridge this gap, we present Found-RL, a platform tailored to efficiently enhance RL for AD using foundation models. A core innovation is the asynchronous batch inference framework, which decouples heavy VLM reasoning from the simulation loop, effectively resolving latency bottlenecks to support real-time learning. We introduce diverse supervision mechanisms: Value-Margin Regularization (VMR) and Advantage-Weighted Action Guidance (AWAG) to effectively distill expert-like VLM action suggestions into the RL policy. Additionally, we adopt high-throughput CLIP for dense reward shaping. We address CLIP's dynamic blindness via Conditional Contrastive Action Alignment, which conditions prompts on discretized speed/command and yields a normalized, margin-based bonus from context-specific action-anchor scoring. Found-RL provides an end-to-end pipeline for fine-tuned VLM integration and shows that a lightweight RL model can achieve near-VLM performance compared with billion-parameter VLMs while sustaining real-time inference (approx. 500 FPS). Code, data, and models will be publicly available at https://github.com/ys-qu/found-rl.
VL-SAFE: Vision-Language Guided Safety-Aware Reinforcement Learning with World Models for Autonomous Driving
May 22, 2025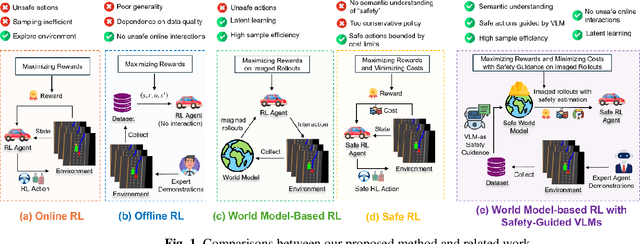
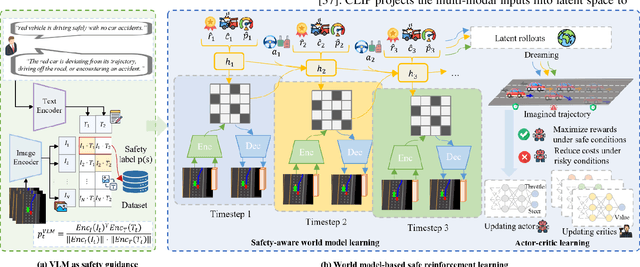
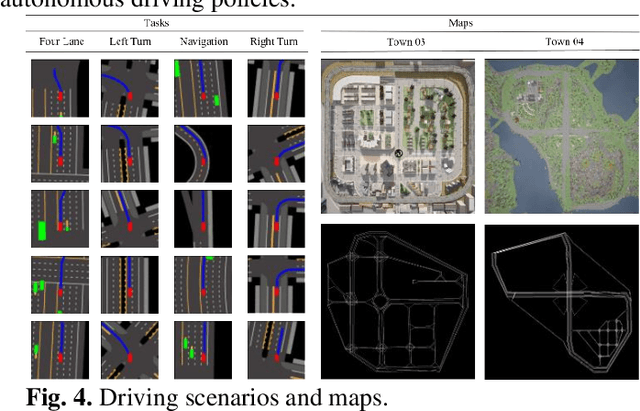
Reinforcement learning (RL)-based autonomous driving policy learning faces critical limitations such as low sample efficiency and poor generalization; its reliance on online interactions and trial-and-error learning is especially unacceptable in safety-critical scenarios. Existing methods including safe RL often fail to capture the true semantic meaning of "safety" in complex driving contexts, leading to either overly conservative driving behavior or constraint violations. To address these challenges, we propose VL-SAFE, a world model-based safe RL framework with Vision-Language model (VLM)-as-safety-guidance paradigm, designed for offline safe policy learning. Specifically, we construct offline datasets containing data collected by expert agents and labeled with safety scores derived from VLMs. A world model is trained to generate imagined rollouts together with safety estimations, allowing the agent to perform safe planning without