 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Your Ad: Personalized Advertising Image and Text Generation with Unified Autoregressive Models
May 12, 2026Generating realistic and user-preferred advertisements is a key challenge in e-commerce. Existing approaches utilize multiple independent models driven by click-through-rate (CTR) to controllably create attractive image or text advertisements. However, their pipelines lack cross-modal perception and rely on CTR that only reflects average preferences. Therefore, we explore jointly generating personalized image-text advertisements from historical click behaviors. We first design a Unified Advertisement Generative model (Uni-AdGen) that employs a single autoregressive framework to produce both advertising images and texts. By incorporating a foreground perception module and instruction tuning, Uni-AdGen enhances the realism of the generated content. To further personalize advertisements, we equip Uni-AdGen with a coarse-to-fine preference understanding module that effectively captures user interests from noisy multimodal historical behaviors to drive personalized generation. Additionally, we construct the first large-scale Personalized Advertising image-text dataset (PAd1M) and introduce a Product Background Similarity (PBS) metric to facilitate training and evaluation. Extensive experiments show that our method outperforms baselines in general and personalized advertisement generation. Our project is available at https://github.com/JD-GenX/Uni-AdGen.
Found-RL: foundation model-enhanced reinforcement learning for autonomous driving
Feb 11, 2026Reinforcement Learning (RL) has emerged as a dominant paradigm for end-to-end autonomous driving (AD). However, RL suffers from sample inefficiency and a lack of semantic interpretability in complex scenarios. Foundation Models, particularly Vision-Language Models (VLMs), can mitigate this by offering rich, context-aware knowledge, yet their high inference latency hinders deployment in high-frequency RL training loops. To bridge this gap, we present Found-RL, a platform tailored to efficiently enhance RL for AD using foundation models. A core innovation is the asynchronous batch inference framework, which decouples heavy VLM reasoning from the simulation loop, effectively resolving latency bottlenecks to support real-time learning. We introduce diverse supervision mechanisms: Value-Margin Regularization (VMR) and Advantage-Weighted Action Guidance (AWAG) to effectively distill expert-like VLM action suggestions into the RL policy. Additionally, we adopt high-throughput CLIP for dense reward shaping. We address CLIP's dynamic blindness via Conditional Contrastive Action Alignment, which conditions prompts on discretized speed/command and yields a normalized, margin-based bonus from context-specific action-anchor scoring. Found-RL provides an end-to-end pipeline for fine-tuned VLM integration and shows that a lightweight RL model can achieve near-VLM performance compared with billion-parameter VLMs while sustaining real-time inference (approx. 500 FPS). Code, data, and models will be publicly available at https://github.com/ys-qu/found-rl.
