 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-Parsing: Perception, Structuring and Recognition via High-Parallelism Decoding
Jan 28, 2026This paper presents Youtu-Parsing, an efficient and versatile document parsing model designed for high-performance content extraction. The architecture employs a native Vision Transformer (ViT) featuring a dynamic-resolution visual encoder to extract shared document features, coupled with a prompt-guided Youtu-LLM-2B language model for layout analysis and region-prompted decoding. Leveraging this decoupled and feature-reusable framework, we introduce a high-parallelism decoding strategy comprising two core components: token parallelism and query parallelism. The token parallelism strategy concurrently generates up to 64 candidate tokens per inference step, which are subsequently validated through a verification mechanism. This approach yields a 5--11x speedup over traditional autoregressive decoding and is particularly well-suited for highly structured scenarios, such as table recognition. To further exploit the advantages of region-prompted decoding, the query parallelism strategy enables simultaneous content prediction for multiple bounding boxes (up to five), providing an additional 2x acceleration while maintaining output quality equivalent to standard decoding. Youtu-Parsing encompasses a diverse range of document elements, including text, formulas, tables, charts, seals, and hierarchical structures. Furthermore, the model exhibits strong robustness when handling rare characters, multilingual text, and handwritten content. Extensive evaluations demonstrate that Youtu-Parsing achieves state-of-the-art (SOTA) performance on both the OmniDocBench and olmOCR-bench benchmarks. Overall, Youtu-Parsing demonstrates significant experimental value and practical utility for large-scale document intelligence applications.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
FashionR2R: Texture-preserving Rendered-to-Real Image Translation with Diffusion Models
Oct 18, 2024



Modeling and producing lifelike clothed human images has attracted researchers' attention from different areas for decades, with the complexity from highly articulated and structured content. Rendering algorithms decompose and simulate the imaging process of a camera, while are limited by the accuracy of modeled variables and the efficiency of computation. Generative models can produce impressively vivid human images, however still lacking in controllability and editability. This paper studies photorealism enhancement of rendered images, leveraging generative power from diffusion models on the controlled basis of rendering. We introduce a novel framework to translate rendered images into their realistic counterparts, which consists of two stages: Domain Knowledge Injection (DKI) and Realistic Image Generation (RIG). In DKI, we adopt positive (real) domain finetuning and negative (rendered) domain embedding to inject knowledge into a pretrained Text-to-image (T2I) diffusion model. In RIG, we generate the realistic image corresponding to the input rendered image, with a Texture-preserving Attention Control (TAC) to preserve fine-grained clothing textures, exploiting the decoupled features encoded in the UNet structure. Additionally, we introduce SynFashion dataset, featuring high-quality digital clothing images with diverse textures. Extensive experimental results demonstrate the superiority and effectiveness of our method in rendered-to-real image translation.
Attention Where It Matters: Rethinking Visual Document Understanding with Selective Region Concentration
Sep 03, 2023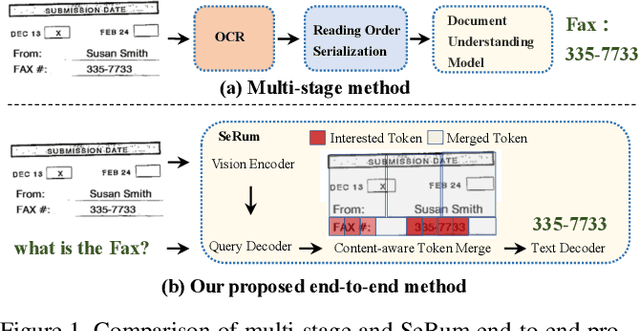
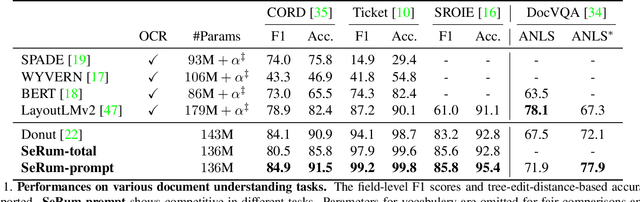
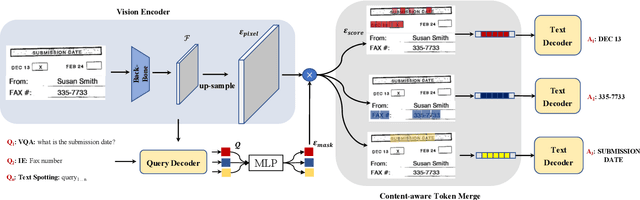

