 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocThinker: Explainable Multimodal Large Language Models with Rule-based Reinforcement Learning for Document Understanding
Aug 12, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in document understanding. However, their reasoning processes remain largely black-box, making it difficult to ensure reliability and trustworthiness, especially in high-stakes domains such as legal, financial, and medical document analysis. Existing methods use fixed Chain-of-Thought (CoT) reasoning with supervised fine-tuning (SFT) but suffer from catastrophic forgetting, poor adaptability, and limited generalization across domain tasks. In this paper, we propose DocThinker, a rule-based Reinforcement Learning (RL) framework for dynamic inference-time reasoning. Instead of relying on static CoT templates, DocThinker autonomously refines reasoning strategies via policy learning, generating explainable intermediate results, including structured reasoning processes, rephrased questions, regions of interest (RoI) supporting the answer, and the final answer. By integrating multi-objective rule-based rewards and KL-constrained optimization, our method mitigates catastrophic forgetting and enhances both adaptability and transparency. Extensive experiments on multiple benchmarks demonstrate that DocThinker significantly improves generalization while producing more explainable and human-understandable reasoning steps. Our findings highlight RL as a powerful alternative for enhancing explainability and adaptability in MLLM-based document understanding. Code will be available at https://github.com/wenwenyu/DocThinker.
LLMs-guided adaptive compensator: Bringing Adaptivity to Automatic Control Systems with Large Language Models
Jul 28, 2025With rapid advances in code generation, reasoning, and problem-solving, Large Language Models (LLMs) are increasingly applied in robotics. Most existing work focuses on high-level tasks such as task decomposition. A few studies have explored the use of LLMs in feedback controller design; however, these efforts are restricted to overly simplified systems, fixed-structure gain tuning, and lack real-world validation. To further investigate LLMs in automatic control, this work targets a key subfield: adaptive control. Inspired by the framework of model reference adaptive control (MRAC), we propose an LLM-guided adaptive compensator framework that avoids designing controllers from scratch. Instead, the LLMs are prompted using the discrepancies between an unknown system and a reference system to design a compensator that aligns the response of the unknown system with that of the reference, thereby achieving adaptivity. Experiments evaluate five methods: LLM-guided adaptive compensator, LLM-guided adaptive controller, indirect adaptive control, learning-based adaptive control, and MRAC, on soft and humanoid robots in both simulated and real-world environments. Results show that the LLM-guided adaptive compensator outperforms traditional adaptive controllers and significantly reduces reasoning complexity compared to the LLM-guided adaptive controller. The Lyapunov-based analysis and reasoning-path inspection demonstrate that the LLM-guided adaptive compensator enables a more structured design process by transforming mathematical derivation into a reasoning task, while exhibiting strong generalizability, adaptability, and robustness. This study opens a new direction for applying LLMs in the field of automatic control, offering greater deployability and practicality compared to vision-language models.
Convergent and divergent connectivity patterns of the arcuate fasciculus in macaques and humans
Jun 24, 2025The organization and connectivity of the arcuate fasciculus (AF) in nonhuman primates remain contentious, especially concerning how its anatomy diverges from that of humans. Here, we combined cross-scale single-neuron tracing - using viral-based genetic labeling and fluorescence micro-optical sectioning tomography in macaques (n = 4; age 3 - 11 years) - with whole-brain tractography from 11.7T diffusion MRI. Complemented by spectral embedding analysis of 7.0T MRI in humans, we performed a comparative connectomic analysis of the AF across species. We demonstrate that the macaque AF originates in the temporal-parietal cortex, traverses the auditory cortex and parietal operculum, and projects into prefrontal regions. In contrast, the human AF exhibits greater expansion into the middle temporal gyrus and stronger prefrontal and parietal operculum connectivity - divergences quantified by Kullback-Leibler analysis that likely underpin the evolutionary specialization of human language networks. These interspecies differences - particularly the human AF's broader temporal integration and strengthened frontoparietal linkages - suggest a connectivity-based substrate for the emergence of advanced language processing unique to humans. Furthermore, our findings offer a neuroanatomical framework for understanding AF-related disorders such as aphasia and dyslexia, where aberrant connectivity disrupts language function.