interacting with the real environment. Based on these imagined trajectories and safety evaluations, actor-critic learning is conducted under VLM-based safety guidance to optimize the driving policy more safely and efficiently. Extensive evaluations demonstrate that VL-SAFE achieves superior sample efficiency, generalization, safety, and overall performance compared to existing baselines. To the best of our knowledge, this is the first work that introduces a VLM-guided world model-based approach for safe autonomous driving. The demo video and code can be accessed at: https://ys-qu.github.io/vlsafe-website/
Sky-Drive: A Distributed Multi-Agent Simulation Platform for Socially-Aware and Human-AI Collaborative Future Transportation
Apr 25, 2025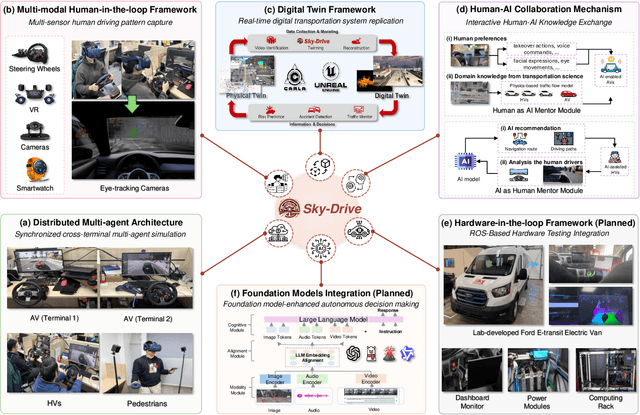
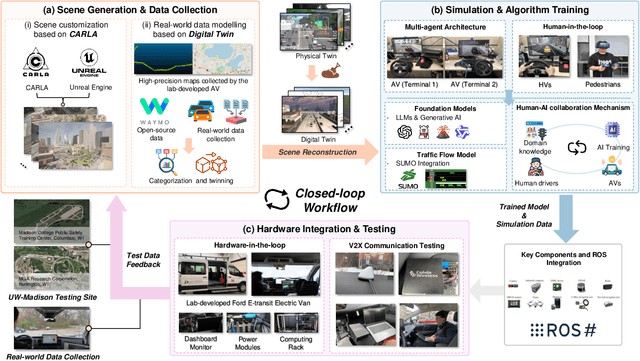
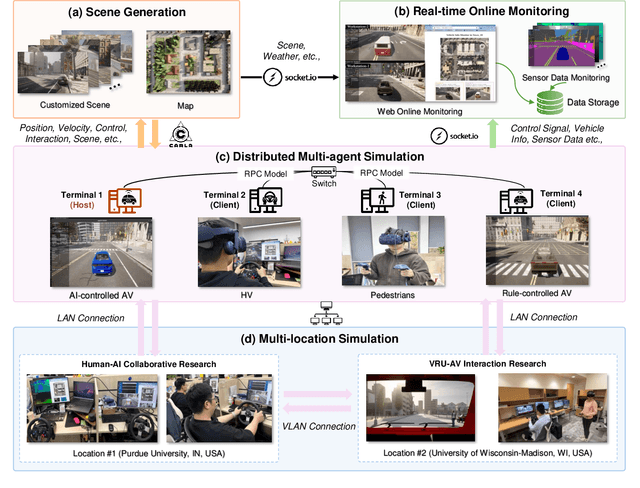
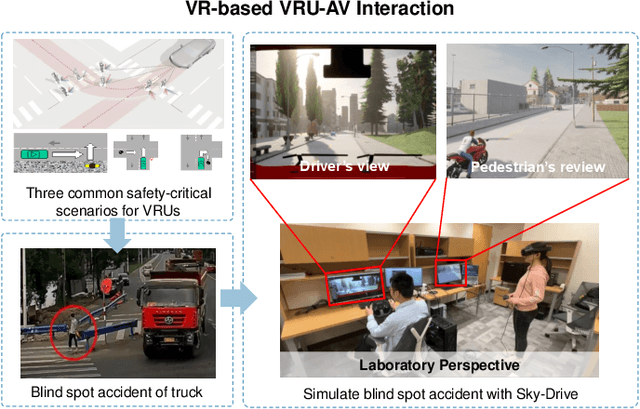
Recent advances in autonomous system simulation platforms have significantly enhanced the safe and scalable testing of driving policies. However, existing simulators do not yet fully meet the needs of future transportation research, particularly in modeling socially-aware driving agents and enabling effective human-AI collaboration. This paper introduces Sky-Drive, a novel distributed multi-agent simulation platform that addresses these limitations through four key innovations: (a) a distributed architecture for synchronized simulation across multiple terminals; (b) a multi-modal human-in-the-loop framework integrating diverse sensors to collect rich behavioral data; (c) a human-AI collaboration mechanism supporting continuous and adaptive knowledge exchange; and (d) a digital twin (DT) framework for constructing high-fidelity virtual replicas of real-world transportation environments. Sky-Drive supports diverse applications such as autonomous vehicle (AV)-vulnerable road user (VRU) interaction modeling, human-in-the-loop training, socially-aware reinforcement learning, personalized driving policy, and customized scenario generation. Future extensions will incorporate foundation models for context-aware decision support and hardware-in-the-loop (HIL) testing for real-world validation. By bridging scenario generation, data collection, algorithm training, and hardware integration, Sky-Drive has the potential to become a foundational platform for the next generation of socially-aware and human-centered autonomous transportation research. The demo video and code are available at:https://sky-lab-uw.github.io/Sky-Drive-website/