Diffusion^2: Dual Diffusion Model with Uncertainty-Aware Adaptive Noise for Momentary Trajectory Prediction
Oct 05, 2025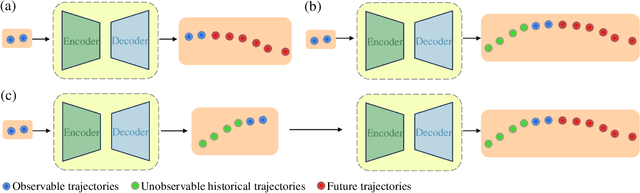
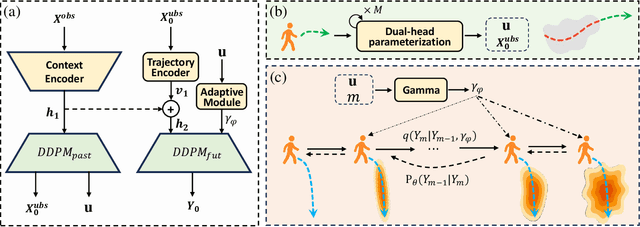
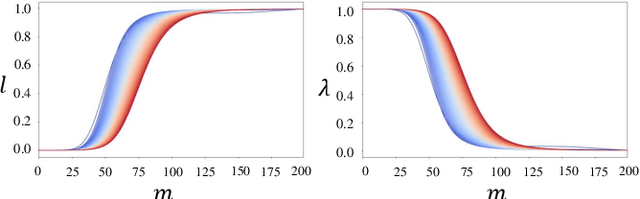
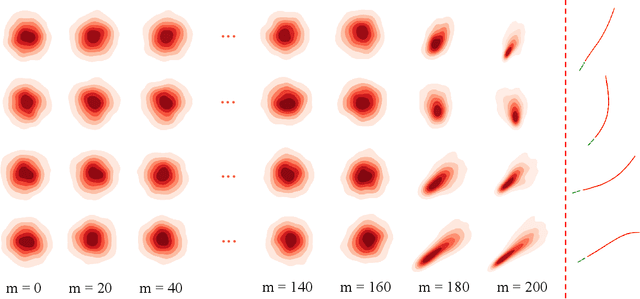
Accurate pedestrian trajectory prediction is crucial for ensuring safety and efficiency in autonomous driving and human-robot interaction scenarios. Earlier studies primarily utilized sufficient observational data to predict future trajectories. However, in real-world scenarios, such as pedestrians suddenly emerging from blind spots, sufficient observational data is often unavailable (i.e. momentary trajectory), making accurate prediction challenging and increasing the risk of traffic accidents. Therefore, advancing research on pedestrian trajectory prediction under extreme scenarios is critical for enhancing traffic safety. In this work, we propose a novel framework termed Diffusion^2, tailored for momentary trajectory prediction. Diffusion^2 consists of two sequentially connected diffusion models: one for backward prediction, which generates unobserved historical trajectories, and the other for forward prediction, which forecasts future trajectories. Given that the generated unobserved historical trajectories may introduce additional noise, we propose a dual-head parameterization mechanism to estimate their aleatoric uncertainty and design a temporally adaptive noise module that dynamically modulates the noise scale in the forward diffusion process. Empirically, Diffusion^2 sets a new state-of-the-art in momentary trajectory prediction on ETH/UCY and Stanford Drone datasets.
CAD: A General Multimodal Framework for Video Deepfake Detection via Cross-Modal Alignment and Distillation
May 21, 2025The rapid emergence of multimodal deepfakes (visual and auditory content are manipulated in concert) undermines the reliability of existing detectors that rely solely on modality-specific artifacts or cross-modal inconsistencies. In this work, we first demonstrate that modality-specific forensic traces (e.g., face-swap artifacts or spectral distortions) and modality-shared semantic misalignments (e.g., lip-speech asynchrony) offer complementary evidence, and that neglecting either aspect limits detection performance. Existing approaches either naively fuse modality-specific features without reconciling their conflicting characteristics or focus predominantly on semantic