OmniParser V2: Structured-Points-of-Thought for Unified Visual Text Parsing and Its Generality to Multimodal Large Language Models
Feb 22, 2025Visually-situated text parsing (VsTP) has recently seen notable advancements, driven by the growing demand for automated document understanding and the emergence of large language models capable of processing document-based questions. While various methods have been proposed to tackle the complexities of VsTP, existing solutions often rely on task-specific architectures and objectives for individual tasks. This leads to modal isolation and complex workflows due to the diversified targets and heterogeneous schemas. In this paper, we introduce OmniParser V2, a universal model that unifies VsTP typical tasks, including text spotting, key information extraction, table recognition, and layout analysis, into a unified framework. Central to our approach is the proposed Structured-Points-of-Thought (SPOT) prompting schemas, which improves model performance across diverse scenarios by leveraging a unified encoder-decoder architecture, objective, and input\&output representation. SPOT eliminates the need for task-specific architectures and loss functions, significantly simplifying the processing pipeline. Our extensive evaluations across four tasks on eight different datasets show that OmniParser V2 achieves state-of-the-art or competitive results in VsTP. Additionally, we explore the integration of SPOT within a multimodal large language model structure, further enhancing text localization and recognition capabilities, thereby confirming the generality of SPOT prompting technique. The code is available at \href{https://github.com/AlibabaResearch/AdvancedLiterateMachinery}{AdvancedLiterateMachinery}.
ClickTrack: Towards Real-time Interactive Single Object Tracking
Nov 24, 2024



Single object tracking(SOT) relies on precise object bounding box initialization. In this paper, we reconsidered the deficiencies in the current approaches to initializing single object trackers and propose a new paradigm for single object tracking algorithms, ClickTrack, a new paradigm using clicking interaction for real-time scenarios. Moreover, click as an input type inherently lack hierarchical information. To address ambiguity in certain special scenarios, we designed the Guided Click Refiner(GCR), which accepts point and optional textual information as inputs, transforming the point into the bounding box expected by the operator. The bounding box will be used as input of single object trackers. Experiments on LaSOT and GOT-10k benchmarks show that tracker combined with GCR achieves stable performance in real-time interactive scenarios. Furthermore, we explored the integration of GCR into the Segment Anything model(SAM), significantly reducing ambiguity issues when SAM receives point inputs.
Click; Single Object Tracking; Video Object Segmentation; Real-time Interaction
Nov 20, 2024Single object tracking(SOT) relies on precise object bounding box initialization. In this paper, we reconsidered the deficiencies in the current approaches to initializing single object trackers and propose a new paradigm for single object tracking algorithms, ClickTrack, a new paradigm using clicking interaction for real-time scenarios. Moreover, click as an input type inherently lack hierarchical information. To address ambiguity in certain special scenarios, we designed the Guided Click Refiner(GCR), which accepts point and optional textual information as inputs, transforming the point into the bounding box expected by the operator. The bounding box will be used as input of single object trackers. Experiments on LaSOT and GOT-10k benchmarks show that tracker combined with GCR achieves stable performance in real-time interactive scenarios. Furthermore, we explored the integration of GCR into the Segment Anything model(SAM), significantly reducing ambiguity issues when SAM receives point inputs.
