 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICDAR 2023 Competition on Structured Text Extraction from Visually-Rich Document Images
Jun 05, 2023Structured text extraction is one of the most valuable and challenging application directions in the field of Document AI. However, the scenarios of past benchmarks are limited, and the corresponding evaluation protocols usually focus on the submodules of the structured text extraction scheme. In order to eliminate these problems, we organized the ICDAR 2023 competition on Structured text extraction from Visually-Rich Document images (SVRD). We set up two tracks for SVRD including Track 1: HUST-CELL and Track 2: Baidu-FEST, where HUST-CELL aims to evaluate the end-to-end performance of Complex Entity Linking and Labeling, and Baidu-FEST focuses on evaluating the performance and generalization of Zero-shot / Few-shot Structured Text extraction from an end-to-end perspective. Compared to the current document benchmarks, our two tracks of competition benchmark enriches the scenarios greatly and contains more than 50 types of visually-rich document images (mainly from the actual enterprise applications). The competition opened on 30th December, 2022 and closed on 24th March, 2023. There are 35 participants and 91 valid submissions received for Track 1, and 15 participants and 26 valid submissions received for Track 2. In this report we will presents the motivation, competition datasets, task definition, evaluation protocol, and submission summaries. According to the performance of the submissions, we believe there is still a large gap on the expected information extraction performance for complex and zero-shot scenarios. It is hoped that this competition will attract many researchers in the field of CV and NLP, and bring some new thoughts to the field of Document AI.
Visual Information Extraction in the Wild: Practical Dataset and End-to-end Solution
May 12, 2023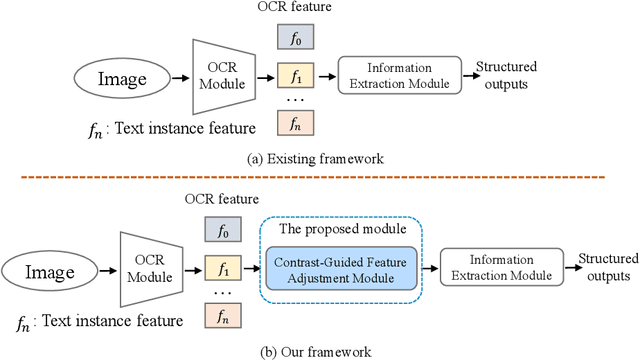

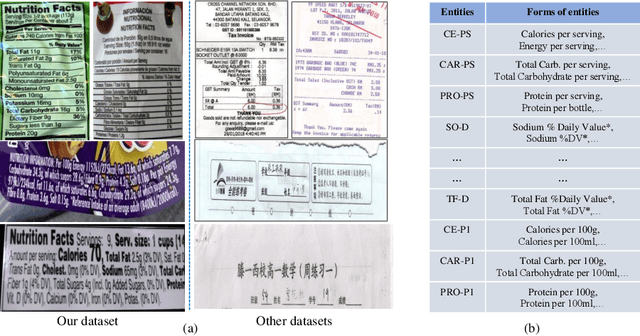
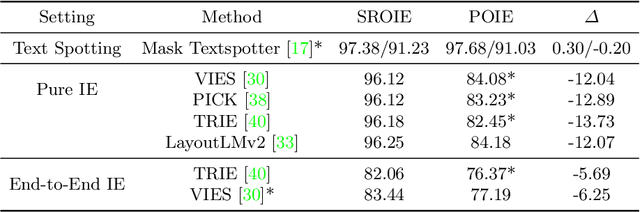
Visual information extraction (VIE), which aims to simultaneously perform OCR and information extraction in a unified framework, has drawn increasing attention due to its essential role in various applications like understanding receipts, goods, and traffic signs. However, as existing benchmark datasets for VIE mainly consist of document images without the adequate diversity of layout structures, background disturbs, and entity categories, they cannot fully reveal the challenges of real-world applications. In this paper, we propose a large-scale dataset consisting of camera images for VIE, which contains not only the larger variance of layout, backgrounds, and fonts but also much more types of entities. Besides, we propose a novel framework for end-to-end VIE that combines the stages of OCR and information extraction in an end-to-end learning fashion. Different from the previous end-to-end approaches that directly adopt OCR features as the input of an information extraction module, we propose to use contrastive learning to narrow the semantic gap caused by the difference between the tasks of OCR and information extraction. We evaluate the existing end-to-end methods for VIE on the proposed dataset and observe that the performance of these methods has a distinguishable drop from SROIE (a widely used English dataset) to our proposed dataset due to the larger variance of layout and entities. These results demonstrate our dataset is more practical for promoting advanced VIE algorithms. In addition, experiments demonstrate that the proposed VIE method consistently achieves the obvious performance gains on the proposed and SROIE datasets.