misalignment at the expense of modality-specific fine-grained artifact cues. To address these shortcomings, we propose a general multimodal framework for video deepfake detection via Cross-Modal Alignment and Distillation (CAD). CAD comprises two core components: 1) Cross-modal alignment that identifies inconsistencies in high-level semantic synchronization (e.g., lip-speech mismatches); 2) Cross-modal distillation that mitigates feature conflicts during fusion while preserving modality-specific forensic traces (e.g., spectral distortions in synthetic audio). Extensive experiments on both multimodal and unimodal (e.g., image-only/video-only)deepfake benchmarks demonstrate that CAD significantly outperforms previous methods, validating the necessity of harmonious integration of multimodal complementary information.
Sky-Drive: A Distributed Multi-Agent Simulation Platform for Socially-Aware and Human-AI Collaborative Future Transportation
Apr 25, 2025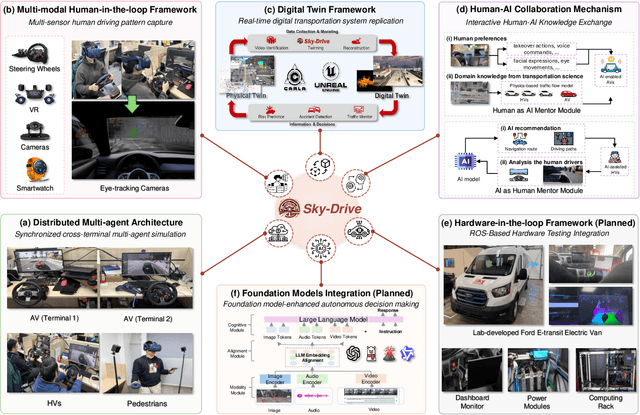
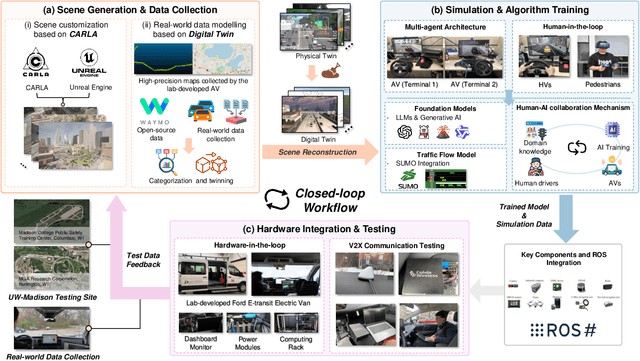
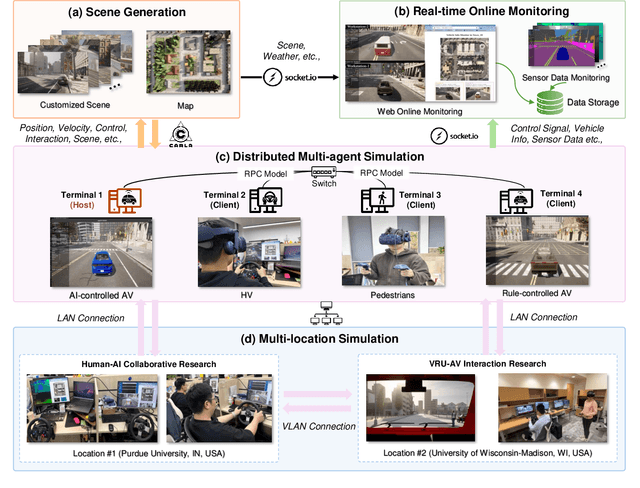
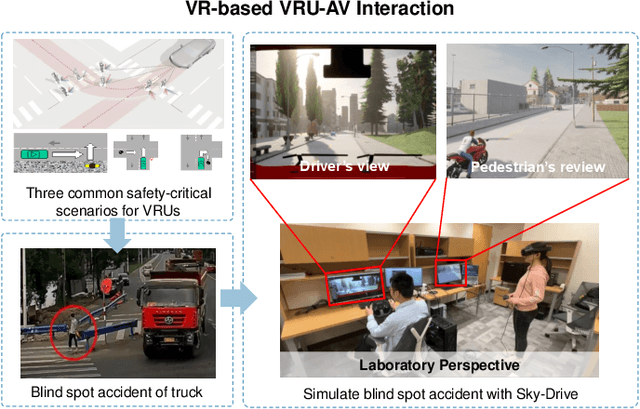
Recent advances in autonomous system simulation platforms have significantly enhanced the safe and scalable testing of driving policies. However, existing simulators do not yet fully meet the needs of future transportation research, particularly in modeling socially-aware driving agents and enabling effective human-AI collaboration. This paper introduces Sky-Drive, a novel distributed multi-agent simulation platform that addresses these limitations through four key innovations: (a) a distributed architecture for synchronized simulation across multiple terminals; (b) a multi-modal human-in-the-loop framework integrating diverse sensors to collect rich behavioral data; (c) a human-AI collaboration mechanism supporting continuous and adaptive knowledge exchange; and (d) a digital twin (DT) framework for constructing high-fidelity virtual replicas of real-world transportation environments. Sky-Drive supports diverse applications such as autonomous vehicle (AV)-vulnerable road user (VRU) interaction modeling, human-in-the-loop training, socially-aware reinforcement learning, personalized driving policy, and customized scenario generation. Future extensions will incorporate foundation models for context-aware decision support and hardware-in-the-loop (HIL) testing for real-world validation. By bridging scenario generation, data collection, algorithm training, and hardware integration, Sky-Drive has the potential to become a foundational platform for the next generation of socially-aware and human-centered autonomous transportation research. The demo video and code are available at:https://sky-lab-uw.github.io/Sky-Drive-website/
Can We Leave Deepfake Data Behind in Training Deepfake Detector?