OmniParser: A Unified Framework for Text Spotting, Key Information Extraction and Table Recognition
Mar 28, 2024Recently, visually-situated text parsing (VsTP) has experienced notable advancements, driven by the increasing demand for automated document understanding and the emergence of Generative Large Language Models (LLMs) capable of processing document-based questions. Various methods have been proposed to address the challenging problem of VsTP. However, due to the diversified targets and heterogeneous schemas, previous works usually design task-specific architectures and objectives for individual tasks, which inadvertently leads to modal isolation and complex workflow. In this paper, we propose a unified paradigm for parsing visually-situated text across diverse scenarios. Specifically, we devise a universal model, called OmniParser, which can simultaneously handle three typical visually-situated text parsing tasks: text spotting, key information extraction, and table recognition. In OmniParser, all tasks share the unified encoder-decoder architecture, the unified objective: point-conditioned text generation, and the unified input & output representation: prompt & structured sequences. Extensive experiments demonstrate that the proposed OmniParser achieves state-of-the-art (SOTA) or highly competitive performances on 7 datasets for the three visually-situated text parsing tasks, despite its unified, concise design. The code is available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery.
P2Seg: Pointly-supervised Segmentation via Mutual Distillation
Jan 18, 2024Point-level Supervised Instance Segmentation (PSIS) aims to enhance the applicability and scalability of instance segmentation by utilizing low-cost yet instance-informative annotations. Existing PSIS methods usually rely on positional information to distinguish objects, but predicting precise boundaries remains challenging due to the lack of contour annotations. Nevertheless, weakly supervised semantic segmentation methods are proficient in utilizing intra-class feature consistency to capture the boundary contours of the same semantic regions. In this paper, we design a Mutual Distillation Module (MDM) to leverage the complementary strengths of both instance position and semantic information and achieve accurate instance-level object perception. The MDM consists of Semantic to Instance (S2I) and Instance to Semantic (I2S). S2I