 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Like Van Gogh: Structure-Aware Style Transfer via Flow-Guided 3D Gaussian Splatting
Jan 15, 2026In 1888, Vincent van Gogh wrote, "I am seeking exaggeration in the essential." This principle, amplifying structural form while suppressing photographic detail, lies at the core of Post-Impressionist art. However, most existing 3D style transfer methods invert this philosophy, treating geometry as a rigid substrate for surface-level texture projection. To authentically reproduce Post-Impressionist stylization, geometric abstraction must be embraced as the primary vehicle of expression. We propose a flow-guided geometric advection framework for 3D Gaussian Splatting (3DGS) that operationalizes this principle in a mesh-free setting. Our method extracts directional flow fields from 2D paintings and back-propagates them into 3D space, rectifying Gaussian primitives to form flow-aligned brushstrokes that conform to scene topology without relying on explicit mesh priors. This enables expressive structural deformation driven directly by painterly motion rather than photometric constraints. Our contributions are threefold: (1) a projection-based, mesh-free flow guidance mechanism that transfers 2D artistic motion into 3D Gaussian geometry; (2) a luminance-structure decoupling strategy that isolates geometric deformation from color optimization, mitigating artifacts during aggressive structural abstraction; and (3) a VLM-as-a-Judge evaluation framework that assesses artistic authenticity through aesthetic judgment instead of conventional pixel-level metrics, explicitly addressing the subjective nature of artistic stylization.
Boundary-Aware NL2SQL: Integrating Reliability through Hybrid Reward and Data Synthesis
Jan 15, 2026In this paper, we present BAR-SQL (Boundary-Aware Reliable NL2SQL), a unified training framework that embeds reliability and boundary awareness directly into the generation process. We introduce a Seed Mutation data synthesis paradigm that constructs a representative enterprise corpus, explicitly encompassing multi-step analytical queries alongside boundary cases including ambiguity and schema limitations. To ensure interpretability, we employ Knowledge-Grounded Reasoning Synthesis, which produces Chain-of-Thought traces explicitly anchored in schema metadata and business rules. The model is trained through a two-stage process: Supervised Fine-Tuning (SFT) followed by Reinforcement Learning via Group Relative Policy Optimization. We design a Task-Conditioned Hybrid Reward mechanism that simultaneously optimizes SQL execution accuracy-leveraging Abstract Syntax Tree analysis and dense result matching-and semantic precision in abstention responses. To evaluate reliability alongside generation accuracy, we construct and release Ent-SQL-Bench, which jointly assesse SQL precision and boundary-aware abstention across ambiguous and unanswerable queries. Experimental results on this benchmark demonstrate that BAR-SQL achieves 91.48% average accuracy, outperforming leading proprietary models, including Claude 4.5 Sonnet and GPT-5, in both SQL generation quality and boundary-aware abstention capability. The source code and benchmark are available anonymously at: https://github.com/TianSongS/BAR-SQL.
ProImage-Bench: Rubric-Based Evaluation for Professional Image Generation
Dec 13, 2025We study professional image generation, where a model must synthesize information-dense, scientifically precise illustrations from technical descriptions rather than merely produce visually plausible pictures. To quantify the progress, we introduce ProImage-Bench, a rubric-based benchmark that targets biology schematics, engineering/patent drawings, and general scientific diagrams. For 654 figures collected from real textbooks and technical reports, we construct detailed image instructions and a hierarchy of rubrics that decompose correctness into 6,076 criteria and 44,131 binary checks. Rubrics are derived from surrounding text and reference figures using large multimodal models, and are evaluated by an automated LMM-based judge with a principled penalty scheme that aggregates sub-question outcomes into interpretable criterion scores. We benchmark several representative text-to-image models on ProImage-Bench and find that, despite strong open-domain performance, the best base model reaches only 0.791 rubric accuracy and 0.553 criterion score overall, revealing substantial gaps in fine-grained scientific fidelity. Finally, we show that the same rubrics provide actionable supervision: feeding failed checks back into an editing model for iterative refinement boosts a strong generator from 0.653 to 0.865 in rubric accuracy and from 0.388 to 0.697 in criterion score. ProImage-Bench thus offers both a rigorous diagnostic for professional image generation and a scalable signal for improving specification-faithful scientific illustrations.
