 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarmageNet: A Dataset and Scalable Representation for Generic Garment Modeling
Apr 02, 2025

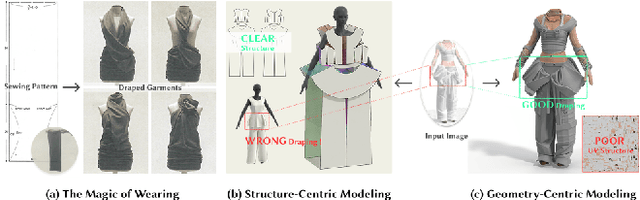
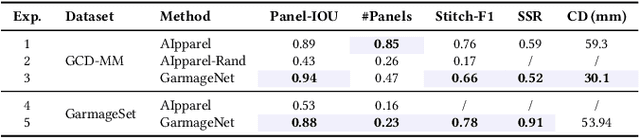
High-fidelity garment modeling remains challenging due to the lack of large-scale, high-quality datasets and efficient representations capable of handling non-watertight, multi-layer geometries. In this work, we introduce Garmage, a neural-network-and-CG-friendly garment representation that seamlessly encodes the accurate geometry and sewing pattern of complex multi-layered garments as a structured set of per-panel geometry images. As a dual-2D-3D representation, Garmage achieves an unprecedented integration of 2D image-based algorithms with 3D modeling workflows, enabling high fidelity, non-watertight, multi-layered garment geometries with direct compatibility for industrial-grade simulations.Built upon this representation, we present GarmageNet, a novel generation framework capable of producing detailed multi-layered garments with body-conforming initial geometries and intricate sewing patterns, based on user prompts or existing in-the-wild sewing patterns. Furthermore, we introduce a robust stitching algorithm that recovers per-vertex stitches, ensuring seamless integration into flexible simulation pipelines for downstream editing of sewing patterns, material properties, and dynamic simulations. Finally, we release an industrial-standard, large-scale, high-fidelity garment dataset featuring detailed annotations, vertex-wise correspondences, and a robust pipeline for converting unstructured production sewing patterns into GarmageNet standard structural assets, paving the way for large-scale, industrial-grade garment generation systems.
Design2GarmentCode: Turning Design Concepts to Tangible Garments Through Program Synthesis
Dec 12, 2024



Sewing patterns, the essential blueprints for fabric cutting and tailoring, act as a crucial bridge between design concepts and producible garments. However, existing uni-modal sewing pattern generation models struggle to effectively encode complex design concepts with a multi-modal nature and correlate them with vectorized sewing patterns that possess precise geometric structures and intricate sewing relations. In this work, we propose a novel sewing pattern generation approach Design2GarmentCode based on Large Multimodal Models (LMMs), to generate parametric pattern-making programs from multi-modal design concepts. LMM offers an intuitive interface for interpreting diverse design inputs, while pattern-making programs could serve as well-structured and semantically meaningful representations of sewing patterns, and act as a robust bridge connecting the cross-domain pattern-making knowledge embedded in LMMs with vectorized sewing patterns. Experimental results demonstrate that our method can flexibly handle various complex design expressions such as images, textual descriptions, designer sketches, or their combinations, and convert them into size-precise sewing patterns with correct stitches. Compared to previous methods, our approach significantly enhances training efficiency, generation quality, and authoring flexibility. Our code and data will be publicly available.
FashionR2R: Texture-preserving Rendered-to-Real Image Translation with Diffusion Models
Oct 18, 2024



Modeling and producing lifelike clothed human images has attracted researchers' attention from different areas for decades, with the complexity from highly articulated and structured content. Rendering algorithms decompose and simulate the imaging process of a camera, while are limited by the accuracy of modeled variables and the efficiency of computation. Generative models can produce impressively vivid human images, however still lacking in controllability and editability. This paper studies photorealism enhancement of rendered images, leveraging generative power from diffusion models on the controlled basis of rendering. We introduce a novel framework to translate rendered images into their realistic counterparts, which consists of two stages: Domain Knowledge Injection (DKI) and Realistic Image Generation (RIG). In DKI, we adopt positive (real) domain finetuning and negative (rendered) domain embedding to inject knowledge into a pretrained Text-to-image (T2I) diffusion model. In RIG, we generate the realistic image corresponding to the input rendered image, with a Texture-preserving Attention Control (TAC) to preserve fine-grained clothing textures, exploiting the decoupled features encoded in the UNet structure. Additionally, we introduce SynFashion dataset, featuring high-quality digital clothing images with diverse textures. Extensive experimental results demonstrate the superiority and effectiveness of our method in rendered-to-real image translation.