 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuffle-R1: Efficient RL framework for Multimodal Large Language Models via Data-centric Dynamic Shuffle
Aug 07, 2025Reinforcement learning (RL) has emerged as an effective post-training paradigm for enhancing the reasoning capabilities of multimodal large language model (MLLM). However, current RL pipelines often suffer from training inefficiencies caused by two underexplored issues: Advantage Collapsing, where most advantages in a batch concentrate near zero, and Rollout Silencing, where the proportion of rollouts contributing non-zero gradients diminishes over time. These issues lead to suboptimal gradient updates and hinder long-term learning efficiency. To address these issues, we propose Shuffle-R1, a simple yet principled framework that improves RL fine-tuning efficiency by dynamically restructuring trajectory sampling and batch composition. It introduces (1) Pairwise Trajectory Sampling, which selects high-contrast trajectories with large advantages to improve gradient signal quality, and (2) Advantage-based Trajectory Shuffle, which increases exposure of valuable rollouts through informed batch reshuffling. Experiments across multiple reasoning benchmarks show that our framework consistently outperforms strong RL baselines with minimal overhead. These results highlight the importance of data-centric adaptations for more efficient RL training in MLLM.
MoE Jetpack: From Dense Checkpoints to Adaptive Mixture of Experts for Vision Tasks
Jun 07, 2024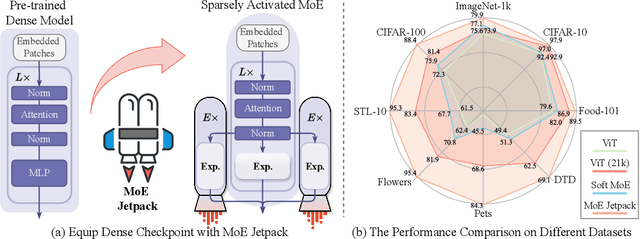
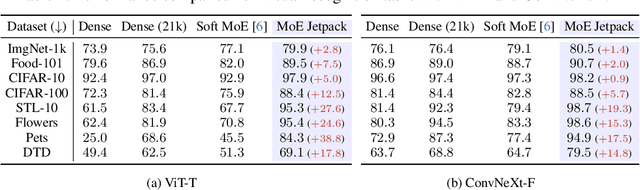
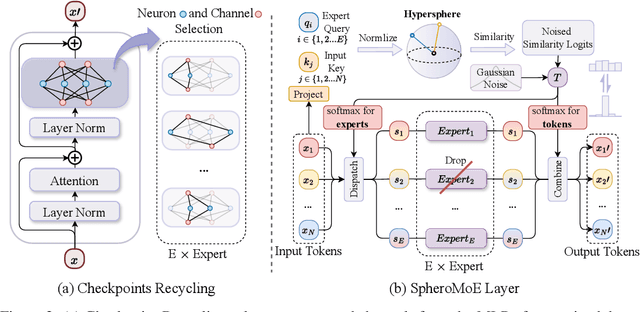

The sparsely activated mixture of experts (MoE) model presents a promising alternative to traditional densely activated (dense) models, enhancing both quality and computational efficiency. However, training MoE models from scratch demands extensive data and computational resources. Moreover, public repositories like timm mainly provide pre-trained dense checkpoints, lacking similar resources for MoE models, hindering their adoption. To bridge this gap, we introduce MoE Jetpack, an effective method for fine-tuning dense checkpoints into MoE models. MoE Jetpack incorporates two key techniques: (1) checkpoint recycling, which repurposes dense checkpoints as initial weights for MoE models, thereby accelerating convergence, enhancing accuracy, and alleviating the computational burden of pre-training; (2) hyperspherical adaptive MoE (SpheroMoE) layer, which optimizes the MoE architecture for better integration of dense checkpoints, enhancing fine-tuning performance. Our experiments on vision tasks demonstrate that MoE Jetpack significantly improves convergence speed and accuracy when fine-tuning dense checkpoints into MoE models. Our code will be publicly available at https://github.com/Adlith/MoE-Jetpack.
End-to-end Video Gaze Estimation via Capturing Head-face-eye Spatial-temporal Interaction Context
Nov 01, 2023In this letter, we propose a new method, Multi-Clue Gaze (MCGaze), to facilitate video gaze estimation via capturing spatial-temporal interaction context among head, face, and eye in an end-to-end learning way, which has not been well concerned yet. The main advantage of MCGaze is that the tasks of clue localization of head, face, and eye can be solved jointly for gaze estimation in a one-step way, with joint optimization to seek optimal performance. During this, spatial-temporal context exchange happens among the clues on the head, face, and eye. Accordingly, the final gazes obtained by fusing features from various queries can be aware of global clues from heads and faces, and local clues from eyes simultaneously, which essentially leverages performance. Meanwhile, the one-step running way also ensures high running efficiency. Experiments on the challenging Gaze360 dataset verify the superiority of our proposition. The source code will be released at https://github.com/zgchen33/MCGaze.