is guided by the precise boundaries of semantic regions to learn the association between annotated points and instance contours. I2S leverages discriminative relationships between instances to facilitate the differentiation of various objects within the semantic map. Extensive experiments substantiate the efficacy of MDM in fostering the synergy between instance and semantic information, consequently improving the quality of instance-level object representations. Our method achieves 55.7 mAP$_{50}$ and 17.6 mAP on the PASCAL VOC and MS COCO datasets, significantly outperforming recent PSIS methods and several box-supervised instance segmentation competitors.
P2RBox: A Single Point is All You Need for Oriented Object Detection
Nov 22, 2023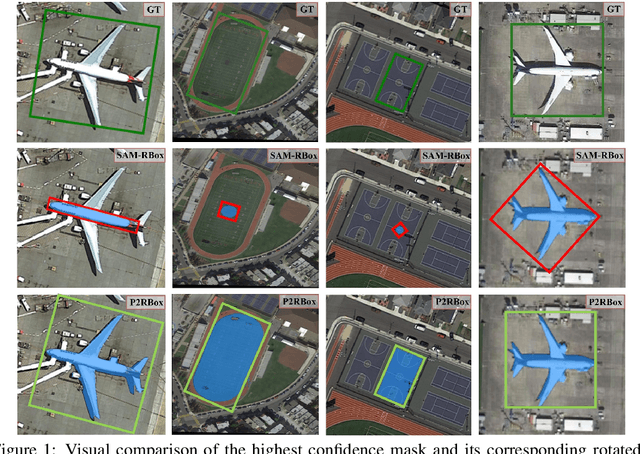
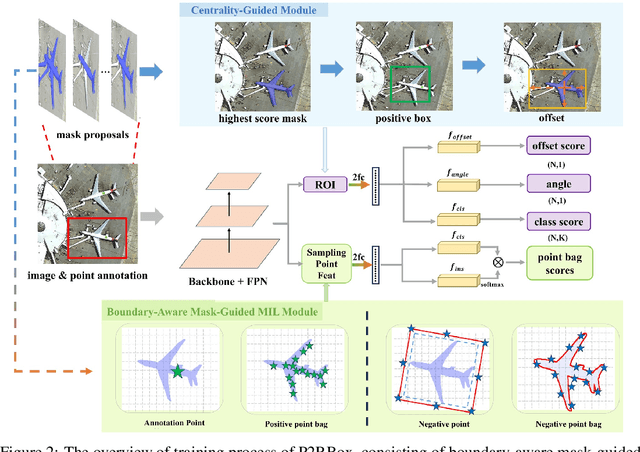
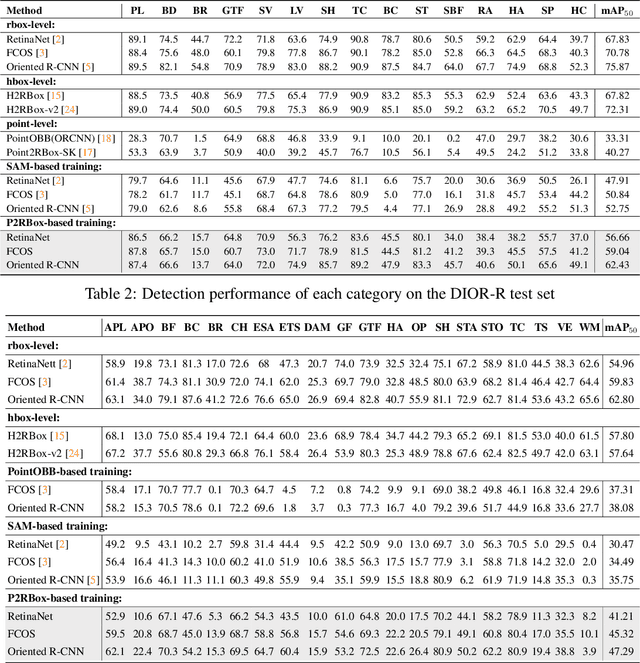
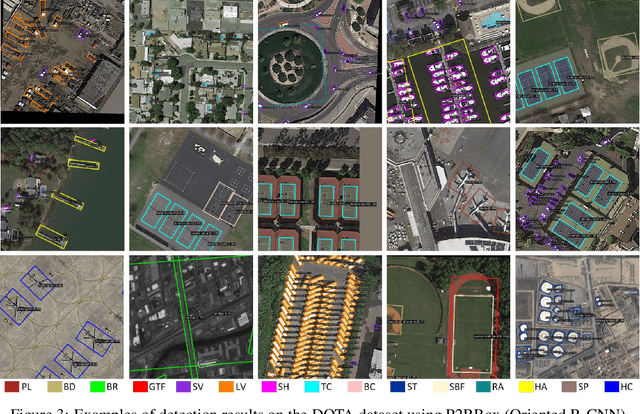
Oriented object detection, a specialized subfield in computer vision, finds applications across diverse scenarios, excelling particularly when dealing with objects of arbitrary orientations. Conversely, point annotation, which treats objects as single points, offers a cost-effective alternative to rotated and horizontal bounding boxes but sacrifices performance due to the loss of size and orientation information. In this study, we introduce the P2RBox network, which leverages point annotations and a mask generator to create mask proposals, followed by filtration through our Inspector Module and Constrainer Module. This process selects high-quality masks, which are subsequently converted into rotated box annotations for training a fully supervised detector. Specifically, we've thoughtfully crafted an Inspector Module rooted in multi-instance learning principles to evaluate the semantic score of masks. We've also proposed a more robust mask quality assessment in conjunction with the Constrainer Module. Furthermore, we've introduced a Symmetry Axis Estimation (SAE) Module inspired by the spectral theorem for symmetric matrices to transform the top-performing mask proposal into rotated bounding boxes. P2RBox performs well with three fully supervised rotated object detectors: RetinaNet, Rotated FCOS, and Oriented R-CNN. By combining with Oriented R-CNN, P2RBox achieves 62.26% on DOTA-v1.0 test dataset. As far as we know, this is the first attempt at training an oriented object detector with point supervision.