Aug 30, 2024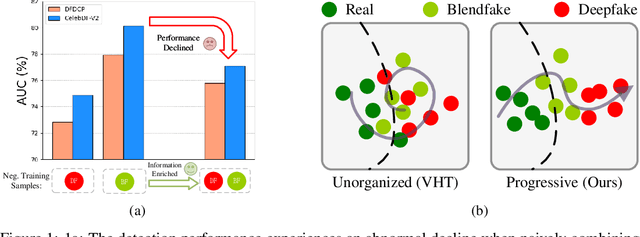
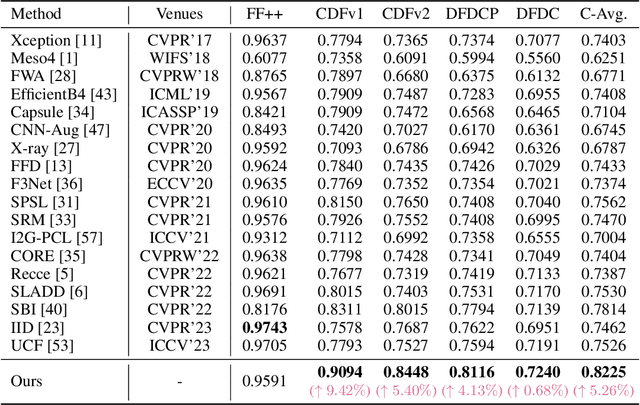
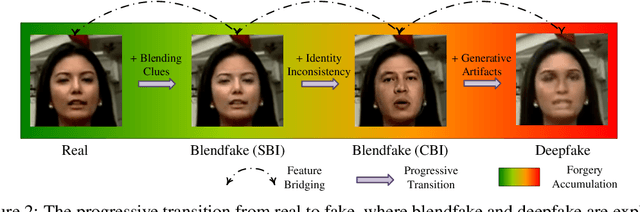
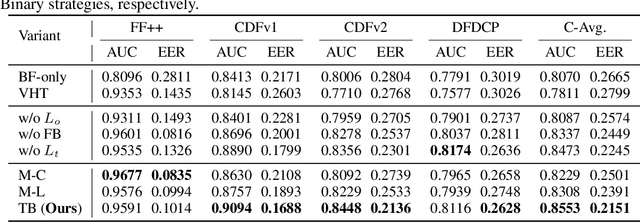
The generalization ability of deepfake detectors is vital for their applications in real-world scenarios. One effective solution to enhance this ability is to train the models with manually-blended data, which we termed "blendfake", encouraging models to learn generic forgery artifacts like blending boundary. Interestingly, current SoTA methods utilize blendfake without incorporating any deepfake data in their training process. This is likely because previous empirical observations suggest that vanilla hybrid training (VHT), which combines deepfake and blendfake data, results in inferior performance to methods using only blendfake data (so-called "1+1<2"). Therefore, a critical question arises: Can we leave deepfake behind and rely solely on blendfake data to train an effective deepfake detector? Intuitively, as deepfakes also contain additional informative forgery clues (e.g., deep generative artifacts), excluding all deepfake data in training deepfake detectors seems counter-intuitive. In this paper, we rethink the role of blendfake in detecting deepfakes and formulate the process from "real to blendfake to deepfake" to be a progressive transition. Specifically, blendfake and deepfake can be explicitly delineated as the oriented pivot anchors between "real-to-fake" transitions. The accumulation of forgery information should be oriented and progressively increasing during this transition process. To this end, we propose an Oriented Progressive Regularizor (OPR) to establish the constraints that compel the distribution of anchors to be discretely arranged. Furthermore, we introduce feature bridging to facilitate the smooth transition between adjacent anchors. Extensive experiments confirm that our design allows leveraging forgery information from both blendfake and deepfake effectively and comprehensively.
GRANP: A Graph Recurrent Attentive Neural Process Model for Vehicle Trajectory Prediction
Apr 09, 2024



As a vital component in autonomous driving, accurate trajectory prediction effectively prevents traffic accidents and improves driving efficiency. To capture complex spatial-temporal dynamics and social interactions, recent studies developed models based on advanced deep-learning methods. On the other hand, recent studies have explored the use of deep generative models to further account for trajectory uncertainties. However, the current approaches demonstrating indeterminacy involve inefficient and time-consuming practices such as sampling from trained models. To fill this gap, we proposed a novel model named Graph Recurrent Attentive Neural Process (GRANP) for vehicle trajectory prediction while efficiently quantifying prediction uncertainty. In particular, GRANP contains an encoder with deterministic and latent paths, and a decoder for prediction. The encoder, including stacked Graph Attention Networks, LSTM and 1D convolutional layers, is employed to extract spatial-temporal relationships. The decoder is used to learn a latent distribution and thus quantify prediction uncertainty. To reveal the effectiveness of our model, we evaluate the performance of GRANP on the highD dataset. Extensive experiments show that GRANP achieves state-of-the-art results and can efficiently quantify uncertainties. Additionally, we undertake an intuitive case study that showcases the interpretability of the proposed approach. The code is available at https://github.com/joy-driven/GRANP.
Domain-Aware Cross-Attention for Cross-domain Recommendation
Jan 22, 2024Cross-domain recommendation (CDR) is an important method to improve recommender system performance, especially when observations in target domains are sparse. However, most existing cross-domain recommendations fail to fully utilize the target domain's special features and are hard to be generalized to new domains. The designed network is complex and is not suitable for rapid industrial deployment. Our method introduces a two-step domain-aware cross-attention, extracting transferable features of the source domain from different granularity, which allows the efficient expression of both domain and user interests. In addition, we simplify the training process, and our model can be easily deployed on new domains. We conduct experiments on both public datasets and industrial datasets, and the experimental results demonstrate the effectiveness of our method. We have also deployed the model in an online advertising system and observed significant improvements in both Click-Through-Rate (CTR) and effective cost per mille (ECPM).
