 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning a CLIP Model into a Scene Text Spotter
Paper and Code
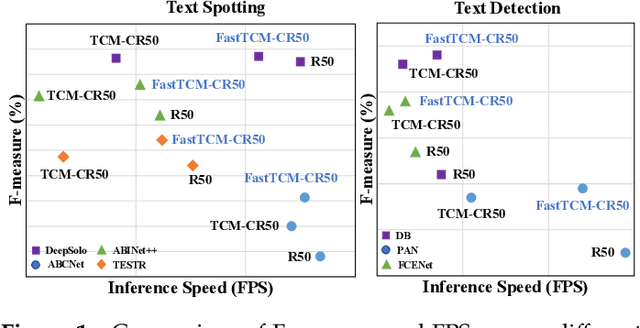
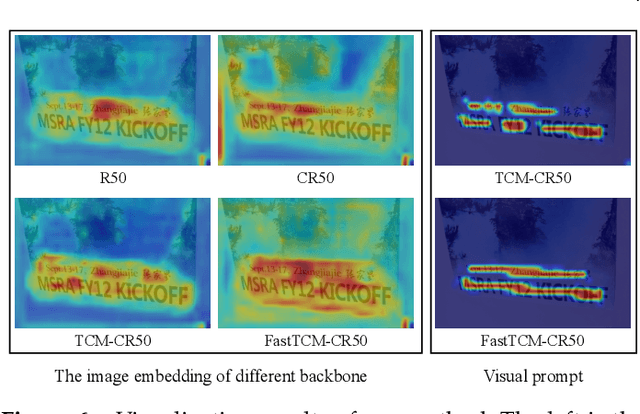
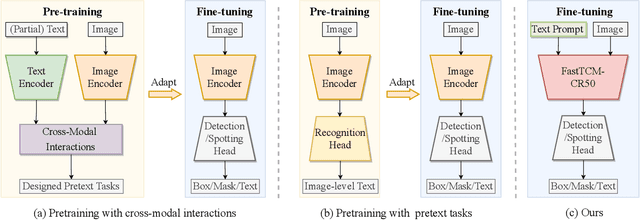
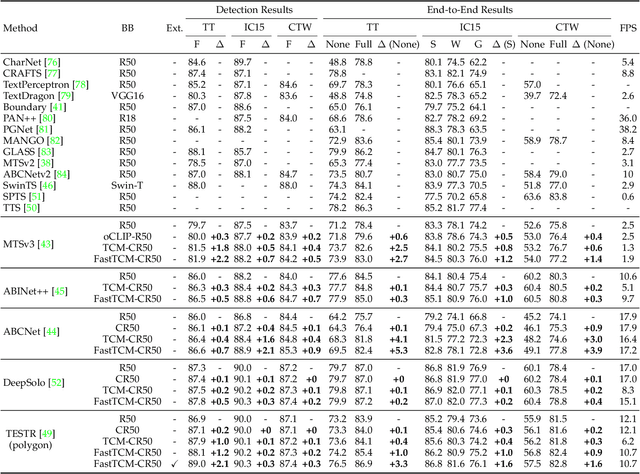
We exploit the potential of the large-scale Contrastive Language-Image Pretraining (CLIP) model to enhance scene text detection and spotting tasks, transforming it into a robust backbone, FastTCM-CR50. This backbone utilizes visual prompt learning and cross-attention in CLIP to extract image and text-based prior knowledge. Using predefined and learnable prompts, FastTCM-CR50 introduces an instance-language matching process to enhance the synergy between image and text embeddings, thereby refining text regions. Our Bimodal Similarity Matching (BSM) module facilitates dynamic language prompt generation, enabling offline computations and improving performance. FastTCM-CR50 offers several advantages: 1) It can enhance existing text detectors and spotters, improving performance by an average of 1.7% and 1.5%, respectively. 2) It outperforms the previous TCM-CR50 backbone, yielding an average improvement of 0.2% and 0.56% in text detection and spotting tasks, along with a 48.5% increase in inference speed. 3) It showcases robust few-shot training capabilities. Utilizing only 10% of the supervised data, FastTCM-CR50 improves performance by an average of 26.5% and 5.5% for text detection and spotting tasks, respectively. 4) It consistently enhances performance on out-of-distribution text detection and spotting datasets, particularly the NightTime-ArT subset from ICDAR2019-ArT and the DOTA dataset for oriented object detection. The code is available at https://github.com/wenwenyu/TCM.