 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Learning for Temporally Grounded Video-Language Models
Dec 30, 2025Recent video-language models have shown great potential for video understanding, but still struggle with accurate temporal grounding for event-level perception. We observe that two main factors in video understanding (i.e., temporal grounding and textual response) form a logical hierarchy: accurate temporal evidence grounding lays the foundation for reliable textual response. However, existing works typically handle these two tasks in a coupled manner without a clear logical structure, leading to sub-optimal objectives. We address this from a factorized learning perspective. We first propose D$^2$VLM, a framework that decouples the learning of these two tasks while also emphasizing their inherent dependency. We adopt a "grounding then answering with evidence referencing" paradigm and introduce evidence tokens for evidence grounding, which emphasize event-level visual semantic capture beyond the focus on timestamp representation in existing works. To further facilitate the learning of these two tasks, we introduce a novel factorized preference optimization (FPO) algorithm. Unlike standard preference optimization, FPO explicitly incorporates probabilistic temporal grounding modeling into the optimization objective, enabling preference learning for both temporal grounding and textual response. We also construct a synthetic dataset to address the lack of suitable datasets for factorized preference learning with explicit temporal grounding. Experiments on various tasks demonstrate the clear advantage of our approach. Our source code is available at https://github.com/nusnlp/d2vlm.
SlideTailor: Personalized Presentation Slide Generation for Scientific Papers
Dec 23, 2025Automatic presentation slide generation can greatly streamline content creation. However, since preferences of each user may vary, existing under-specified formulations often lead to suboptimal results that fail to align with individual user needs. We introduce a novel task that conditions paper-to-slides generation on user-specified preferences. We propose a human behavior-inspired agentic framework, SlideTailor, that progressively generates editable slides in a user-aligned manner. Instead of requiring users to write their preferences in detailed textual form, our system only asks for a paper-slides example pair and a visual template - natural and easy-to-provide artifacts that implicitly encode rich user preferences across content and visual style. Despite the implicit and unlabeled nature of these inputs, our framework effectively distills and generalizes the preferences to guide customized slide generation. We also introduce a novel chain-of-speech mechanism to align slide content with planned oral narration. Such a design significantly enhances the quality of generated slides and enables downstream applications like video presentations. To support this new task, we construct a benchmark dataset that captures diverse user preferences, with carefully designed interpretable metrics for robust evaluation. Extensive experiments demonstrate the effectiveness of our framework.
MP-Mat: A 3D-and-Instance-Aware Human Matting and Editing Framework with Multiplane Representation
Apr 20, 2025

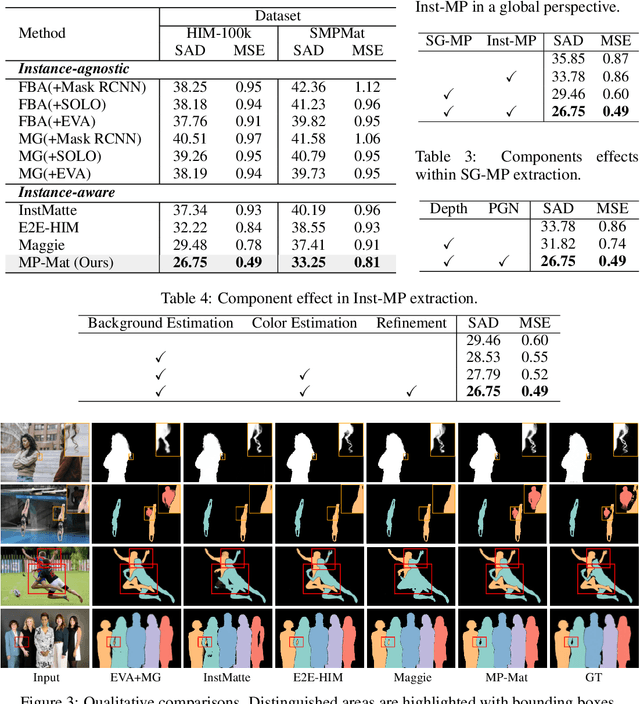