SHANKS: Simultaneous Hearing and Thinking for Spoken Language Models
Oct 08, 2025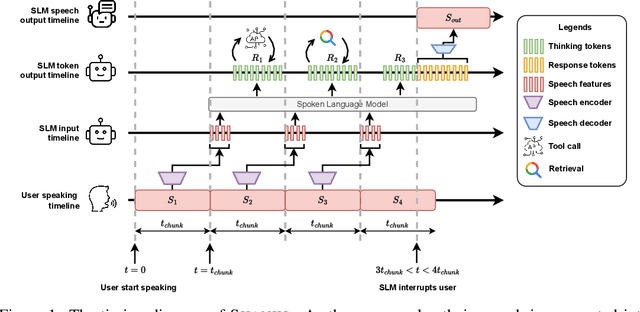
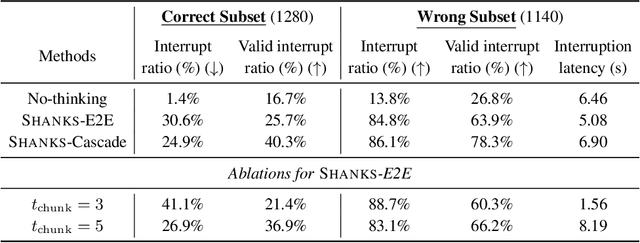

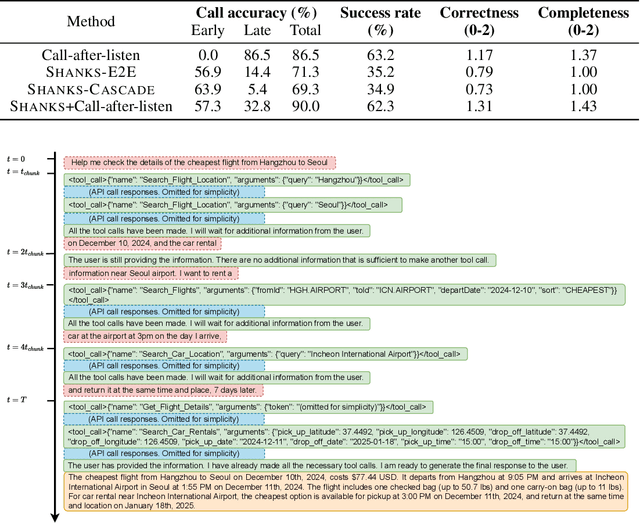
Current large language models (LLMs) and spoken language models (SLMs) begin thinking and taking actions only after the user has finished their turn. This prevents the model from interacting during the user's turn and can lead to high response latency while it waits to think. Consequently, thinking after receiving the full input is not suitable for speech-to-speech interaction, where real-time, low-latency exchange is important. We address this by noting that humans naturally "think while listening." In this paper, we propose SHANKS, a general inference framework that enables SLMs to generate unspoken chain-of-thought reasoning while listening to the user input. SHANKS streams the input speech in fixed-duration chunks and, as soon as a chunk is received, generates unspoken reasoning based on all previous speech and reasoning, while the user continues speaking. SHANKS uses this unspoken reasoning to decide whether to interrupt the user and to make tool calls to complete the task. We demonstrate that SHANKS enhances real-time user-SLM interaction in two scenarios: (1) when the user is presenting a step-by-step solution to a math problem, SHANKS can listen, reason, and interrupt when the user makes a mistake, achieving 37.1% higher interruption accuracy than a baseline that interrupts without thinking; and (2) in a tool-augmented dialogue, SHANKS can complete 56.9% of the tool calls before the user finishes their turn. Overall, SHANKS moves toward models that keep thinking throughout the conversation, not only after a turn ends. Animated illustrations of Shanks can be found at https://d223302.github.io/SHANKS/
Can Understanding and Generation Truly Benefit Together -- or Just Coexist?