We propose a novel end-to-end document understanding model called SeRum (SElective Region Understanding Model) for extracting meaningful information from document images, including document analysis, retrieval, and office automation. Unlike state-of-the-art approaches that rely on multi-stage technical schemes and are computationally expensive, SeRum converts document image understanding and recognition tasks into a local decoding process of the visual tokens of interest, using a content-aware token merge module. This mechanism enables the model to pay more attention to regions of interest generated by the query decoder, improving the model's effectiveness and speeding up the decoding speed of the generative scheme. We also designed several pre-training tasks to enhance the understanding and local awareness of the model. Experimental results demonstrate that SeRum achieves state-of-the-art performance on document understanding tasks and competitive results on text spotting tasks. SeRum represents a substantial advancement towards enabling efficient and effective end-to-end document understanding.
ICDAR 2023 Competition on Structured Text Extraction from Visually-Rich Document Images
Jun 05, 2023Structured text extraction is one of the most valuable and challenging application directions in the field of Document AI. However, the scenarios of past benchmarks are limited, and the corresponding evaluation protocols usually focus on the submodules of the structured text extraction scheme. In order to eliminate these problems, we organized the ICDAR 2023 competition on Structured text extraction from Visually-Rich Document images (SVRD). We set up two tracks for SVRD including Track 1: HUST-CELL and Track 2: Baidu-FEST, where HUST-CELL aims to evaluate the end-to-end performance of Complex Entity Linking and Labeling, and Baidu-FEST focuses on evaluating the performance and generalization of Zero-shot / Few-shot Structured Text extraction from an end-to-end perspective. Compared to the current document benchmarks, our two tracks of competition benchmark enriches the scenarios greatly and contains more than 50 types of visually-rich document images (mainly from the actual enterprise applications). The competition opened on 30th December, 2022 and closed on 24th March, 2023. There are 35 participants and 91 valid submissions received for Track 1, and 15 participants and 26 valid submissions received for Track 2. In this report we will presents the motivation, competition datasets, task definition, evaluation protocol, and submission summaries. According to the performance of the submissions, we believe there is still a large gap on the expected information extraction performance for complex and zero-shot scenarios. It is hoped that this competition will attract many researchers in the field of CV and NLP, and bring some new thoughts to the field of Document AI.
Highly Efficient Follicular Segmentation in Thyroid Cytopathological Whole Slide Image
Feb 13, 2019

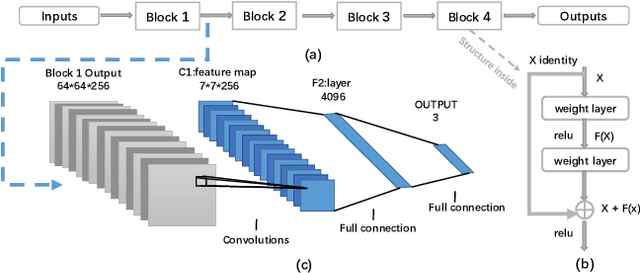

In this paper, we propose a novel method for highly efficient follicular segmentation of thyroid cytopathological WSIs. Firstly, we propose a hybrid segmentation architecture, which integrates a classifier into Deeplab V3 by adding a branch. A large amount of the WSI segmentation time is saved by skipping the irrelevant areas using the classification branch. Secondly, we merge the low scale fine features into the original atrous spatial pyramid pooling (ASPP) in Deeplab V3 to accurately represent the details in cytopathological images. Thirdly, our hybrid model is trained by a criterion-oriented adaptive loss function, which leads the model converging much faster. Experimental results on a collection of thyroid patches demonstrate that the proposed model reaches 80.9% on the segmentation accuracy. Besides, 93% time is reduced for the WSI segmentation by using our proposed method, and the WSI-level accuracy achieves 53.4%.