Human instance matting aims to estimate an alpha matte for each human instance in an image, which is challenging as it easily fails in complex cases requiring disentangling mingled pixels belonging to multiple instances along hairy and thin boundary structures. In this work, we address this by introducing MP-Mat, a novel 3D-and-instance-aware matting framework with multiplane representation, where the multiplane concept is designed from two different perspectives: scene geometry level and instance level. Specifically, we first build feature-level multiplane representations to split the scene into multiple planes based on depth differences. This approach makes the scene representation 3D-aware, and can serve as an effective clue for splitting instances in different 3D positions, thereby improving interpretability and boundary handling ability especially in occlusion areas. Then, we introduce another multiplane representation that splits the scene in an instance-level perspective, and represents each instance with both matte and color. We also treat background as a special instance, which is often overlooked by existing methods. Such an instance-level representation facilitates both foreground and background content awareness, and is useful for other down-stream tasks like image editing. Once built, the representation can be reused to realize controllable instance-level image editing with high efficiency. Extensive experiments validate the clear advantage of MP-Mat in matting task. We also demonstrate its superiority in image editing tasks, an area under-explored by existing matting-focused methods, where our approach under zero-shot inference even outperforms trained specialized image editing techniques by large margins. Code is open-sourced at https://github.com/JiaoSiyi/MPMat.git}.
DFIMat: Decoupled Flexible Interactive Matting in Multi-Person Scenarios
Oct 13, 2024Interactive portrait matting refers to extracting the soft portrait from a given image that best meets the user's intent through their inputs. Existing methods often underperform in complex scenarios, mainly due to three factors. (1) Most works apply a tightly coupled network that directly predicts matting results, lacking interpretability and resulting in inadequate modeling. (2) Existing works are limited to a single type of user input, which is ineffective for intention understanding and also inefficient for user operation. (3) The multi-round characteristics have been under-explored, which is crucial for user interaction. To alleviate these limitations, we propose DFIMat, a decoupled framework that enables flexible interactive matting. Specifically, we first decouple the task into 2 sub-ones: localizing target instances by understanding scene semantics and the flexible user inputs, and conducting refinement for instance-level matting. We observe a clear performance gain from decoupling, as it makes sub-tasks easier to learn, and the flexible multi-type input further enhances both effectiveness and efficiency. DFIMat also considers the multi-round interaction property, where a contrastive reasoning module is designed to enhance cross-round refinement. Another limitation for multi-person matting task is the lack of training data. We address this by introducing a new synthetic data generation pipeline that can generate much more realistic samples than previous arts. A new large-scale dataset SMPMat is subsequently established. Experiments verify the significant superiority of DFIMat. With it, we also investigate the roles of different input types, providing valuable principles for users. Our code and dataset can be found at https://github.com/JiaoSiyi/DFIMat.
