 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE Jetpack: From Dense Checkpoints to Adaptive Mixture of Experts for Vision Tasks
Jun 07, 2024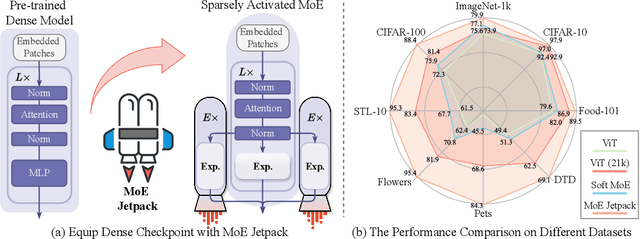
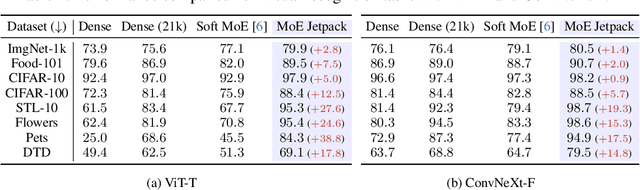
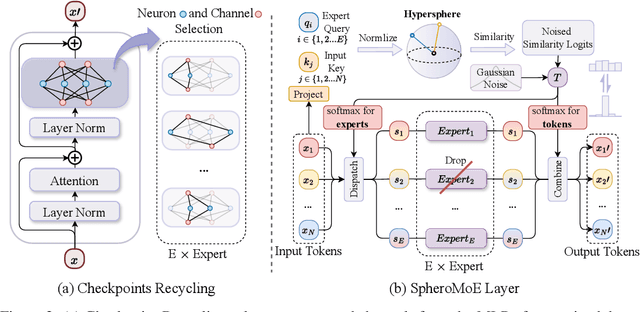

The sparsely activated mixture of experts (MoE) model presents a promising alternative to traditional densely activated (dense) models, enhancing both quality and computational efficiency. However, training MoE models from scratch demands extensive data and computational resources. Moreover, public repositories like timm mainly provide pre-trained dense checkpoints, lacking similar resources for MoE models, hindering their adoption. To bridge this gap, we introduce MoE Jetpack, an effective method for fine-tuning dense checkpoints into MoE models. MoE Jetpack incorporates two key techniques: (1) checkpoint recycling, which repurposes dense checkpoints as initial weights for MoE models, thereby accelerating convergence, enhancing accuracy, and alleviating the computational burden of pre-training; (2) hyperspherical adaptive MoE (SpheroMoE) layer, which optimizes the MoE architecture for better integration of dense checkpoints, enhancing fine-tuning performance. Our experiments on vision tasks demonstrate that MoE Jetpack significantly improves convergence speed and accuracy when fine-tuning dense checkpoints into MoE models. Our code will be publicly available at https://github.com/Adlith/MoE-Jetpack.
Dynamic Adapter Meets Prompt Tuning: Parameter-Efficient Transfer Learning for Point Cloud Analysis
Mar 03, 2024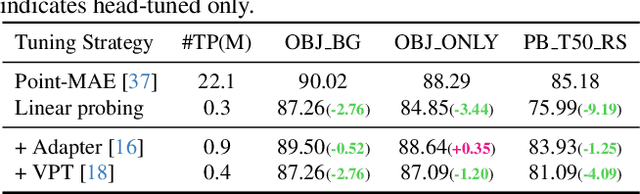
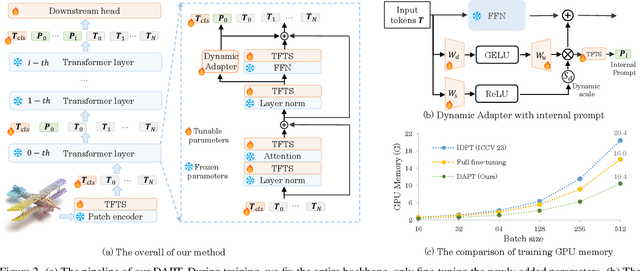
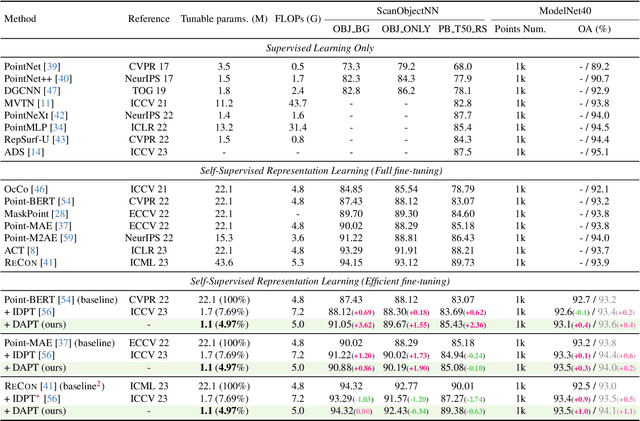
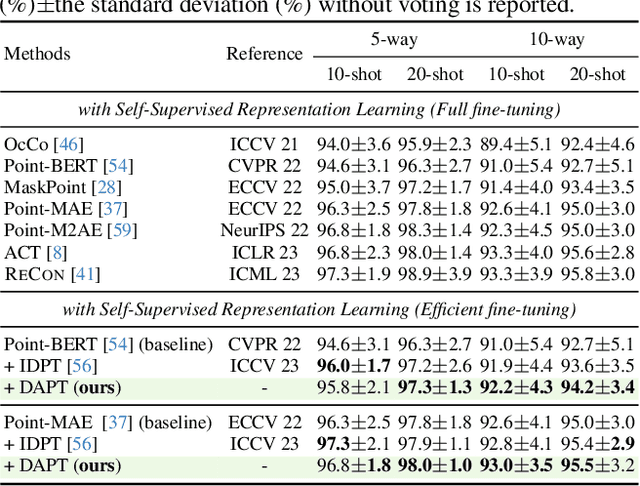