CurricuVLM: Towards Safe Autonomous Driving via Personalized Safety-Critical Curriculum Learning with Vision-Language Models
Feb 21, 2025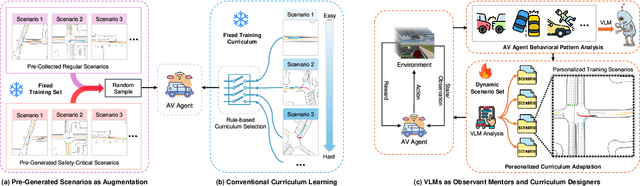
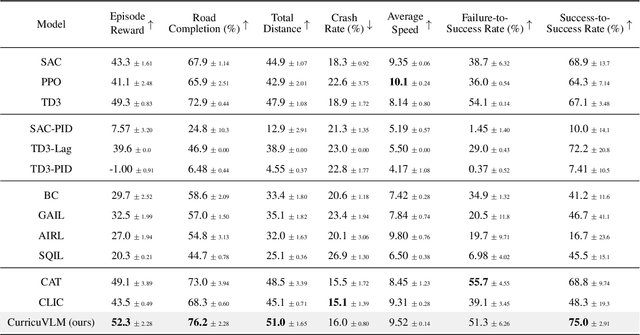
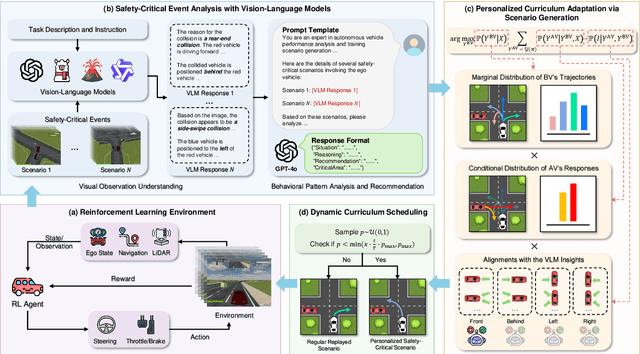
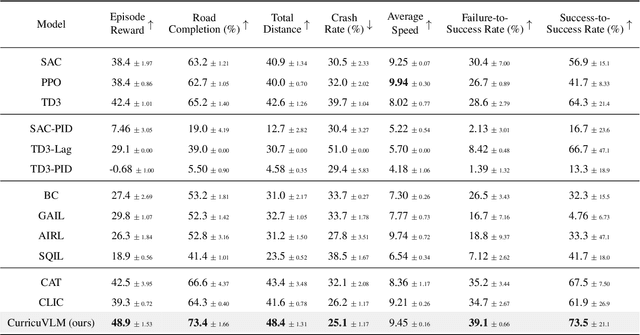
Ensuring safety in autonomous driving systems remains a critical challenge, particularly in handling rare but potentially catastrophic safety-critical scenarios. While existing research has explored generating safety-critical scenarios for autonomous vehicle (AV) testing, there is limited work on effectively incorporating these scenarios into policy learning to enhance safety. Furthermore, developing training curricula that adapt to an AV's evolving behavioral patterns and performance bottlenecks remains largely unexplored. To address these challenges, we propose CurricuVLM, a novel framework that leverages Vision-Language Models (VLMs) to enable personalized curriculum learning for autonomous driving agents. Our approach uniquely exploits VLMs' multimodal understanding capabilities to analyze agent behavior, identify performance weaknesses, and dynamically generate tailored training scenarios for curriculum adaptation. Through comprehensive analysis of unsafe driving situations with narrative descriptions, CurricuVLM performs in-depth reasoning to evaluate the AV's capabilities and identify critical behavioral patterns. The framework then synthesizes customized training scenarios targeting these identified limitations, enabling effective and personalized curriculum learning. Extensive experiments on the Waymo Open Motion Dataset show that CurricuVLM outperforms state-of-the-art baselines across both regular and safety-critical scenarios, achieving superior performance in terms of navigation success, driving efficiency, and safety metrics. Further analysis reveals that CurricuVLM serves as a general approach that can be integrated with various RL algorithms to enhance autonomous driving systems. The code and demo video are available at: https://zihaosheng.github.io/CurricuVLM/.
VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving
Dec 20, 2024



In recent years, reinforcement learning (RL)-based methods for learning driving policies have gained increasing attention in the autonomous driving community and have achieved remarkable progress in various driving scenarios. However, traditional RL approaches rely on manually engineered rewards, which require extensive human effort and often lack generalizability. To address these limitations, we propose \textbf{VLM-RL}, a unified framework that integrates pre-trained Vision-Language Models (VLMs) with RL to generate reward signals using image observation and natural language goals. The core of VLM-RL is the contrasting language goal (CLG)-as-reward paradigm, which uses positive and negative language goals to generate semantic rewards. We further introduce a hierarchical reward synthesis approach that combines CLG-based semantic rewards with vehicle state information, improving reward stability and offering a more comprehensive reward signal. Additionally, a batch-processing technique is employed to optimize computational efficiency during training. Extensive experiments in the CARLA simulator demonstrate that VLM-RL outperforms state-of-the-art baselines, achieving a 10.5\% reduction in collision rate, a 104.6\% increase in route completion rate, and robust generalization to unseen driving scenarios. Furthermore, VLM-RL can seamlessly integrate almost any standard RL algorithms, potentially revolutionizing the existing RL paradigm that relies on manual reward engineering and enabling continuous performance improvements. The demo video and code can be accessed at: https://zilin-huang.github.io/VLM-RL-website.
Towards 3D Semantic Scene Completion for Autonomous Driving: A Meta-Learning Framework Empowered by Deformable Large-Kernel Attention and Mamba Model
Nov 06, 2024Semantic scene completion (SSC) is essential for achieving comprehensive perception in autonomous driving systems. However, existing SSC methods often overlook the high deployment costs in real-world applications. Traditional architectures, such as 3D Convolutional Neural Networks (3D CNNs) and self-attention mechanisms, face challenges in efficiently capturing long-range dependencies within 3D voxel grids, limiting their effectiveness. To address these issues, we introduce MetaSSC, a novel meta-learning-based framework for SSC that leverages deformable convolution, large-kernel attention, and the Mamba (D-LKA-M) model. Our approach begins with a voxel-based semantic segmentation (SS) pretraining task, aimed at exploring the semantics and geometry of incomplete regions while acquiring transferable meta-knowledge. Using simulated cooperative perception datasets, we supervise the perception training of a single vehicle using aggregated sensor data from multiple nearby connected autonomous vehicles (CAVs), generating richer and more comprehensive labels. This meta-knowledge is then adapted to the target domain through a dual-phase training strategy that does not add extra model parameters, enabling efficient deployment. To further enhance the model's capability in capturing long-sequence relationships within 3D voxel grids, we integrate Mamba blocks with deformable convolution and large-kernel attention into the backbone network. Extensive experiments demonstrate that MetaSSC achieves state-of-the-art performance, significantly outperforming competing models while also reducing deployment costs.
Trustworthy Human-AI Collaboration: Reinforcement Learning with Human Feedback and Physics Knowledge for Safe Autonomous Driving
Sep 01, 2024In the field of autonomous driving, developing safe and trustworthy autonomous driving policies remains a significant challenge. Recently, Reinforcement Learning with Human Feedback (RLHF) has attracted substantial attention due to its potential to enhance training safety and sampling efficiency. Nevertheless, existing RLHF-enabled methods often falter when faced with imperfect human demonstrations, potentially leading to training oscillations or even worse performance than rule-based approaches. Inspired by the human learning process, we propose Physics-enhanced Reinforcement Learning with Human Feedback (PE-RLHF). This novel framework synergistically integrates human feedback (e.g., human intervention and demonstration) and physics knowledge (e.g., traffic flow model) into the training loop of reinforcement learning. The key advantage of PE-RLHF is its guarantee that the learned policy will perform at least as well as the given physics-based policy, even when human feedback quality deteriorates, thus ensuring trustworthy safety improvements. PE-RLHF introduces a Physics-enhanced Human-AI (PE-HAI) collaborative paradigm for dynamic action selection between human and physics-based actions, employs a reward-free approach with a proxy value function to capture human preferences, and incorporates a minimal intervention mechanism to reduce the cognitive load on human mentors. Extensive experiments across diverse driving scenarios demonstrate that PE-RLHF significantly outperforms traditional methods, achieving state-of-the-art (SOTA) performance in safety, efficiency, and generalizability, even with varying quality of human feedback. The philosophy behind PE-RLHF not only advances autonomous driving technology but can also offer valuable insights for other safety-critical domains. Demo video and code are available at: \https://zilin-huang.github.io/PE-RLHF-website/