Sep 11, 2025



In this paper, we introduce an insightful paradigm through the Auto-Encoder lens-understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. Using reconstruction fidelity as the unified training objective, we enforce the coherent bidirectional information flow between the understanding and generation processes, bringing mutual gains. To implement this, we propose UAE, a novel framework for unified multimodal learning. We begin by pre-training the decoder with large-scale long-context image captions to capture fine-grained semantic and complex spatial relationships. We then propose Unified-GRPO via reinforcement learning (RL), which covers three stages: (1) A cold-start phase to gently initialize both encoder and decoder with a semantic reconstruction loss; (2) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual understanding; (3) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. For evaluation, we introduce Unified-Bench, the first benchmark tailored to assess the degree of unification of the UMMs. A surprising "aha moment" arises within the multimodal learning domain: as RL progresses, the encoder autonomously produces more descriptive captions, while the decoder simultaneously demonstrates a profound ability to understand these intricate descriptions, resulting in reconstructions of striking fidelity.
Audio-Aware Large Language Models as Judges for Speaking Styles
Jun 06, 2025Audio-aware large language models (ALLMs) can understand the textual and non-textual information in the audio input. In this paper, we explore using ALLMs as an automatic judge to assess the speaking styles of speeches. We use ALLM judges to evaluate the speeches generated by SLMs on two tasks: voice style instruction following and role-playing. The speaking style we consider includes emotion, volume, speaking pace, word emphasis, pitch control, and non-verbal elements. We use four spoken language models (SLMs) to complete the two tasks and use humans and ALLMs to judge the SLMs' responses. We compare two ALLM judges, GPT-4o-audio and Gemini-2.5-pro, with human evaluation results and show that the agreement between Gemini and human judges is comparable to the agreement between human evaluators. These promising results show that ALLMs can be used as a judge to evaluate SLMs. Our results also reveal that current SLMs, even GPT-4o-audio, still have room for improvement in controlling the speaking style and generating natural dialogues.
Improving Data Efficiency for LLM Reinforcement Fine-tuning Through Difficulty-targeted Online Data Selection and Rollout Replay
Jun 05, 2025Reinforcement learning (RL) has become an effective approach for fine-tuning large language models (LLMs), particularly to enhance their reasoning capabilities. However, RL fine-tuning remains highly resource-intensive, and existing work has largely overlooked the problem of data efficiency. In this paper, we propose two techniques to improve data efficiency in LLM RL fine-tuning: difficulty-targeted online data selection and rollout replay. We introduce the notion of adaptive difficulty to guide online data selection, prioritizing questions of moderate difficulty that are more likely to yield informative learning signals. To estimate adaptive difficulty efficiently, we develop an attention-based framework that requires rollouts for only a small reference set of questions. The adaptive difficulty of the remaining questions is then estimated based on their similarity to this set. To further reduce rollout cost, we introduce a rollout replay mechanism that reuses recent rollouts, lowering per-step computation while maintaining stable updates. Extensive experiments across 6 LLM-dataset combinations show that our method reduces RL fine-tuning time by 25% to 65% to reach the same level of performance as the original GRPO algorithm.
CAD: A General Multimodal Framework for Video Deepfake Detection via Cross-Modal Alignment and Distillation
May 21, 2025The rapid emergence of multimodal deepfakes (visual and auditory content are manipulated in concert) undermines the reliability of existing detectors that rely solely on modality-specific artifacts or cross-modal inconsistencies. In this work, we first demonstrate that modality-specific forensic traces (e.g., face-swap artifacts or spectral distortions) and modality-shared semantic misalignments (e.g., lip-speech asynchrony) offer complementary evidence, and that neglecting either aspect limits detection performance. Existing approaches either naively fuse modality-specific features without reconciling their conflicting characteristics or focus predominantly on semantic misalignment at the expense of modality-specific fine-grained artifact cues. To address these shortcomings, we propose a general multimodal framework for video deepfake detection via Cross-Modal Alignment and Distillation (CAD). CAD comprises two core components: 1) Cross-modal alignment that identifies inconsistencies in high-level semantic synchronization (e.g., lip-speech mismatches); 2) Cross-modal distillation that mitigates feature conflicts during fusion while preserving modality-specific forensic traces (e.g., spectral distortions in synthetic audio). Extensive experiments on both multimodal and unimodal (e.g., image-only/video-only)deepfake benchmarks demonstrate that CAD significantly outperforms previous methods, validating the necessity of harmonious integration of multimodal complementary information.