CrossGLG: LLM Guides One-shot Skeleton-based 3D Action Recognition in a Cross-level Manner
Mar 15, 2024
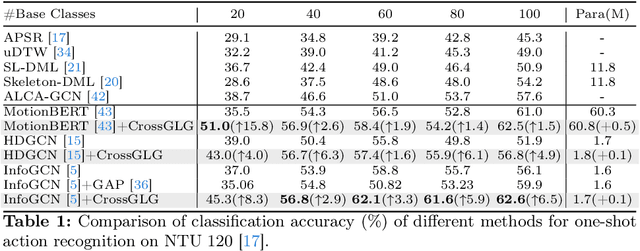
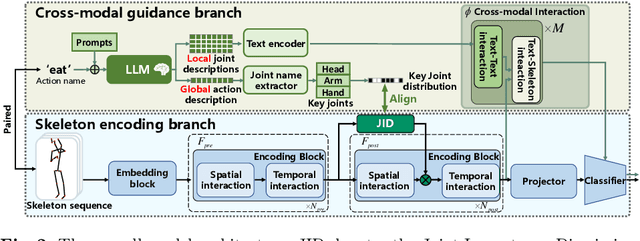
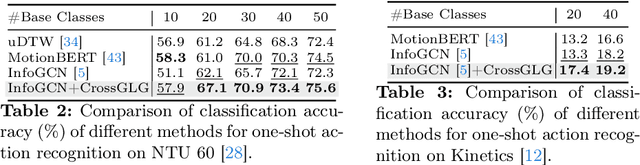
Most existing one-shot skeleton-based action recognition focuses on raw low-level information (e.g., joint location), and may suffer from local information loss and low generalization ability. To alleviate these, we propose to leverage text description generated from large language models (LLM) that contain high-level human knowledge, to guide feature learning, in a global-local-global way. Particularly, during training, we design $2$ prompts to gain global and local text descriptions of each action from an LLM. We first utilize the global text description to guide the skeleton encoder focus on informative joints (i.e.,global-to-local). Then we build non-local interaction between local text and joint features, to form the final global representation (i.e., local-to-global). To mitigate the asymmetry issue between the training and inference phases, we further design a dual-branch architecture that allows the model to perform novel class inference without any text input, also making the additional inference cost neglectable compared with the base skeleton encoder. Extensive experiments on three different benchmarks show that CrossGLG consistently outperforms the existing SOTA methods with large margins, and the inference cost (model size) is only $2.8$\% than the previous SOTA. CrossGLG can also serve as a plug-and-play module that can substantially enhance the performance of different SOTA skeleton encoders with a neglectable cost during inference. The source code will be released soon.
End-to-end Video Gaze Estimation via Capturing Head-face-eye Spatial-temporal Interaction Context
Nov 01, 2023



In this letter, we propose a new method, Multi-Clue Gaze (MCGaze), to facilitate video gaze estimation via capturing spatial-temporal interaction context among head, face, and eye in an end-to-end learning way, which has not been well concerned yet. The main advantage of MCGaze is that the tasks of clue localization of head, face, and eye can be solved jointly for gaze estimation in a one-step way, with joint optimization to seek optimal performance. During this, spatial-temporal context exchange happens among the clues on the head, face, and eye. Accordingly, the final gazes obtained by fusing features from various queries can be aware of global clues from heads and faces, and local clues from eyes simultaneously, which essentially leverages performance. Meanwhile, the one-step running way also ensures high running efficiency. Experiments on the challenging Gaze360 dataset verify the superiority of our proposition. The source code will be released at https://github.com/zgchen33/MCGaze.
Real-time Multi-person Eyeblink Detection in the Wild for Untrimmed Video
Mar 28, 2023Real-time eyeblink detection in the wild can widely serve for fatigue detection, face anti-spoofing, emotion analysis, etc. The existing research efforts generally focus on single-person cases towards trimmed video. However, multi-person scenario within untrimmed videos is also important for practical applications, which has not been well concerned yet. To address this, we shed light on this research field for the first time with essential contributions on dataset, theory, and practices. In particular, a large-scale dataset termed MPEblink that involves 686 untrimmed videos with 8748 eyeblink events is proposed under multi-person conditions. The samples are captured from unconstrained films to reveal "in the wild" characteristics. Meanwhile, a real-time multi-person eyeblink detection method is also proposed. Being different from the existing counterparts, our proposition runs in a one-stage spatio-temporal way with end-to-end learning capacity. Specifically, it simultaneously addresses the sub-tasks of face detection, face tracking, and human instance-level eyeblink detection. This paradigm holds 2 main advantages: (1) eyeblink features can be facilitated via the face's global context (e.g., head pose and illumination condition) with joint optimization and interaction, and (2) addressing these sub-tasks in parallel instead of sequential manner can save time remarkably to meet the real-time running requirement. Experiments on MPEblink verify the essential challenges of real-time multi-person eyeblink detection in the wild for untrimmed video. Our method also outperforms existing approaches by large margins and with a high inference speed.