Point cloud analysis has achieved outstanding performance by transferring point cloud pre-trained models. However, existing methods for model adaptation usually update all model parameters, i.e., full fine-tuning paradigm, which is inefficient as it relies on high computational costs (e.g., training GPU memory) and massive storage space. In this paper, we aim to study parameter-efficient transfer learning for point cloud analysis with an ideal trade-off between task performance and parameter efficiency. To achieve this goal, we freeze the parameters of the default pre-trained models and then propose the Dynamic Adapter, which generates a dynamic scale for each token, considering the token significance to the downstream task. We further seamlessly integrate Dynamic Adapter with Prompt Tuning (DAPT) by constructing Internal Prompts, capturing the instance-specific features for interaction. Extensive experiments conducted on five challenging datasets demonstrate that the proposed DAPT achieves superior performance compared to the full fine-tuning counterparts while significantly reducing the trainable parameters and training GPU memory by 95% and 35%, respectively. Code is available at https://github.com/LMD0311/DAPT.
PointMamba: A Simple State Space Model for Point Cloud Analysis
Feb 19, 2024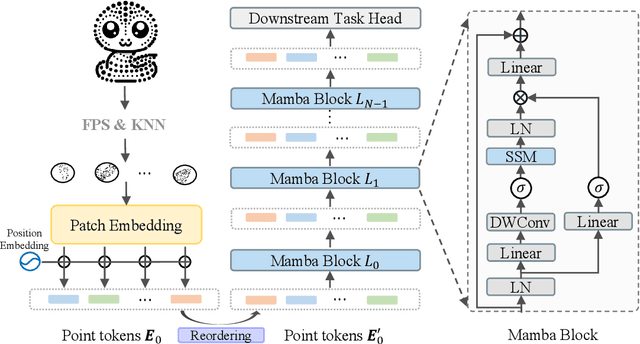
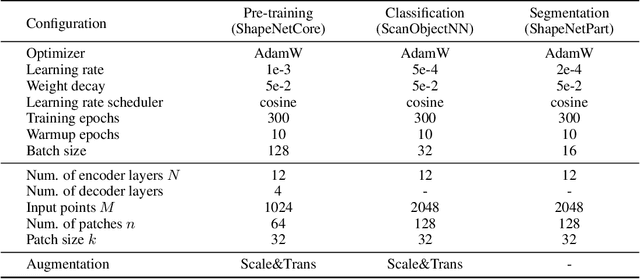
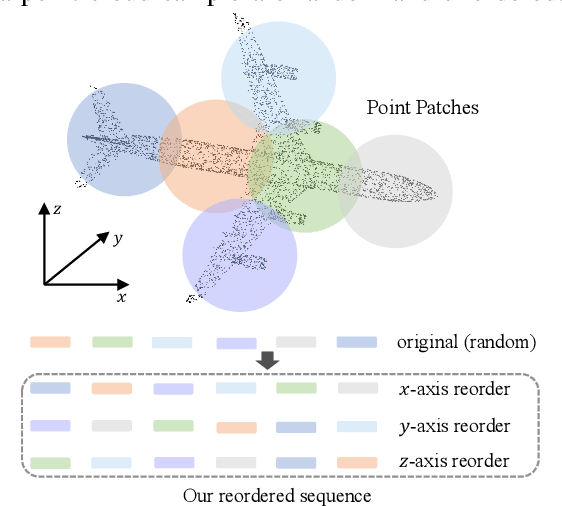
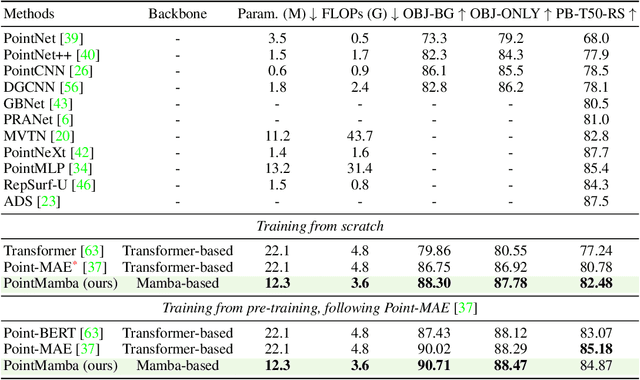
Transformers have become one of the foundational architectures in point cloud analysis tasks due to their excellent global modeling ability. However, the attention mechanism has quadratic complexity and is difficult to extend to long sequence modeling due to limited computational resources and so on. Recently, state space models (SSM), a new family of deep sequence models, have presented great potential for sequence modeling in NLP tasks. In this paper, taking inspiration from the success of SSM in NLP, we propose PointMamba, a framework with global modeling and linear complexity. Specifically, by taking embedded point patches as input, we proposed a reordering strategy to enhance SSM's global modeling ability