Turning a CLIP Model into a Scene Text Spotter
Aug 21, 2023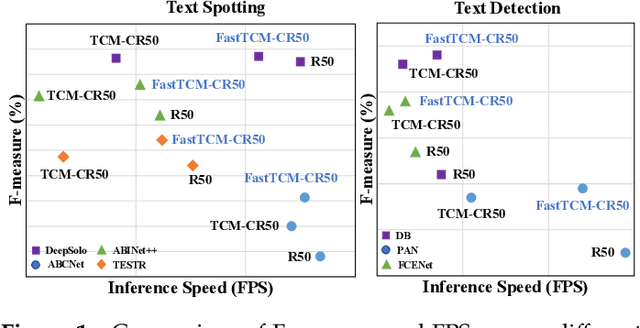
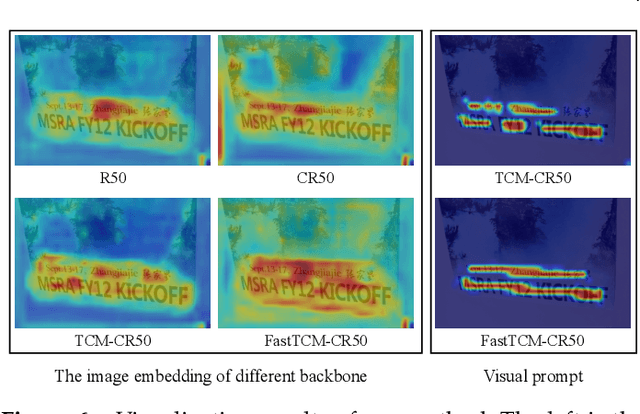
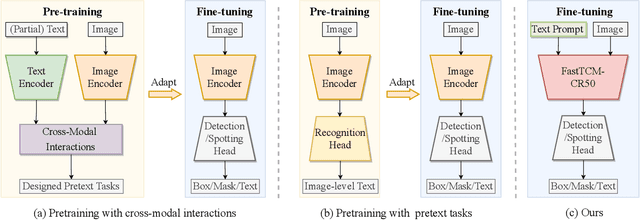
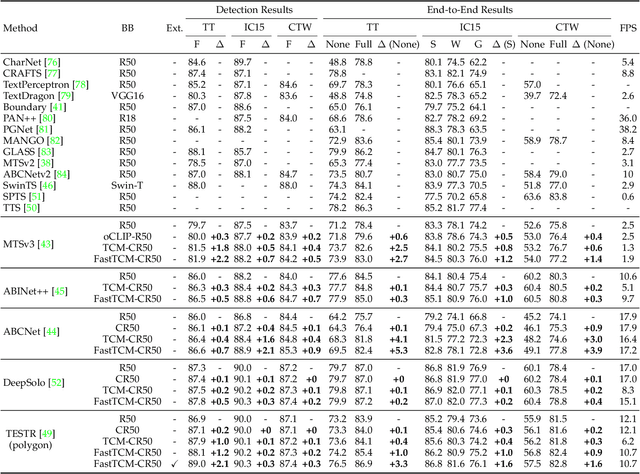
We exploit the potential of the large-scale Contrastive Language-Image Pretraining (CLIP) model to enhance scene text detection and spotting tasks, transforming it into a robust backbone, FastTCM-CR50. This backbone utilizes visual prompt learning and cross-attention in CLIP to extract image and text-based prior knowledge. Using predefined and learnable prompts, FastTCM-CR50 introduces an instance-language matching process to enhance the synergy between image and text embeddings, thereby refining text regions. Our Bimodal Similarity Matching (BSM) module facilitates dynamic language prompt generation, enabling offline computations and improving performance. FastTCM-CR50 offers several advantages: 1) It can enhance existing text detectors and spotters, improving performance by an average of 1.7% and 1.5%, respectively. 2) It outperforms the previous TCM-CR50 backbone, yielding an average improvement of 0.2% and 0.56% in text detection and spotting tasks, along with a 48.5% increase in inference speed. 3) It showcases robust few-shot training capabilities. Utilizing only 10% of the supervised data, FastTCM-CR50 improves performance by an average of 26.5% and 5.5% for text detection and spotting tasks, respectively. 4) It consistently enhances performance on out-of-distribution text detection and spotting datasets, particularly the NightTime-ArT subset from ICDAR2019-ArT and the DOTA dataset for oriented object detection. The code is available at https://github.com/wenwenyu/TCM.