Transcending Forgery Specificity with Latent Space Augmentation for Generalizable Deepfake Detection
Nov 19, 2023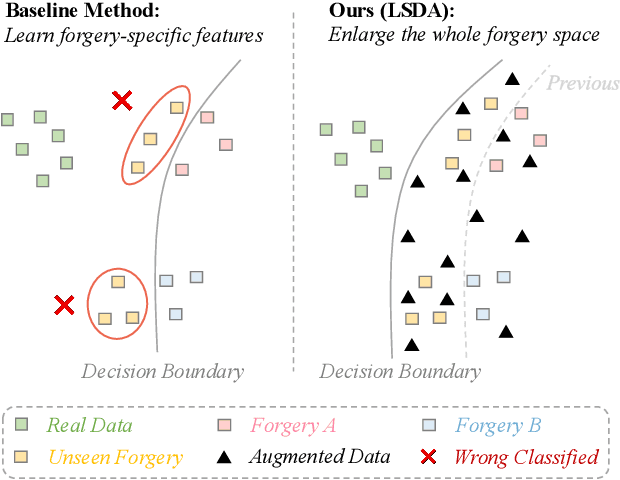

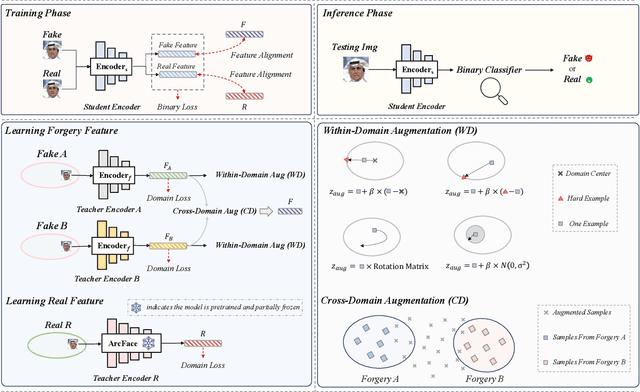

Deepfake detection faces a critical generalization hurdle, with performance deteriorating when there is a mismatch between the distributions of training and testing data. A broadly received explanation is the tendency of these detectors to be overfitted to forgery-specific artifacts, rather than learning features that are widely applicable across various forgeries. To address this issue, we propose a simple yet effective detector called LSDA (\underline{L}atent \underline{S}pace \underline{D}ata \underline{A}ugmentation), which is based on a heuristic idea: representations with a wider variety of forgeries should be able to learn a more generalizable decision boundary, thereby mitigating the overfitting of method-specific features (see Figure. 1). Following this idea, we propose to enlarge the forgery space by constructing and simulating variations within and across forgery features in the latent space. This approach encompasses the acquisition of enriched, domain-specific features and the facilitation of smoother transitions between different forgery types, effectively bridging domain gaps. Our approach culminates in refining a binary classifier that leverages the distilled knowledge from the enhanced features, striving for a generalizable deepfake detector. Comprehensive experiments show that our proposed method is surprisingly effective and transcends state-of-the-art detectors across several widely used benchmarks.
Audio compression-assisted feature extraction for voice replay attack detection
Oct 10, 2023



Replay attack is one of the most effective and simplest voice spoofing attacks. Detecting replay attacks is challenging, according to the Automatic Speaker Verification Spoofing and Countermeasures Challenge 2021 (ASVspoof 2021), because they involve a loudspeaker, a microphone, and acoustic conditions (e.g., background noise). One obstacle to detecting replay attacks is finding robust feature representations that reflect the channel noise information added to the replayed speech. This study proposes a feature extraction approach that uses audio compression for assistance. Audio compression compresses audio to preserve content and speaker information for transmission. The missed information after decompression is expected to contain content- and speaker-independent information (e.g., channel noise added during the replay process). We conducted a comprehensive experiment with a few data augmentation techniques and 3 classifiers on the ASVspoof 2021 physical access (PA) set and confirmed the effectiveness of the proposed feature extraction approach. To the best of our knowledge, the proposed approach achieves the lowest EER at 22.71% on the ASVspoof 2021 PA evaluation set.