by providing a more logical geometric scanning order. The reordered point tokens are then sent to a series of Mamba blocks to causally capture the point cloud structure. Experimental results show our proposed PointMamba outperforms the transformer-based counterparts on different point cloud analysis datasets, while significantly saving about 44.3% parameters and 25% FLOPs, demonstrating the potential option for constructing foundational 3D vision models. We hope our PointMamba can provide a new perspective for point cloud analysis. The code is available at https://github.com/LMD0311/PointMamba.
Turning a CLIP Model into a Scene Text Spotter
Aug 21, 2023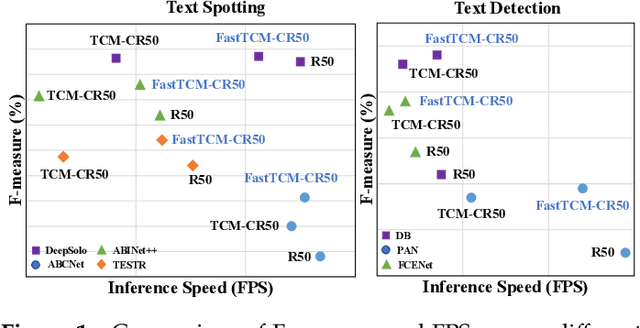
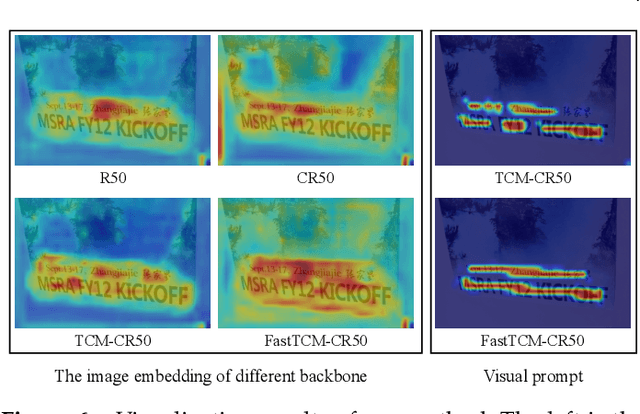
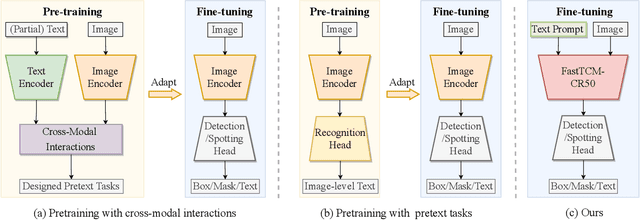
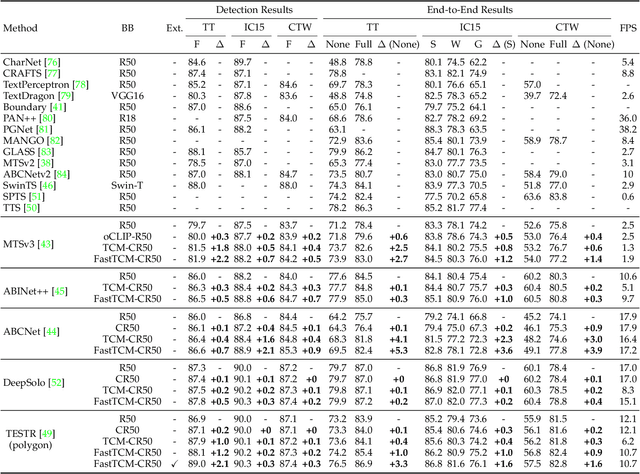
We exploit the potential of the large-scale Contrastive Language-Image Pretraining (CLIP) model to enhance scene text detection and spotting tasks, transforming it into a robust backbone, FastTCM-CR50. This backbone utilizes visual prompt learning and cross-attention in CLIP to extract image and text-based prior knowledge. Using predefined and learnable prompts, FastTCM-CR50 introduces an instance-language matching process to enhance the synergy between image and text embeddings, thereby refining text regions. Our Bimodal Similarity Matching (BSM) module facilitates dynamic language prompt generation, enabling offline computations and improving performance. FastTCM-CR50 offers several advantages: 1) It can enhance existing text detectors and spotters, improving performance by an average of 1.7% and 1.5%, respectively. 2) It outperforms the previous TCM-CR50 backbone, yielding an average improvement of 0.2% and 0.56% in text detection and spotting tasks, along with a 48.5% increase in inference speed. 3) It showcases robust few-shot training capabilities. Utilizing only 10% of the supervised data, FastTCM-CR50 improves performance by an average of 26.5% and 5.5% for text detection and spotting tasks, respectively. 