Few-Step Diffusion via Score identity Distillation
May 19, 2025Diffusion distillation has emerged as a promising strategy for accelerating text-to-image (T2I) diffusion models by distilling a pretrained score network into a one- or few-step generator. While existing methods have made notable progress, they often rely on real or teacher-synthesized images to perform well when distilling high-resolution T2I diffusion models such as Stable Diffusion XL (SDXL), and their use of classifier-free guidance (CFG) introduces a persistent trade-off between text-image alignment and generation diversity. We address these challenges by optimizing Score identity Distillation (SiD) -- a data-free, one-step distillation framework -- for few-step generation. Backed by theoretical analysis that justifies matching a uniform mixture of outputs from all generation steps to the data distribution, our few-step distillation algorithm avoids step-specific networks and integrates seamlessly into existing pipelines, achieving state-of-the-art performance on SDXL at 1024x1024 resolution. To mitigate the alignment-diversity trade-off when real text-image pairs are available, we introduce a Diffusion GAN-based adversarial loss applied to the uniform mixture and propose two new guidance strategies: Zero-CFG, which disables CFG in the teacher and removes text conditioning in the fake score network, and Anti-CFG, which applies negative CFG in the fake score network. This flexible setup improves diversity without sacrificing alignment. Comprehensive experiments on SD1.5 and SDXL demonstrate state-of-the-art performance in both one-step and few-step generation settings, along with robustness to the absence of real images. Our efficient PyTorch implementation, along with the resulting one- and few-step distilled generators, will be released publicly as a separate branch at https://github.com/mingyuanzhou/SiD-LSG.
Restoration Score Distillation: From Corrupted Diffusion Pretraining to One-Step High-Quality Generation
May 19, 2025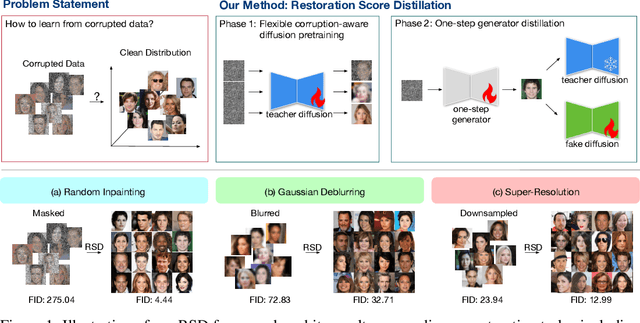


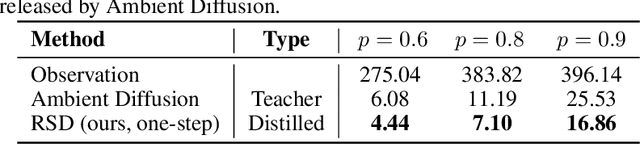
Learning generative models from corrupted data is a fundamental yet persistently challenging task across scientific disciplines, particularly when access to clean data is limited or expensive. Denoising Score Distillation (DSD) \cite{chen2025denoising} recently introduced a novel and surprisingly effective strategy that leverages score distillation to train high-fidelity generative models directly from noisy observations. Building upon this foundation, we propose \textit{Restoration Score Distillation} (RSD), a principled generalization of DSD that accommodates a broader range of corruption types, such as blurred, incomplete, or low-resolution images. RSD operates by first pretraining a teacher diffusion model solely on corrupted data and subsequently distilling it into a single-step generator that produces high-quality reconstructions. Empirically, RSD consistently surpasses its teacher model across diverse restoration tasks on both natural and scientific datasets. Moreover, beyond standard diffusion objectives, the RSD framework is compatible with several corruption-aware training techniques such as Ambient Tweedie, Ambient Diffusion, and its Fourier-space variant, enabling flexible integration with recent advances in diffusion modeling. Theoretically, we demonstrate that in a linear regime, RSD recovers the eigenspace of the clean data covariance matrix from linear measurements, thereby serving as an implicit regularizer. This interpretation recasts score distillation not only as a sampling acceleration technique but as a principled approach to enhancing generative performance in severely degraded data regimes.