 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMP-Mat: A 3D-and-Instance-Aware Human Matting and Editing Framework with Multiplane Representation
Apr 20, 2025

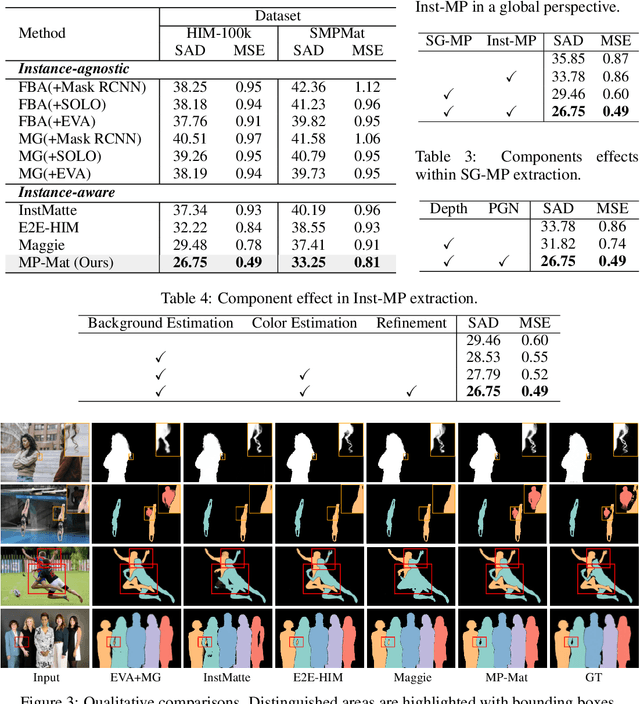

Human instance matting aims to estimate an alpha matte for each human instance in an image, which is challenging as it easily fails in complex cases requiring disentangling mingled pixels belonging to multiple instances along hairy and thin boundary structures. In this work, we address this by introducing MP-Mat, a novel 3D-and-instance-aware matting framework with multiplane representation, where the multiplane concept is designed from two different perspectives: scene geometry level and instance level. Specifically, we first build feature-level multiplane representations to split the scene into multiple planes based on depth differences. This approach makes the scene representation 3D-aware, and can serve as an effective clue for splitting instances in different 3D positions, thereby improving interpretability and boundary handling ability especially in occlusion areas. Then, we introduce another multiplane representation that splits the scene in an instance-level perspective, and represents each instance with both matte and color. We also treat background as a special instance, which is often overlooked by existing methods. Such an instance-level representation facilitates both foreground and background content awareness, and is useful for other down-stream tasks like image editing. Once built, the representation can be reused to realize controllable instance-level image editing with high efficiency. Extensive experiments validate the clear advantage of MP-Mat in matting task. We also demonstrate its superiority in image editing tasks, an area under-explored by existing matting-focused methods, where our approach under zero-shot inference even outperforms trained specialized image editing techniques by large margins. Code is open-sourced at https://github.com/JiaoSiyi/MPMat.git}.
VicSim: Enhancing Victim Simulation with Emotional and Linguistic Fidelity
Jan 06, 2025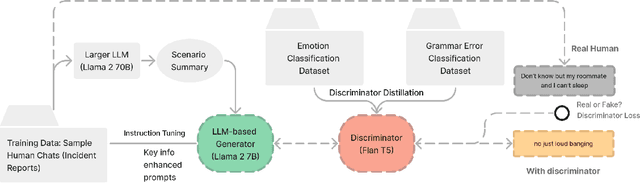



Scenario-based training has been widely adopted in many public service sectors. Recent advancements in Large Language Models (LLMs) have shown promise in simulating diverse personas to create these training scenarios. However, little is known about how LLMs can be developed to simulate victims for scenario-based training purposes. In this paper, we introduce VicSim (victim simulator), a novel model that addresses three key dimensions of user simulation: informational faithfulness, emotional dynamics, and language style (e.g., grammar usage). We pioneer the integration of scenario-based victim modeling with GAN-based training workflow and key-information-based prompting, aiming to enhance the realism of simulated victims. Our adversarial training approach teaches the discriminator to recognize grammar and emotional cues as reliable indicators of synthetic content. According to evaluations by human raters, the VicSim model outperforms GPT-4 in terms of human-likeness.
Advancing Relation Extraction through Language Probing with Exemplars from Set Co-Expansion
Aug 18, 2023Relation Extraction (RE) is a pivotal task in automatically extracting structured information from unstructured text. In this paper, we present a multi-faceted approach that integrates representative examples and through co-set expansion. The primary goal of our method is to enhance relation classification accuracy and mitigating confusion between contrastive classes. Our approach begins by seeding each relationship class with representative examples. Subsequently, our co-set expansion algorithm enriches training objectives by incorporating similarity measures between target pairs and representative pairs from the target class. Moreover, the co-set expansion process involves a class ranking procedure that takes into account exemplars from contrastive classes. Contextual details encompassing relation mentions are harnessed via context-free Hearst patterns to ascertain contextual similarity. Empirical evaluation demonstrates the efficacy of our co-set expansion approach, resulting in a significant enhancement of relation classification performance. Our method achieves an observed margin of at least 1 percent improvement in accuracy in most settings, on top of existing fine-tuning approaches. To further refine our approach, we conduct an in-depth analysis that focuses on tuning contrastive examples. This strategic selection and tuning effectively reduce confusion between classes sharing similarities, leading to a more precise classification process. Experimental results underscore the effectiveness of our proposed framework for relation extraction. The synergy between co-set expansion and context-aware prompt tuning substantially contributes to improved classification accuracy. Furthermore, the reduction in confusion between contrastive classes through contrastive examples tuning validates the robustness and reliability of our method.