4) It consistently enhances performance on out-of-distribution text detection and spotting datasets, particularly the NightTime-ArT subset from ICDAR2019-ArT and the DOTA dataset for oriented object detection. The code is available at https://github.com/wenwenyu/TCM.
TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios
Aug 26, 2021
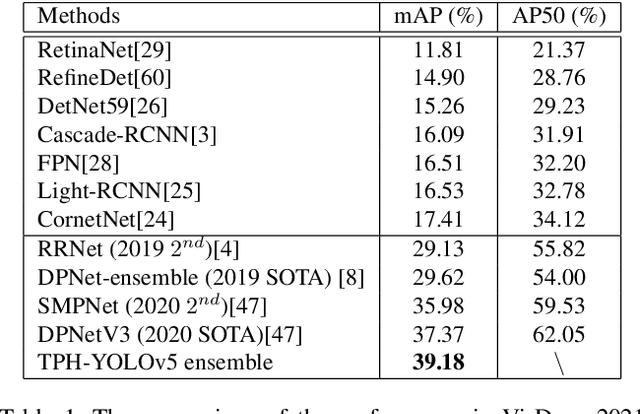
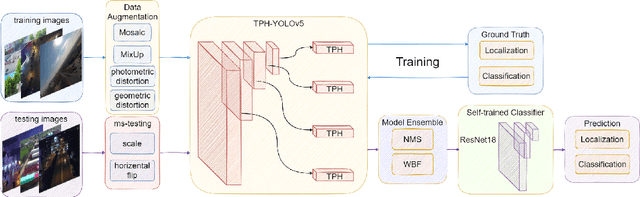

Object detection on drone-captured scenarios is a recent popular task. As drones always navigate in different altitudes, the object scale varies violently, which burdens the optimization of networks. Moreover, high-speed and low-altitude flight bring in the motion blur on the densely packed objects, which leads to great challenge of object distinction. To solve the two issues mentioned above, we propose TPH-YOLOv5. Based on YOLOv5, we add one more prediction head to detect different-scale objects. Then we replace the original prediction heads with Transformer Prediction Heads (TPH) to explore the prediction potential with self-attention mechanism. We also integrate convolutional block attention model (CBAM) to find attention region on scenarios with dense objects. To achieve more improvement of our proposed TPH-YOLOv5, we provide bags of useful strategies such as data augmentation, multiscale testing, multi-model integration and utilizing extra classifier. Extensive experiments on dataset VisDrone2021 show that TPH-YOLOv5 have good performance with impressive interpretability on drone-captured scenarios. On DET-test-challenge dataset, the AP result of TPH-YOLOv5 are 39.18%, which is better than previous SOTA method (DPNetV3) by 1.81%. On VisDrone Challenge 2021, TPHYOLOv5 wins 5th place and achieves well-matched results with 1st place model (AP 39.43%). Compared to baseline model (YOLOv5), TPH-YOLOv5 improves about 7%, which is encouraging and competitive.